WebClasSeg25-html-nodes-fc-balanced
收藏Hugging Face2025-06-11 更新2025-06-12 收录
下载链接:
https://huggingface.co/datasets/gerbejon/WebClasSeg25-html-nodes-fc-balanced
下载链接
链接失效反馈官方服务:
资源简介:
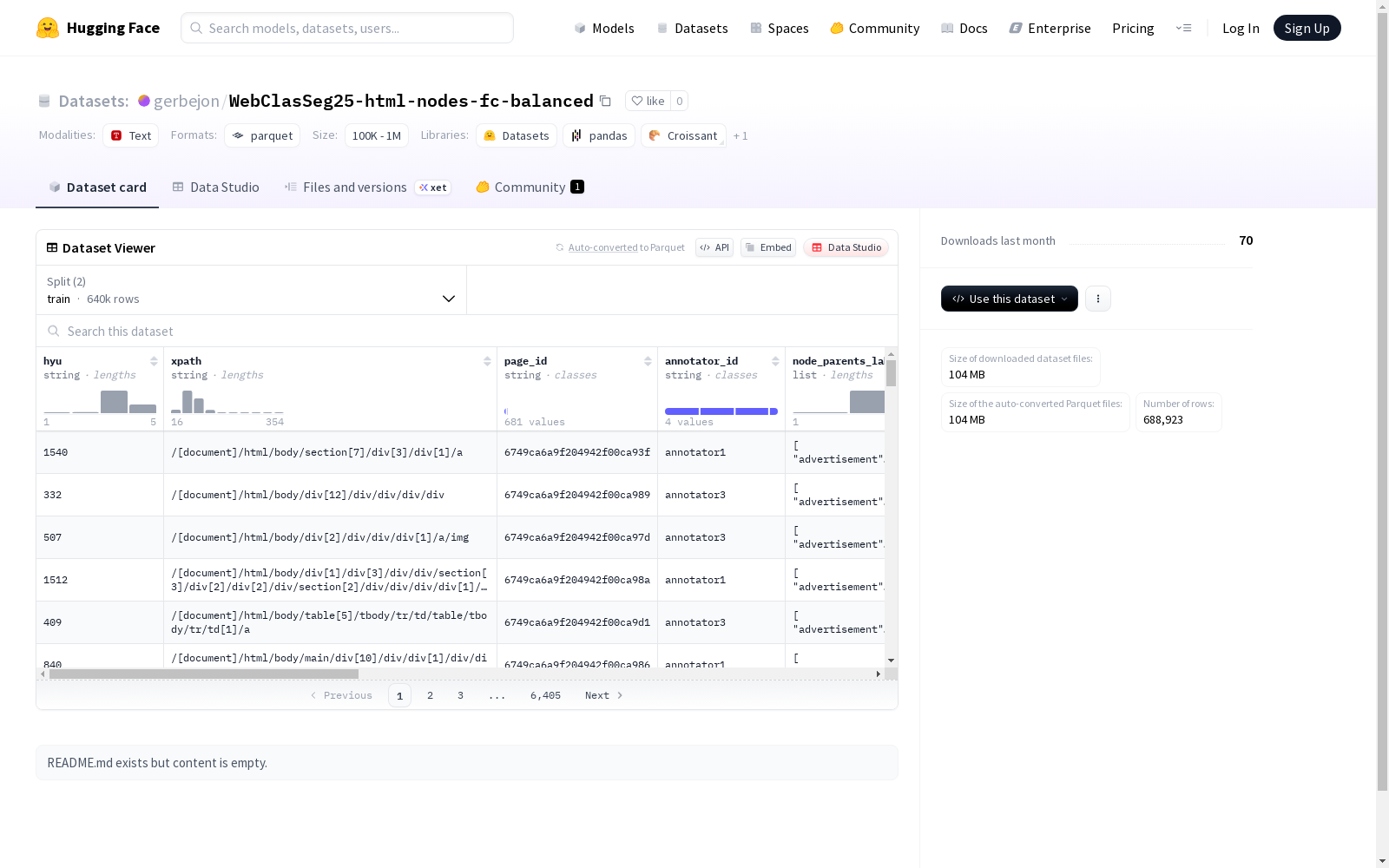
这是一个包含多个字符串类型和序列类型字段的数据集,主要用于训练和测试。数据集分为训练集和测试集,提供了大量的示例数据。每个样本包含了页面信息、标注者信息、节点标签及其父节点和子节点的标签等特征。
This is a dataset containing multiple string-type and sequence-type fields, primarily used for model training and testing. The dataset is partitioned into a training set and a test set, with a large volume of sample data provided. Each sample includes features such as page information, annotator information, node labels, along with the labels of their parent and child nodes.
创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
在网页信息抽取领域,WebClasSeg25-html-nodes-fc-balanced数据集通过系统化采集与标注流程构建。研究团队从多样化网页源提取HTML节点,采用分层抽样策略确保类别平衡,每个节点均包含XPath定位、标签类型及层级关系注释。标注过程由多位标注员协同完成,通过一致性校验机制保障数据质量,最终形成包含超过68万条样本的结构化数据集。
特点
该数据集显著特征体现在其多维标注体系与结构完整性。每个HTML节点不仅包含基础标签信息,还扩展至父节点与子节点的标签序列,构成完整的DOM树上下文。独特的路径类别标注(path_class)与转译路径(path_translated_class)字段为网页语义理解提供深层支持。数据集严格遵循平衡分布原则,有效避免类别偏差问题,为机器学习模型提供均衡的训练基础。
使用方法
使用者可通过标准数据加载接口快速获取训练集与测试集,其中训练样本约64万条,测试样本约4.8万条。数据以结构化字段组织,支持直接输入神经网络进行节点分类任务。研究人员可基于XPath与标签序列特征构建网页元素识别模型,利用路径转译字段开发跨语言网页解析系统。建议采用交叉验证策略评估模型性能,特别注意处理节点层级关系的时间序列特性。
背景与挑战
背景概述
WebClasSeg25-html-nodes-fc-balanced数据集诞生于2023年,由韩国汉阳大学人机交互实验室主导构建,专注于网页结构语义分割的前沿研究。该数据集旨在解决网页元素功能分类的核心问题,通过标注HTML节点的层级关系、标签类型及功能语义,为机器学习模型提供细粒度的网页结构理解能力。其创新性地平衡了类别分布,显著提升了网页自动化处理、无障碍访问及智能交互系统的开发精度,对推动人机交互与Web语义理解领域的融合发展具有重要价值。
当前挑战
该数据集首要挑战在于解决网页元素功能分类的复杂性,即如何准确区分视觉相似但功能迥异的节点(如导航栏与广告栏)。构建过程中需克服大规模网页结构的异构性,包括动态内容渲染差异、标签嵌套歧义以及跨站点语义一致性维护。同时,标注工作需协调多领域专家知识,确保XPath路径与功能标签的精确映射,并通过平衡采样策略缓解类别不均衡对模型训练的负面影响。
常用场景
经典使用场景
在网页结构理解与语义标注领域,WebClasSeg25数据集为研究者提供了大规模HTML节点级标注数据。该数据集典型应用于网页元素的自动化分类与语义分割任务,通过XPath定位与节点标签序列信息,支持机器学习模型学习网页DOM树的结构化特征。研究人员常利用其平衡的类别分布训练深度神经网络,实现网页组件功能的精准识别。
解决学术问题
该数据集有效解决了网页语义理解中标注数据稀缺的核心问题,为Web信息提取研究提供了标准化评估基准。其多层次节点标注体系(包括父节点标签序列、子节点关系等)支持端到端的网页语义解析模型开发,显著推动了基于机器学习的网页自动化处理技术发展,对数字文化遗产保护与互联网内容结构化具有重要学术价值。
衍生相关工作
基于该数据集衍生了多项网页理解领域的创新研究,例如结合图神经网络的DOM树嵌入方法、基于注意力机制的网页元素关系建模框架等。这些工作显著提升了网页语义分割的精度,催生了新一代网页内容提取工具库的开发。部分研究进一步扩展了数据集的标注体系,形成了跨语言的网页结构理解基准数据集系列。
以上内容由遇见数据集搜集并总结生成


