hh_qwen_40k
收藏Hugging Face2025-06-10 更新2025-06-11 收录
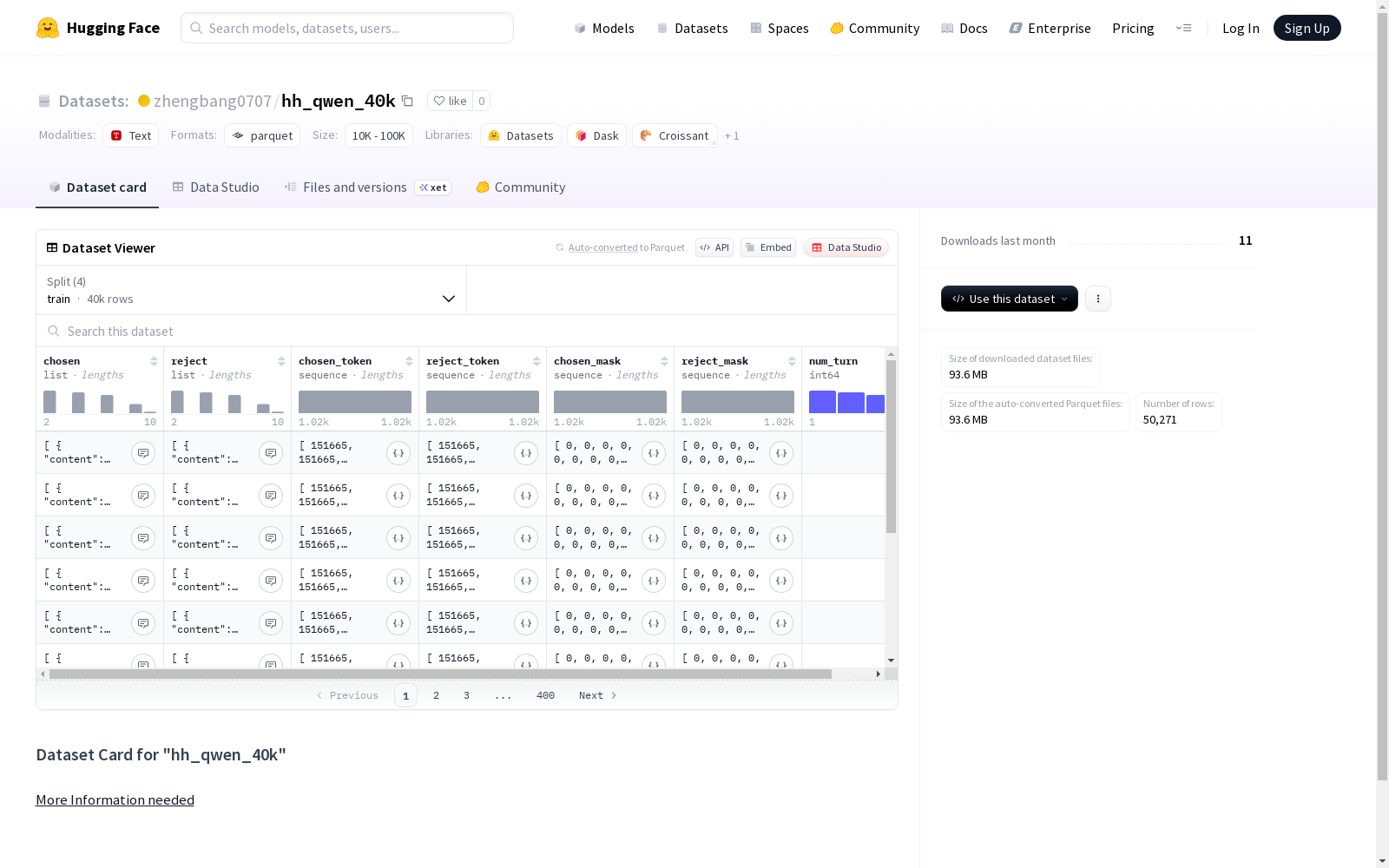
下载链接:
https://huggingface.co/datasets/zhengbang0707/hh_qwen_40k
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含对话数据的数据集,分为训练集、测试集、1k测试集和验证集。每个数据点包括选中的文本内容和角色,以及对应的令牌序列和掩码信息,还包括对话轮数。数据集总大小约为1.74GB,下载大小约为93.64MB。
This is a dataset containing dialogue data, which is divided into training set, test set, 1k test set and validation set. Each data point includes the selected text content and speaker role, corresponding token sequences and mask information, as well as the number of dialogue turns. The total size of the dataset is approximately 1.74 GB, and the download size is approximately 93.64 MB.
创建时间:
2025-06-08
搜集汇总
数据集介绍
构建方式
在对话系统研究领域,hh_qwen_40k数据集通过精心设计的流程构建而成,包含40,000条训练样本及多个评估子集。数据以多轮对话形式组织,每条记录均包含接受和拒绝的回应对,并辅以token序列及掩码信息,确保了对话上下文的结构完整性与逻辑连贯性。
使用方法
研究人员可借助该数据集进行对话生成与偏好对齐模型的训练,尤其适用于强化学习人类反馈(RLHF)任务。通过解析chosen与reject字段的对比,模型可学习人类偏好表示。数据集提供标准化的数据加载接口,支持直接接入主流深度学习框架进行端到端训练与验证。
背景与挑战
背景概述
对话系统研究领域近年来致力于提升人工智能助手的对话质量与安全性,hh_qwen_40k数据集应运而生。该数据集由研究团队基于大规模语言模型Qwen构建,收录了四万条高质量多轮对话样本,涵盖训练集、验证集及测试集划分。其核心研究问题聚焦于通过人类反馈优化对话生成策略,推动对齐学习与偏好优化技术的发展,对促进安全、有用且符合人类价值观的对话系统具有重要影响力。
当前挑战
该数据集主要解决对话生成中的偏好对齐挑战,即如何从人类反馈中学习更符合用户期望的回复,同时避免有害或不恰当内容。构建过程中的挑战包括高质量人类反馈数据的采集与标注,需确保正负样本对的准确性和一致性;多轮对话结构的复杂性要求细致的上下文管理与回合控制;此外,数据规模与质量之间的平衡,以及隐私保护和偏差控制亦是关键难点。
常用场景
经典使用场景
在对话系统与强化学习人类反馈对齐领域,hh_qwen_40k数据集被广泛用于训练和评估对话生成模型。该数据集通过包含接受和拒绝的对话回应配对,为模型提供了明确的人类偏好信号,使研究者能够基于人类反馈优化生成策略,提升对话质量和安全性。
解决学术问题
该数据集有效解决了对话生成中的人类偏好对齐问题,为学术研究提供了大规模、高质量的偏好数据。其意义在于推动了基于人类反馈的强化学习方法在自然语言处理中的应用,帮助模型更好地理解复杂的人类价值观和对话规范,促进了安全、可靠对话系统的发展。
实际应用
在实际应用中,hh_qwen_40k数据集被用于构建智能客服、虚拟助手和教育对话系统,通过优化生成回应的相关性和安全性,提升用户体验。该数据集帮助实际系统减少有害或不相关回应,增强对话的连贯性和实用性,推动了高质量对话技术的落地。
数据集最近研究
最新研究方向
在大语言模型对齐技术快速发展的背景下,hh_qwen_40k数据集作为人类反馈数据的重要资源,正被广泛应用于强化学习从人类反馈(RLHF)和直接偏好优化(DPO)等前沿方法的研究。该数据集通过提供高质量的人类偏好对比样本,助力模型更好地理解和遵循人类意图与价值观,减少有害或偏见性输出。当前研究热点聚焦于如何利用此类数据提升模型的安全性、有用性和诚实性,同时探索更高效的对齐算法以降低训练成本,推动对话人工智能向更负责任的方向发展。
以上内容由遇见数据集搜集并总结生成


