huuuyeah/meetingbank
收藏Hugging Face2024-05-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/huuuyeah/meetingbank
下载链接
链接失效反馈官方服务:
资源简介:
MeetingBank是一个基准数据集,来源于美国6个主要城市的市政会议,用于补充现有数据集。它包含1,366次会议的超过3,579小时的视频、文字记录、会议纪要PDF文件、议程和其他元数据。平均每次市政会议时长为2.6小时,其文字记录包含超过28,000个标记,使其成为会议摘要生成和从会议视频中提取结构信息的宝贵测试平台。数据集包含6,892个片段级别的摘要实例,用于训练和评估性能。
MeetingBank是一个基准数据集,来源于美国6个主要城市的市政会议,用于补充现有数据集。它包含1,366次会议的超过3,579小时的视频、文字记录、会议纪要PDF文件、议程和其他元数据。平均每次市政会议时长为2.6小时,其文字记录包含超过28,000个标记,使其成为会议摘要生成和从会议视频中提取结构信息的宝贵测试平台。数据集包含6,892个片段级别的摘要实例,用于训练和评估性能。
提供机构:
huuuyeah
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-nc-sa-4.0
- 任务类别:
- 摘要生成
- 文本生成
- 语言: 英语
- 标签:
- 市政
- 会议
- 转录
- 基准
- 长上下文
- 大小类别: 10M<n<100M
详细描述
- 名称: MeetingBank
- 来源: 由美国6个主要城市的市议会创建的基准数据集
- 包含内容:
- 1,366次会议
- 超过3,579小时的视频
- 转录文本
- PDF格式的会议记录、议程和其他元数据
- 平均会议时长: 2.6小时
- 平均转录文本长度: 超过28,000个词
- 用途: 适用于会议摘要生成和从会议视频中提取结构
- 训练和评估实例: 6,892个段落级摘要实例
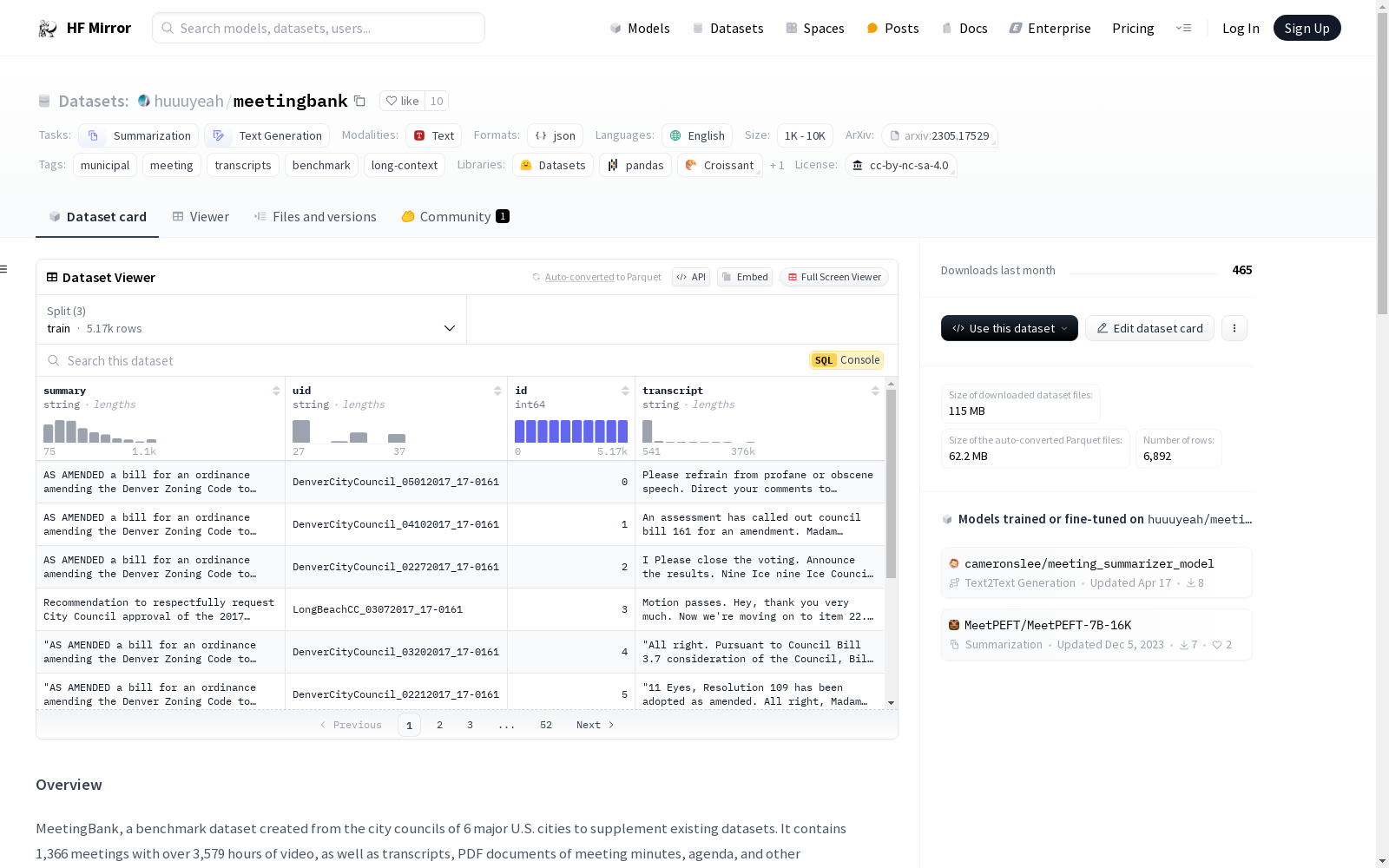
数据结构示例
json { "id": 0, "uid": "SeattleCityCouncil_06132016_Res 31669", "summary": "A RESOLUTION encouraging as a best practice ...", "transcript": "The report of the Civil Rights, Utilities, Economic ..." }
引用信息
bibtex @inproceedings{hu-etal-2023-meetingbank, title = "MeetingBank: A Benchmark Dataset for Meeting Summarization", author = "Yebowen Hu and Tim Ganter and Hanieh Deilamsalehy and Franck Dernoncourt and Hassan Foroosh and Fei Liu", booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)", month = July, year = "2023", address = "Toronto, Canada", publisher = "Association for Computational Linguistics", }
搜集汇总
数据集介绍
构建方式
MeetingBank数据集的构建基于美国六大城市的市议会会议记录,涵盖了1,366场会议,总计超过3,579小时的视频内容。该数据集不仅包括会议的文字转录,还提供了会议纪要、议程及其他元数据的PDF文档。平均每场会议时长2.6小时,转录文本超过28,000个词元,为会议总结和视频结构提取提供了丰富的测试环境。数据集内含6,892个段落级别的总结实例,用于训练和评估模型性能。
使用方法
使用MeetingBank数据集时,用户可以通过HuggingFace的datasets库进行加载,并根据需要选择训练、测试或验证数据。数据集的结构化格式使得用户可以轻松提取会议ID、总结文本和转录内容。此外,数据集还提供了丰富的多媒体资源链接,用户可以根据研究需求访问相应的音频、视频和文本文件。为了更高效地处理数据,用户还可以参考GitHub上的MeetingBank_Utils仓库,获取相关脚本和使用指南。
背景与挑战
背景概述
在自然语言处理领域,会议记录的自动摘要和文本生成一直是研究的热点。MeetingBank数据集由Yebowen Hu等研究人员于2023年创建,旨在为会议摘要和文本生成任务提供一个全面的基准。该数据集汇集了美国六个主要城市的市议会会议记录,包含1,366次会议的超过3,579小时的视频、转录文本、会议纪要、议程及其他元数据。平均每次会议时长2.6小时,转录文本超过28,000个词元,为会议摘要和视频结构提取提供了宝贵的资源。MeetingBank的发布不仅丰富了现有的数据资源,还为相关研究提供了新的测试平台,推动了会议记录处理技术的发展。
当前挑战
MeetingBank数据集在构建过程中面临多项挑战。首先,会议记录的多样性和复杂性使得数据清洗和标注工作异常繁重。其次,长文本和高词元数的特性对模型的处理能力和效率提出了高要求。此外,视频、音频和文本的多模态数据整合也是一个技术难点。在应用层面,如何从海量的会议记录中提取有价值的信息,并生成准确、简洁的摘要,是当前研究的主要挑战。这些挑战不仅涉及技术层面的优化,还需要跨学科的知识融合,以实现更高效、更智能的会议记录处理。
常用场景
经典使用场景
在自然语言处理领域,MeetingBank数据集的经典使用场景主要集中在会议摘要生成和长文本结构化提取。该数据集通过提供大量城市议会会议的转录文本和视频,为研究人员提供了一个丰富的测试平台。具体而言,研究人员可以利用这些数据训练和评估会议摘要生成模型,从而实现对长篇会议内容的精炼和概括。此外,通过分析会议视频和转录文本,还可以提取出会议的结构化信息,如议程、决议等,这对于理解会议流程和决策过程具有重要意义。
解决学术问题
MeetingBank数据集在学术研究中解决了多个关键问题。首先,它填补了现有数据集中会议相关数据的空白,为会议摘要生成和结构化信息提取提供了大规模、高质量的训练数据。其次,通过提供多模态数据(文本、音频、视频),该数据集促进了跨模态学习的研究,使得模型能够更好地理解和处理会议内容。此外,MeetingBank还推动了长上下文处理技术的发展,因为其平均每场会议的转录文本长度超过28k个token,这对于现有模型的处理能力提出了挑战,也促进了相关技术的进步。
实际应用
在实际应用中,MeetingBank数据集具有广泛的应用前景。例如,在政府和企业的决策支持系统中,可以利用该数据集训练的模型自动生成会议摘要,帮助决策者快速了解会议内容和关键决策点。此外,该数据集还可以用于开发智能会议记录系统,自动提取会议中的重要信息并生成结构化的会议纪要,从而提高会议记录的效率和准确性。在教育领域,该数据集也可用于开发会议分析工具,帮助学生和研究人员更好地理解会议的组织和决策过程。
数据集最近研究
最新研究方向
在会议记录和市政决策领域,MeetingBank数据集的引入为会议摘要和文本生成技术提供了新的研究方向。该数据集不仅包含了丰富的会议视频和文本数据,还提供了详细的会议摘要和元数据,使得研究者能够深入探索如何从长篇会议记录中提取关键信息并生成精炼的摘要。此外,MeetingBank的多样性和大规模特性,使其成为评估和改进现有会议摘要系统的理想基准。随着城市治理和公共决策透明度的提升,该数据集的应用前景广阔,特别是在自动化会议记录处理和决策支持系统方面,具有重要的实际意义。
以上内容由遇见数据集搜集并总结生成


