CompreCap 图像描述数据集
收藏超神经2024-12-23 更新2024-12-21 收录
下载链接:
https://hyper.ai/cn/datasets/36568
下载链接
链接失效反馈官方服务:
资源简介:
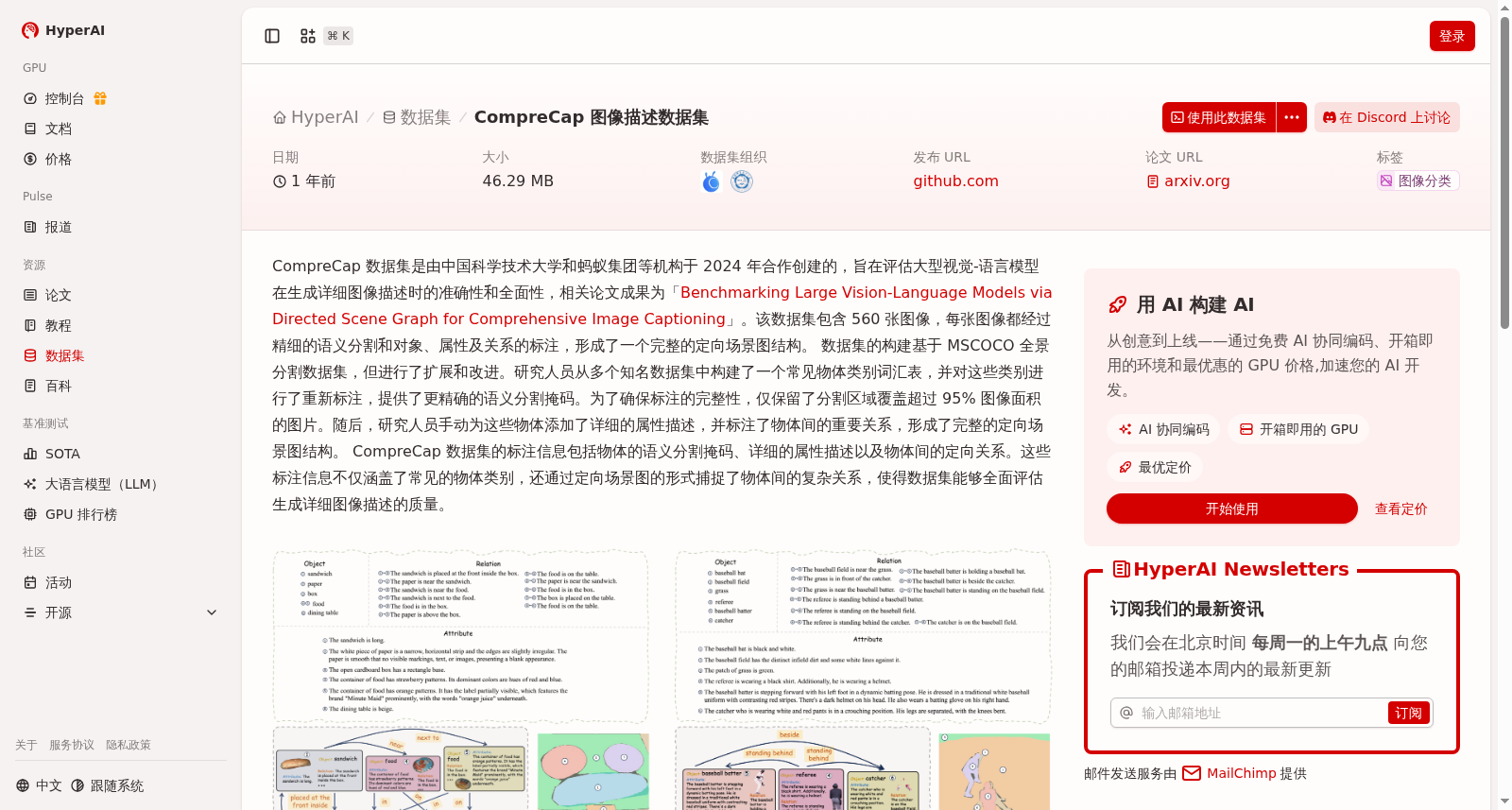
CompreCap 数据集是由中国科学技术大学和蚂蚁集团等机构于 2024 年合作创建的,旨在评估大型视觉-语言模型在生成详细图像描述时的准确性和全面性,相关论文成果为「Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning」。该数据集包含 560 张图像,每张图像都经过精细的语义分割和对象、属性及关系的标注,形成了一个完整的定向场景图结构。
CompreCap dataset was collaboratively created in 2024 by institutions including the University of Science and Technology of China and Ant Group. It aims to evaluate the accuracy and comprehensiveness of large vision-language models when generating detailed image captions. The corresponding research paper is titled "Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning". This dataset contains 560 images, each of which has undergone fine-grained semantic segmentation and annotations of objects, attributes and relationships, forming a complete directed scene graph structure.
创建时间:
2024-12-17
搜集汇总
数据集介绍
背景与挑战
背景概述
CompreCap 图像描述数据集是由中国科学技术大学和蚂蚁集团等机构于2024年合作创建的,旨在评估大型视觉-语言模型生成详细图像描述的准确性和全面性。该数据集包含560张图像,每张图像都经过精细的语义分割和对象、属性及关系的标注,形成一个完整的定向场景图结构,基于MSCOCO数据集扩展并确保标注完整性,以全面评估图像描述质量。
以上内容由遇见数据集搜集并总结生成


