Active Vision Dataset
收藏arXiv2017-03-04 更新2024-06-21 收录
下载链接:
http://cs.unc.edu/~ammirato/active_vision_dataset_website/
下载链接
链接失效反馈官方服务:
资源简介:
Active Vision Dataset是由北卡罗来纳大学教堂山分校计算机科学系创建的一个公开数据集,专注于模拟日常室内环境中的机器人视觉任务。该数据集包含超过20,000张RGB-D图像和50,000多个2D边界框,密集捕获了9个独特场景中的物体实例。数据集的创建过程涉及使用Kinect v2传感器和COLMAP工具进行场景的密集重建,以便于3D对象标注。该数据集主要用于开发和评估基于深度学习的主动视觉系统,特别是在机器人导航和物体识别领域,旨在解决物体尺度、遮挡和视角变化对检测精度的影响问题。
Active Vision Dataset is a public dataset created by the Department of Computer Science at the University of North Carolina at Chapel Hill, focusing on simulating robotic vision tasks in daily indoor environments. It contains over 20,000 RGB-D images and more than 50,000 2D bounding boxes, which densely capture object instances across 9 distinct scenes. The creation of this dataset utilized the Kinect v2 sensor and COLMAP tool to perform dense scene reconstruction, facilitating 3D object annotation. This dataset is primarily used for developing and evaluating deep learning-based active vision systems, particularly in the fields of robot navigation and object recognition, aiming to address the impacts of object scale, occlusion and viewpoint variation on detection accuracy.
提供机构:
北卡罗来纳大学教堂山分校计算机科学系
创建时间:
2017-02-27
搜集汇总
数据集介绍
构建方式
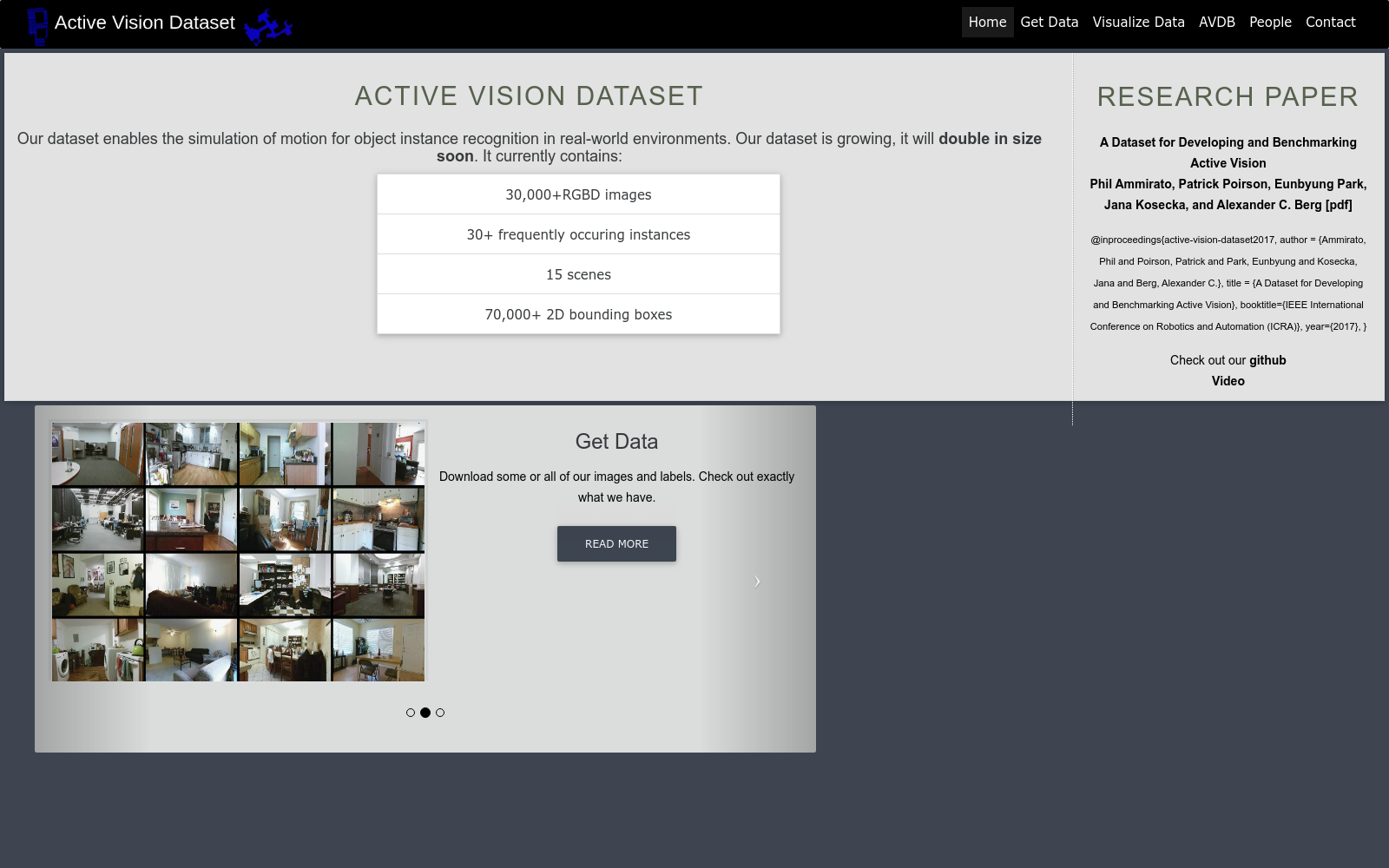
Active Vision Dataset 构建的核心在于模拟机器人在日常室内环境中执行视觉任务,通过采集真实场景的 RGB-D 图像,并进行密集的捕捉。该数据集包括了超过 20,000 张 RGB-D 图像和 50,000 个以上 2D 实例边界框,这些图像和边界框是在 9 个独特的场景中密集捕获的。研究者们使用 Kinect v2 传感器和相应的代码来收集数据,并通过 COLMAP 和 CMVS/PMVS 工具进行场景重建和对象标注。这种密集的采样方式使得数据集能够模拟机器人在场景中的移动,并通过计算相邻图像之间的运动指针来定义图像之间的连通性。
特点
Active Vision Dataset 的特点在于其密集的采样和丰富的场景内容。该数据集不仅提供了大量的 RGB-D 图像,还包含了多个房间的场景,例如厨房、客厅、餐厅和办公室等。此外,数据集还包括了 33 个常见实例的 2D 边界框,以及从每个图像到下一个图像的运动指针。这种密集的采样和丰富的场景内容使得数据集能够模拟机器人在场景中的移动,并通过计算相邻图像之间的运动指针来定义图像之间的连通性。
使用方法
Active Vision Dataset 的使用方法主要是通过训练和评估对象识别方法,以及模拟主动视觉策略。研究者们首先使用一个基于深度卷积网络的快速对象类别检测器来识别数据集中的特定对象实例。接着,他们使用数据集来验证主动视觉的模拟,并开发了一个基于深度网络的系统,用于预测下一个最佳移动,以改善对象分类。此外,数据集还提供了多个训练/测试分割,以确定使用下一个最佳移动网络时,多次移动的预期精度提升。
背景与挑战
背景概述
Active Vision Dataset 是一个专注于模拟日常室内环境中机器人视觉任务的数据集,使用真实的影像进行构建。该数据集由北卡罗来纳大学教堂山分校的计算机科学系的 Phil Ammirato、Patrick Poirson、Eunbyung Park、Jana Košecká 和 Alexander C. Berg 等研究人员于 2017 年创建。数据集包含了 20,000 多张 RGB-D 图像和 50,000 多个 2D 边界框,这些对象实例密集地捕获在 9 个独特的场景中。研究人员在数据集上训练了一个快速的对象类别检测器,用于实例检测。使用该数据集,他们展示了虽然对象检测的准确性和速度越来越高,但仍然受到对象尺度、遮挡和视角的影响,这些因素对机器人应用至关重要。此外,他们还验证了该数据集在模拟主动视觉方面的有效性,并使用该数据集开发并评估了一个基于深度网络的系统,用于使用强化学习进行对象分类的下一步最佳移动预测。该数据集可从 cs.unc.edu/˜ammirato/active_vision_dataset_website/ 下载。
当前挑战
Active Vision Dataset 面临的挑战包括:1) 所解决的领域问题,即如何有效地模拟机器人视觉任务,特别是在日常室内环境中;2) 构建过程中所遇到的挑战,例如如何密集地捕获场景的 RGB-D 图像,以及如何处理遮挡和视角变化等问题。
常用场景
经典使用场景
Active Vision Dataset是一个专注于模拟日常室内环境中机器人视觉任务的数据集,包含超过20,000张RGB-D图像和50,000多个对象实例的2D边界框。这个数据集的经典使用场景包括训练和评估对象检测算法,尤其是在机器人应用中,这些算法能够处理不同的对象尺度、遮挡和观察方向。此外,该数据集也被用于开发基于深度网络的系统,用于通过强化学习预测对象分类的最佳移动。
解决学术问题
Active Vision Dataset解决了机器人视觉任务中的几个常见问题,例如对象检测算法在现实世界场景中受到对象尺度、遮挡和观察方向的影响。该数据集提供了一个研究资源,无需访问机器人即可进行实验,并且允许研究人员在没有评估算法的物理机器人测试床的困难和成本的情况下,对不同的主动视觉方法进行基准测试和比较。此外,该数据集还展示了当前最先进的对象检测算法在处理现实世界视觉感知挑战方面的局限性,包括大规模的尺度和视点变化以及可能不适用于计算机生成的图像的真实成像条件。
衍生相关工作
Active Vision Dataset衍生了几个相关的经典工作,例如使用该数据集进行对象实例检测的研究,以及使用深度网络进行下一个最佳视图选择的研究。此外,该数据集还被用于开发基于强化学习的主动视觉系统,这些系统可以用于提高对象分类的准确性。这些研究工作展示了Active Vision Dataset在机器人视觉任务中的应用潜力,并为未来的研究提供了有价值的资源。
以上内容由遇见数据集搜集并总结生成


