relbert/nell
收藏Hugging Face2023-02-02 更新2024-03-04 收录
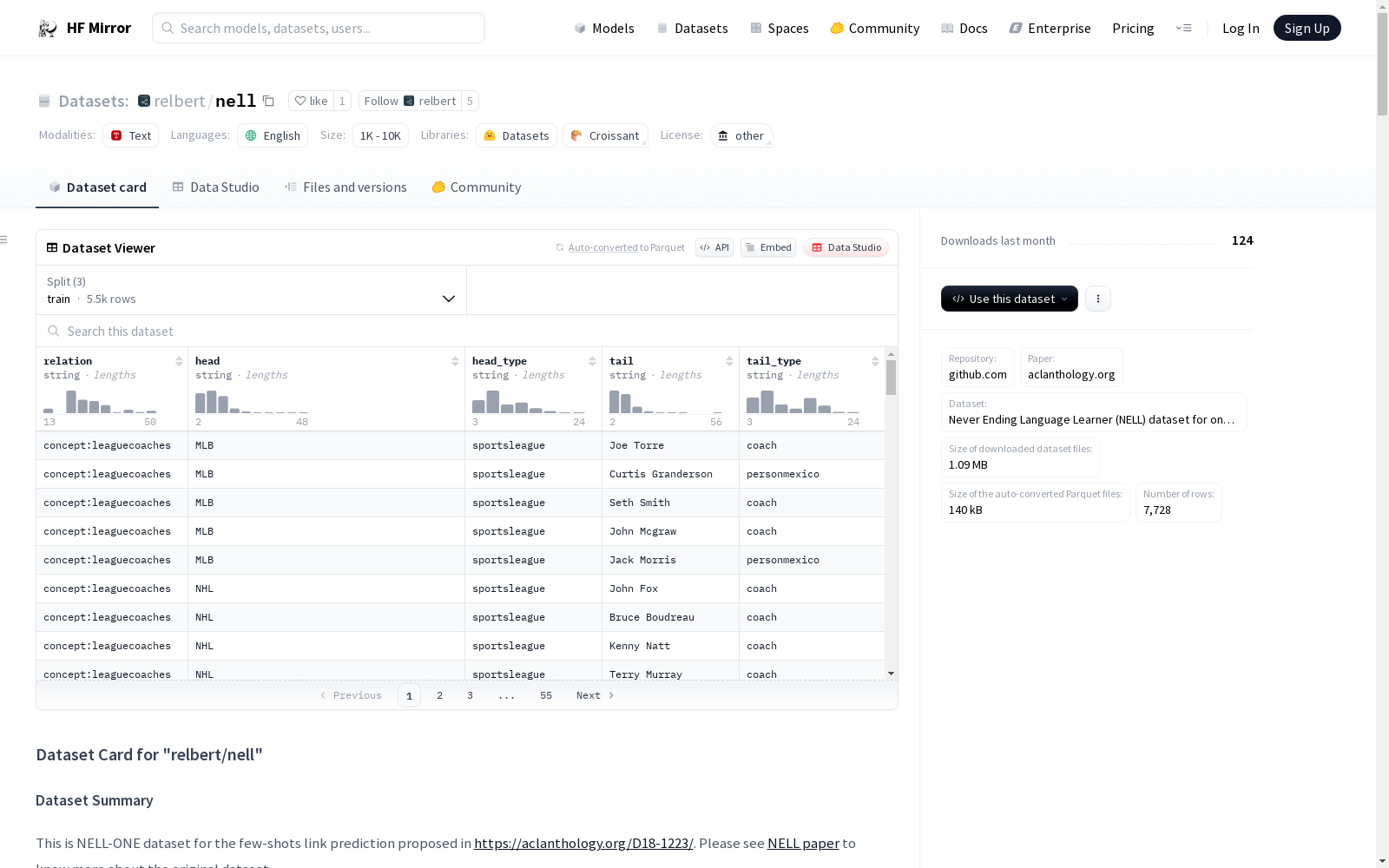
下载链接:
https://hf-mirror.com/datasets/relbert/nell
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是NELL-ONE数据集,用于少样本链接预测。数据集包含5498个训练对、878个验证对和1352个测试对,涉及32种唯一关系类型。每种关系类型的实例数量在训练、验证和测试集中有所不同。此外,数据集还包含多种实体类型,如演员、机场、运动员等,每种实体类型在训练、验证和测试集中的头实体和尾实体数量也有所不同。
This dataset is the NELL-ONE dataset, designed for few-shot link prediction. It comprises 5,498 training pairs, 878 validation pairs, and 1,352 test pairs, covering 32 unique relation types. The number of instances for each relation type varies across the training, validation, and test sets. Additionally, the dataset contains multiple entity types such as actors, airports, athletes, etc., and the counts of head and tail entities for each entity type also differ among the training, validation, and test sets.
提供机构:
relbert
原始信息汇总
数据集概述
基本信息
- 名称: relbert/nell
- 语言: 英语
- 许可证: 其他
- 多语言性: 单语
- 大小: 小于1000条记录
数据集内容
- 类型: 用于一击关系学习的NELL数据集
- 用途: 用于一击链接预测
- 实例数量:
- 训练集: 5498对
- 验证集: 878对
- 测试集: 1352对
- 唯一关系类型数量:
- 训练集: 32种
- 验证集: 4种
- 测试集: 6种
实体类型数量
- 头部实体 (训练集): 多种实体类型,如actor, airport, athlete等
- 尾部实体 (训练集): 多种实体类型,如city, company, country等
- 头部实体 (验证集): 多种实体类型,如city, country, person等
- 尾部实体 (验证集): 多种实体类型,如city, person, politicalparty等
- 头部实体 (测试集): 多种实体类型,如automobilemaker, geopoliticallocation, politicianus等
- 尾部实体 (测试集): 多种实体类型,如automobilemaker, person, sportsteam等
搜集汇总
数据集介绍
构建方式
relbert/nell数据集的构建是基于NELL-ONE数据集,该数据集是为了进行少量样本链接预测而设计的。数据集来源于Never Ending Language Learner (NELL)项目,该项目的目标是构建一个可以自动从网络文本中学习实体和关系的系统。NELL项目从网络中收集数据,并利用这些数据来训练和验证模型。relbert/nell数据集在NELL数据集的基础上,进行了适当的分割,形成了训练集、验证集和测试集,以便于进行模型训练和评估。
使用方法
relbert/nell数据集可用于少量样本链接预测任务的研究和模型训练。研究者可以使用数据集的训练集来训练模型,使用验证集来调整模型参数,使用测试集来评估模型的性能。此外,数据集还提供了实体类型和关系类型的数量,以及每种关系类型在各个数据集中的实例数量,这些信息可以帮助研究者更好地理解和利用数据集。
背景与挑战
背景概述
在知识图谱和关系推理的研究领域,如何从少量数据中准确预测实体间的关系是一个极具挑战性的问题。Relbert/nell数据集,即Never Ending Language Learner (NELL)数据集,是针对这一问题而构建的。NELL项目始于2007年,由卡内基梅隆大学的研究团队发起,旨在通过自动学习的方式不断扩展知识图谱。该数据集的核心研究问题是探索在少量样本的情况下,如何实现高精度的链接预测,这对于推动关系推理技术的发展具有重要意义。NELL数据集对相关领域的影响力体现在,它为研究者在少样本关系预测任务中提供了宝贵的实验数据和基准,促进了少样本学习技术在知识图谱领域的应用和发展。
当前挑战
Relbert/nell数据集主要面临的挑战包括:1) 所解决的领域问题的挑战:在少样本情况下实现高精度的链接预测,这要求模型能够从极小的数据集中学习到实体间复杂的关系模式;2) 构建过程中所遇到的挑战:由于数据集规模较小,且样本分布不均,如何在保持数据质量的同时,有效地平衡不同关系类型的样本数量,以避免模型对某些关系类型的过度依赖或忽视,是一个需要深入研究的课题。此外,如何在保证模型泛化能力的同时,提升其在特定关系类型上的预测性能,也是一个亟待解决的问题。
常用场景
经典使用场景
在知识图谱嵌入领域,relbert/nell数据集被广泛用于评估和训练模型进行链接预测。该数据集包含了丰富的实体和关系类型,为模型提供了多样性和复杂性的挑战。通过在relbert/nell数据集上进行训练,模型可以学习到如何从一个实体预测与其相关的另一个实体,这在知识图谱的补全、推荐系统以及实体识别等领域具有广泛的应用。
解决学术问题
relbert/nell数据集主要解决了知识图谱嵌入中的链接预测问题。在学术研究中,链接预测是评估知识图谱嵌入模型性能的重要指标之一。relbert/nell数据集通过提供不同数量的训练数据,使得研究者可以评估模型在少量样本下的泛化能力,这对于在实际应用中处理稀疏数据集具有重要的意义。此外,relbert/nell数据集还提供了不同关系类型的实例,有助于研究者在不同场景下评估模型的性能。
实际应用
relbert/nell数据集在实际应用中主要用于知识图谱的补全和推荐系统。通过在relbert/nell数据集上进行训练,模型可以学习到实体之间的关系,从而在知识图谱中预测缺失的链接。这在构建更完整、准确的知识图谱中发挥着重要作用。此外,relbert/nell数据集还可以用于推荐系统,通过预测用户与实体之间的关系,推荐系统可以为用户提供个性化的推荐内容。
数据集最近研究
最新研究方向
在知识图谱领域,relbert/nell数据集因其独特的单样本链接预测任务而备受关注。该数据集源自Never Ending Language Learner (NELL)项目,旨在研究如何通过极少的样本进行关系预测,这对于知识图谱的扩展和应用至关重要。当前研究主要集中在如何利用深度学习技术,特别是Transformer模型,来改善这一任务的性能。此外,如何处理数据集中的长尾分布问题,即某些关系类型拥有非常少的样本,也是研究的热点。这些研究的进展对于提高知识图谱的自动构建和更新能力具有重要意义,从而推动知识图谱在推荐系统、信息检索等领域的应用。
以上内容由遇见数据集搜集并总结生成


