collective-alignment-1
收藏Hugging Face2025-08-27 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/openai/collective-alignment-1
下载链接
链接失效反馈官方服务:
资源简介:
Collective Alignment 1 (CA-1)是一个专注于价值敏感模型行为的带有人工反馈的数据集。每个记录包含一个合成提示、四个候选回复和评估者的评估及理由。数据集还包括评估者的基本信息。
Collective Alignment 1 (CA-1) is a human-feedback dataset focused on value-sensitive model behavior. Each record comprises a synthetic prompt, four candidate responses, as well as the evaluators' assessments and their accompanying justifications. The dataset additionally contains basic information about the evaluators.
提供机构:
OpenAI
创建时间:
2025-08-27
原始信息汇总
Collective Alignment 1 (CA-1) 数据集概述
数据集简介
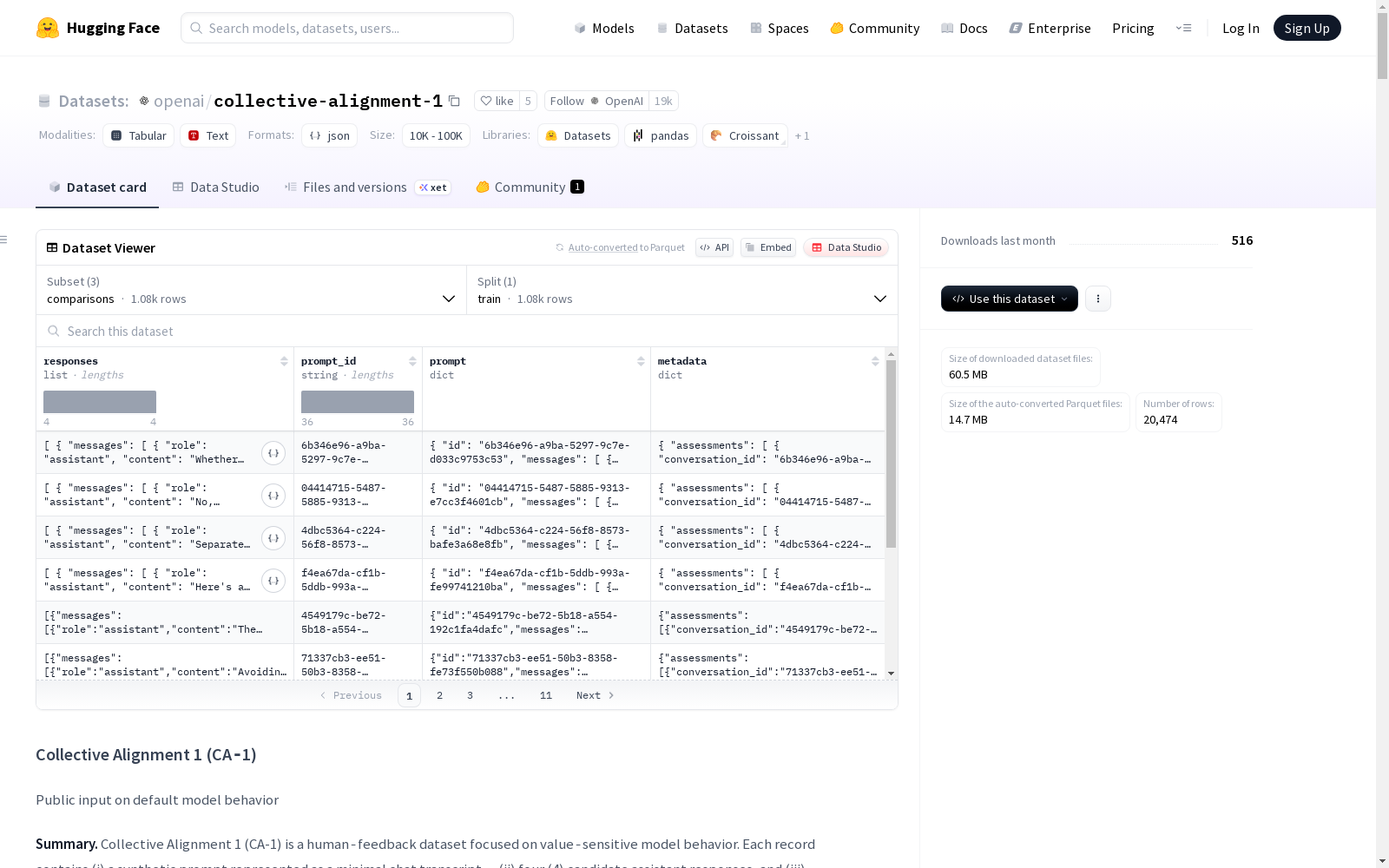
Collective Alignment 1 (CA-1) 是一个专注于价值敏感模型行为的人类反馈数据集。每条记录包含:(i) 表示为最小聊天记录的合成提示,(ii) 四个候选助手响应,以及 (iii) 带有解释的标注者评估。配套文件提供标注者人口统计信息。
数据集构成
- 比较文件 (
comparisons.jsonl):包含提示、候选响应(A-D)和每项评估 - 标注者文件 (
annotators.jsonl):每个标注者一行,包含人口统计信息和完成的评估 - 合并文件 (
merged_comparisons_annotators.jsonl):每个(提示×标注者)评估一行,包含人口统计信息和对话级别的便利特征
数据规模
- 比较(提示):1,078个独特比较
- 标注者:1,012个独特标注者
- 评估:18,384个评估(在
comparisons.jsonl中) - 每个提示的候选响应:每个提示4个候选响应
数据收集方法
- 提示和候选:使用OpenAI模型输出混合生成多个候选助手消息作为响应
- 评估:人类标注者审查每个提示的候选,按偏好排序(带解释),并提供重要性、代表性和主观性标签
- 发布前清理:执行角色映射(从
system重映射到developer),暂未包含评分标准分数
标注流程
标注者按以下顺序完成每个提示的评估:
- 不可接受内容检查:标记存在安全违规或极低质量问题的响应
- 个人偏好排序:根据个人价值观和偏好对响应排序
- 世界观排序:从社会整体角度对响应排序
- 提示级别评分:评估问题的重要性、代表性和主观性
- 评分标准编写:编写客观的评估标准并分配-10到+10的权重
关键统计信息
任务价值统计
- 重要性:非常重要 9,161 · 有些重要 7,510 · 不重要 1,713
- 代表性:完全不可能 7,533 · 稍微可能 3,657 · 中等 3,088 · 非常 2,259 · 极其可能 1,847
- 主观性:价值依赖(主观)8,650 · 单一正确答案(客观)5,272 · 不确定/视情况而定 2,911 · 上下文依赖 1,551
排序和解释覆盖
ranking_world提供 18,384 个比较(每个带有rationale_world)ranking_personal提供 18,384 个比较(每个带有rationale_personal)rating_unacceptable在 4,901 个案例中提供(每个带有rationale_unacceptable)
标注者人口统计
- 1,012个独特标注者,提供年龄、性别、教育水平、居住国、生成式AI使用情况、AI关注级别和理想模型行为信息
- 主要特征:25-34岁年龄组最大(42%);性别52%男性,46%女性,2%非二元/其他;高等教育普遍
- 主要居住国:美国(362)、墨西哥(142)、南非(136)、荷兰(117)、智利(81)、英国(76)、印度(38)、肯尼亚(23)、日本(10)、瑞士(8)
文件结构
所有文件均为行分隔JSON(.jsonl),每行是一个自包含的JSON对象。
comparisons.jsonl 结构
包含提示ID、提示消息、候选响应和元数据评估信息。
annotators.jsonl 结构
包含标注者ID、人口统计信息和所有完成的评估。
merged_comparisons_annotators.jsonl 结构
包含提示ID、标注者ID、评分指标、排序块、人口统计信息和对话特征。
注意事项
- 非代表性样本:英语阅读、互联网可访问群体,某些国家/人口统计数据过度代表或代表不足
- 提示领域偏差:提示聚焦于有争议或价值敏感的领域,可能引入细微偏差
- 内容警告:部分提示/响应包含令人不安或冒犯性内容
- 语言考虑:指令为英语,大多数解释为英语,部分为其他语言(主要是西班牙语)
- 隐私和伦理:不得尝试识别标注者
搜集汇总
数据集介绍
构建方式
在人工智能伦理与价值对齐研究领域,Collective Alignment 1数据集通过多阶段流程构建。首先合成涉及全球敏感性话题的提示词,每个提示词配备四个由混合OpenAI模型生成的候选回复。随后招募来自多元文化背景的标注者,通过严格的入职测验确保评估标准一致性。标注流程包含不可接受内容筛查、个人偏好排序、世界观排序及标准制定环节,最终形成包含1078个提示词、1012名标注者及18384条评估记录的结构化数据。
特点
该数据集的核心特征体现在多维度的价值对齐评估体系。每个提示词对应四个差异化模型响应,涵盖安全合规性、文化适应性与价值敏感性等多重维度。标注数据不仅包含双层次排序(个人偏好与世界观偏好)及详细理据说明,还整合了标注者人口统计学特征与AI使用态度数据。数据集采用三文件架构存储,包括提示词-响应对比文件、标注者元数据文件及合并评估文件,支持从对话分析、群体差异研究到模型行为对齐的多角度研究需求。
使用方法
研究人员可通过HuggingFace平台获取JSONL格式数据文件,利用标准JSON解析工具进行加载。comparisons.jsonl适用于分析特定提示词下的多响应评估分布;annotators.jsonl支持标注者群体特征与评估行为关联研究;merged_comparisons_annotators.jsonl为纵向分析提供便利,可直接转换为数据分析框架格式。使用前需注意数据代表性局限与内容警告,建议结合人口统计学变量进行跨群体比较研究,或用于训练基于人类反馈的价值对齐模型。
背景与挑战
背景概述
由OpenAI于2025年推出的Collective Alignment 1(CA-1)数据集,聚焦于人工智能伦理与价值观对齐研究领域。该数据集旨在通过跨文化、跨背景的大规模人工标注,探索人类对模型行为的共识与分歧,并为AI系统价值观校准提供实证基础。其核心研究问题涉及多维度评估模型输出的可接受性、偏好排序及价值敏感性,推动了人机交互伦理研究从理论框架向数据驱动范式转变。
当前挑战
该数据集需解决价值敏感场景下模型行为评估的复杂性挑战,包括跨文化价值观差异的量化建模、主观偏好与客观标准的分辨,以及标注一致性的保障。构建过程中面临多语言标注质量控制、合成提示词的文化偏见消除、大规模人工标注流程设计等难题,同时需平衡全球样本代表性与伦理隐私约束。
常用场景
经典使用场景
在人工智能对齐研究领域,Collective Alignment 1数据集为评估多文化背景下人类对模型行为的价值偏好提供了标准范式。该数据集通过合成对话提示和候选响应组合,要求标注者从个人偏好和全球视角两个维度对模型输出进行排序,并撰写评估准则。这种设计使得研究者能够系统分析不同文化群体对理想AI行为的共识与分歧,为跨文化对齐研究建立了可重复的实验框架。
实际应用
在实际应用层面,该数据集为AI企业的模型调优提供了重要参考。OpenAI已直接利用其分析结果更新了Model Spec规范,指导模型在敏感话题上的响应策略。企业可基于该数据集训练奖励模型,使AI系统在保持帮助性的同时更好地符合多元文化价值观。教育机构也可将其用作AI伦理课程的案例材料,帮助学生理解全球化背景下技术伦理的复杂性。
衍生相关工作
该数据集催生了多项重要研究,包括基于标注者人口统计学特征的偏好预测模型、跨文化对齐度量指标的构建,以及多准则强化学习算法的改进。特别值得注意的是,其提供的准则项创作范式启发了后续的众包评估框架设计,许多研究开始采用类似的带权重要素评估方法,推动了人机交互评估从简单评分向结构化准则体系的演进。
以上内容由遇见数据集搜集并总结生成


