School-Math-R1-Distil-Chinese-220K
收藏Hugging Face2025-05-02 更新2025-05-03 收录
下载链接:
https://huggingface.co/datasets/Mxode/School-Math-R1-Distil-Chinese-220K
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于文本生成的中文数据集,数据规模介于100K到1M之间。数据集由从BelleGroup的school_math_0.25M数据集中提取的指令和合成的回复组成,每条数据包括提示词、模型思考过程和模型最终回复。但请注意,该数据集存在两个已知缺陷:问题可能无法保证可解性,且答案未经验证。
This is a Chinese dataset for text generation, with a size ranging from 100K to 1M. The dataset is composed of instructions extracted from BelleGroup's school_math_0.25M dataset and synthesized responses. Each entry contains a prompt, the model's thinking process, and the model's final reply. However, this dataset has two known limitations: the solvability of the included problems cannot be guaranteed, and the provided answers have not been verified.
创建时间:
2025-04-20
原始信息汇总
数据集概述
基本信息
- 名称: School-Math-R1-Distil-Chinese-220K
- 许可证: CC-BY-SA-4.0
- 任务类别: 文本生成
- 语言: 中文
- 数据规模: 100K<n<1M
数据来源
- 原始数据集: BelleGroup/school_math_0.25M
- 处理方式: 从原数据集提取指令并重新合成回复
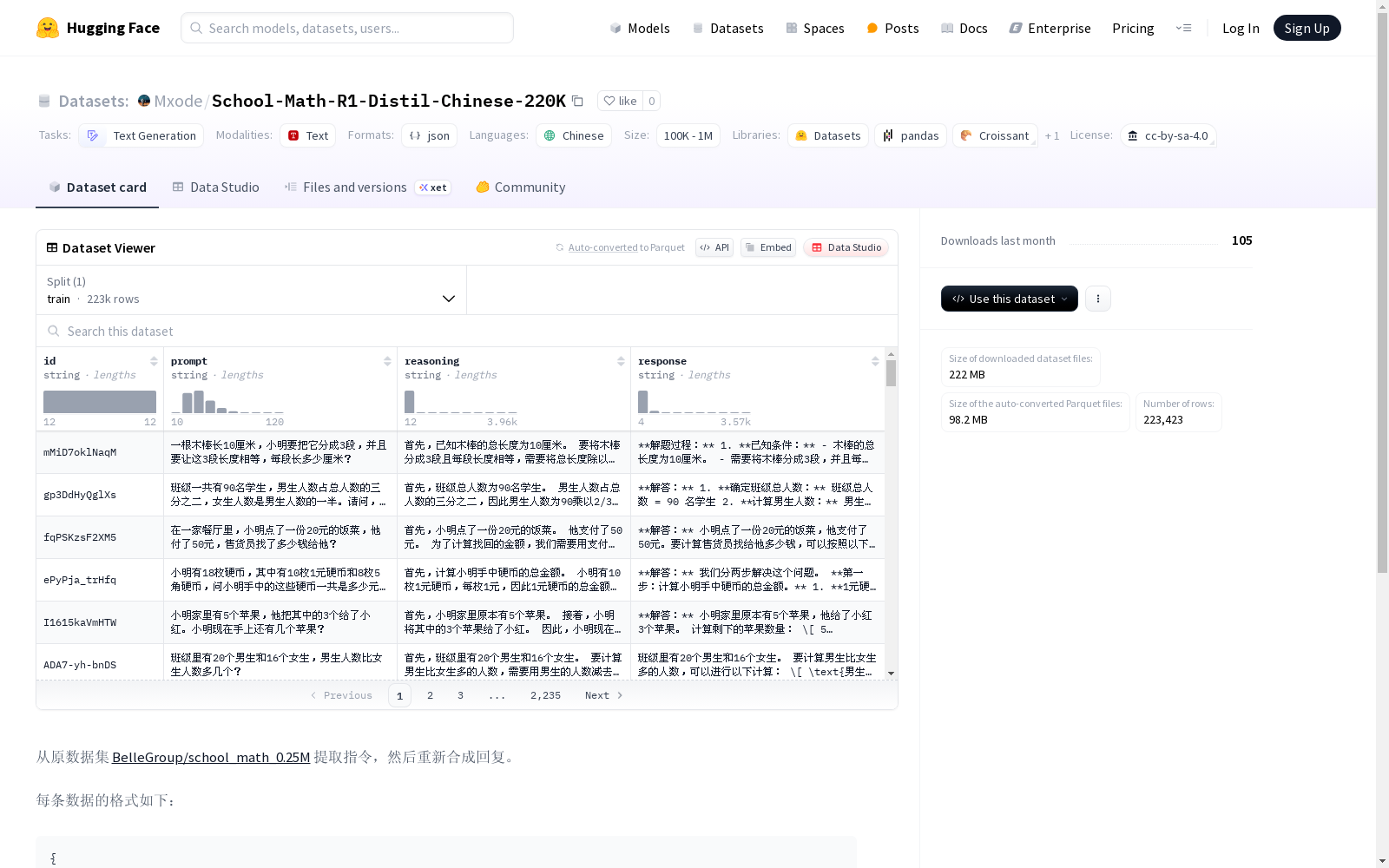
数据结构
每条数据包含以下字段: json { "id": "<<12位nanoid>>", "prompt": "<<提示词>>", "reasoning": "<<模型思考过程>>", "response": "<<模型最终回复>>" }
已知缺陷
- 问题可解性无法保证: 由于原数据集为纯合成数据集且未经过校验,尽管已尽力筛选过滤,仍无法保证余下数据的指令正确性和可解性。
- 答案未经过校验: 所有回答均为合成且未经过校验。
搜集汇总
数据集介绍
构建方式
在数学教育领域,高质量的指令数据集对提升语言模型的逻辑推理能力至关重要。School-Math-R1-Distil-Chinese-220K数据集基于BelleGroup原始数学问题语料进行深度重构,通过自动化流程提取有效指令后,采用先进的语言模型重新生成包含思考链路的响应。每条数据记录采用标准化JSON结构,完整保留了提示词、推理过程和最终答案的三级知识表示,构建过程中虽实施初步筛选机制,但仍继承原始合成数据固有的未验证特性。
特点
该数据集最显著的特征在于其22万条中文数学问题的规模优势,每条数据均包含模型解题的完整思维链路,为研究复杂推理过程提供珍贵素材。数据采用四段式结构化存储,其中'reasoning'字段特别呈现大语言模型的中间推导步骤,这种细粒度标注方式在数学教育领域具有创新价值。需要特别说明的是,由于数据完全由模型合成且未经人工核验,其问题可解性与答案准确性存在固有局限。
使用方法
研究人员可将本数据集作为数学推理任务的基准测试集,通过分析模型在'reasoning'字段展现的思维过程,深入探究语言模型的逻辑缺陷。使用时应建立双重验证机制:既可利用提示词字段评估模型的问题理解能力,也可对照推理步骤与最终答案检验一致性。鉴于数据未经人工校验,建议配合人工评估或与其他验证集结合使用,同时注意结果分析时需考虑合成数据带来的偏差影响。
背景与挑战
背景概述
School-Math-R1-Distil-Chinese-220K数据集由BelleGroup基于其早期发布的school_math_0.25M数据集构建而成,专注于中文数学问题的文本生成任务。该数据集通过指令提取与回复重构,旨在为大型语言模型提供高质量的数学推理训练数据。作为纯合成数据集,其核心价值在于通过标准化的问题-推理-回答三元组结构,推动中文数学问题求解领域的算法发展。数据集的构建反映了2023年后中文NLP社区对专业化、结构化训练数据的迫切需求。
当前挑战
该数据集面临双重挑战:在领域问题层面,数学问题的复杂性与语言表达的多样性导致模型需同时掌握数学推理与中文理解能力,而合成数据的真实性缺陷可能影响模型的实际表现;在构建过程层面,原始数据的未校验特性使得问题可解性与答案准确性难以保证,尽管经过筛选过滤,残留的噪声数据仍可能对模型训练产生负面影响。这种数据质量与规模之间的权衡,成为制约数据集应用效果的关键因素。
常用场景
经典使用场景
在教育科技领域,School-Math-R1-Distil-Chinese-220K数据集作为中文数学问题求解的合成数据集,主要被用于训练和评估语言模型在数学推理任务上的表现。研究者通过该数据集中的提示词和模型思考过程,能够深入分析模型在解决数学问题时的逻辑推理能力,特别是在处理多步骤计算和概念理解方面的表现。
衍生相关工作
围绕该数据集衍生的研究主要集中在数学推理模型的优化与评估框架构建上。例如,部分工作利用其合成数据训练轻量级模型以适配边缘设备,另一些研究则基于该数据集设计了新的数学能力评测基准,进一步推动了中文教育场景下AI模型的实用化进程。
数据集最近研究
最新研究方向
在中文教育大模型快速发展的背景下,School-Math-R1-Distil-Chinese-220K数据集为数学问题求解领域提供了重要研究素材。当前研究聚焦于如何利用此类合成数据提升模型逻辑推理能力,特别是在处理多步骤数学应用题时的表现。最新探索方向包括结合思维链技术优化模型解题路径,以及通过对抗训练增强对错误指令的鲁棒性。该数据集的出现恰逢教育数字化转型浪潮,为探索低资源语言环境下数学推理模型的性能边界提供了实验基础。学者们正尝试将其与真实教学场景数据结合,以缓解纯合成数据带来的可信度挑战。
以上内容由遇见数据集搜集并总结生成


