Sem-Lex Benchmark
收藏arXiv2023-09-30 更新2024-06-21 收录
下载链接:
https://github.com/leekezar/SemLex
下载链接
链接失效反馈官方服务:
资源简介:
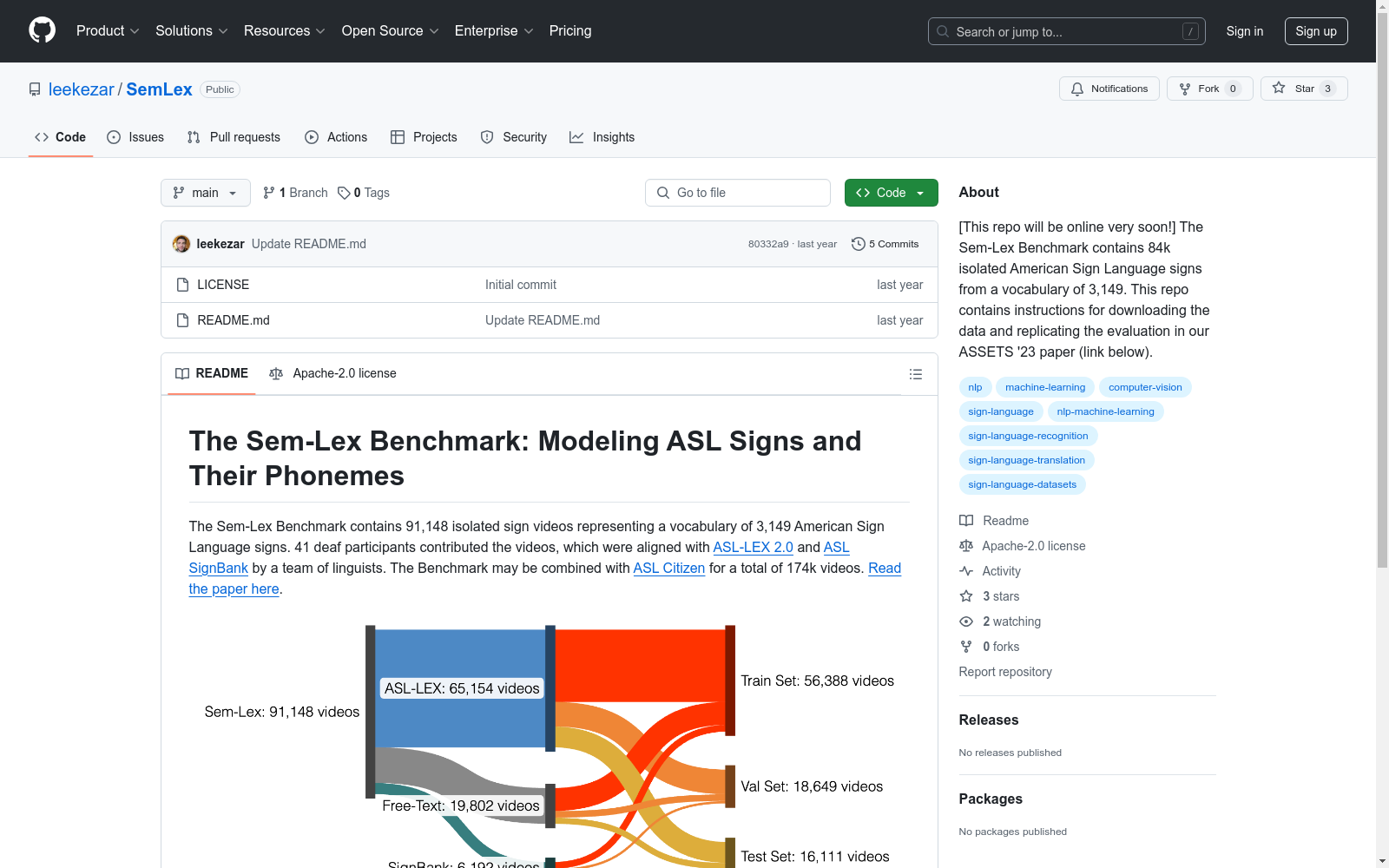
Sem-Lex Benchmark是由南加州大学和波士顿大学的研究团队创建的大型美国手语(ASL)数据集,包含超过84,000个由聋人ASL使用者提供的孤立手势视频。该数据集通过与ASL-LEX、SignBank和ASL Citizen等资源的对齐,增强了对手势和音位特征识别的支持。数据集的创建过程涉及专家的标注和审核,使用了一种新的标注系统,确保了数据的可靠性和快速标注能力。该数据集主要应用于孤立手势识别(ISR)领域,旨在提高手语识别技术的准确性和公平性,特别是在处理少数样本和不同种族、性别的手语使用者时。
The Sem-Lex Benchmark is a large-scale American Sign Language (ASL) dataset developed by research teams from the University of Southern California and Boston University. It contains over 84,000 isolated sign language videos contributed by deaf ASL users. By aligning with existing resources such as ASL-LEX, SignBank, and ASL Citizen, this dataset enhances support for gesture and phonological feature recognition. During its construction, the dataset underwent expert annotation and review, employing a novel annotation system to ensure data reliability and enable rapid, efficient annotation. Primarily applied in the field of isolated sign recognition (ISR), this benchmark aims to improve the accuracy and fairness of sign language recognition technologies, particularly when addressing few-shot scenarios and sign language users from diverse racial and gender backgrounds.
提供机构:
南加州大学, 波士顿大学
创建时间:
2023-09-30
搜集汇总
数据集介绍
构建方式
Sem-Lex Benchmark 数据集通过从聋哑人手语者中收集大量孤立手语视频构建而成,这些手语者提供了知情同意并获得了报酬。数据集包含超过84,000个视频,由人类专家与ASL-LEX、SignBank和ASL Citizen等手语资源进行对齐,确保了数据的准确性和扩展性。数据集的构建采用了新颖的标注系统,能够快速、可靠地标注手语数据,并通过与现有手语数据库的交叉引用,提供了丰富的语言学信息。
特点
Sem-Lex Benchmark 数据集是目前同类数据集中规模最大的,具有多样性和代表性。其特点在于包含了详细的音韵特征标注,这些特征从ASL-LEX中提取,能够显著提升手语识别的准确性。此外,数据集还特别关注了手语者的多样性,测试集包含了不常见的手语者,以评估模型对不同种族和性别手语者的敏感性。
使用方法
Sem-Lex Benchmark 数据集可用于孤立手语识别(ISR)和音韵特征识别任务。研究者可以使用SL-GCN模型进行训练,该模型能够同时处理手语识别和音韵特征识别任务,从而提升整体识别性能。数据集的下载和使用指南可在GitHub上找到,用户需遵循伦理规范,确保数据使用的透明性和对聋哑社区的尊重。
背景与挑战
背景概述
Sem-Lex Benchmark是由南加州大学和波士顿大学的研究团队于2023年推出的一个专门用于美国手语(ASL)建模的数据集。该数据集由超过84,000个来自聋人手语者的孤立手语视频组成,这些视频经过人类专家的标注,并与ASL-LEX、SignBank和ASL Citizen等资源进行了对齐。Sem-Lex Benchmark的创建旨在解决手语识别和翻译技术中的数据瓶颈问题,特别是缺乏代表性数据的问题。该数据集不仅为手语识别(ISR)提供了丰富的资源,还通过引入音位特征识别,提升了手语识别的准确性和公平性,对手语技术的研究具有重要推动作用。
当前挑战
Sem-Lex Benchmark面临的主要挑战包括:1) 手语识别领域的复杂性,手语不仅仅是视觉问题,还涉及语言结构和音位特征的识别;2) 数据集构建过程中,如何确保数据的代表性和多样性,特别是如何避免模型对特定手语者的过度依赖;3) 手语数据的标注和音位特征的提取,需要高度专业化的知识和工具,标注过程的复杂性和一致性也是一大挑战。此外,如何将手语数据与其他语言资源进行有效整合,以提升模型的泛化能力,也是该数据集未来需要解决的问题。
常用场景
经典使用场景
Sem-Lex Benchmark 数据集的经典使用场景主要集中在孤立手语识别(ISR)任务中。该数据集通过提供超过84,000个由聋人手语者制作的孤立手语视频,支持对手语词汇的识别和分类。通过结合ASL-LEX、SignBank和ASL Citizen等资源,数据集不仅提供了手语词汇的标注,还包含了详细的音位特征信息,使得模型能够在识别手语的同时,学习手语的音位结构,从而提升识别精度。
衍生相关工作
Sem-Lex Benchmark 数据集的发布激发了大量相关研究工作,特别是在手语识别和音位特征建模领域。基于该数据集,研究者开发了多种手语识别模型,如SL-GCN模型,显著提升了手语识别的准确性。此外,数据集的音位特征标注为手语音位学研究提供了新的视角,推动了对手语音位结构的深入理解。未来,该数据集有望进一步推动手语翻译、手语语音合成以及手语教育等领域的技术发展。
数据集最近研究
最新研究方向
近年来,Sem-Lex Benchmark数据集在手语识别与翻译领域引起了广泛关注。该数据集通过提供超过84,000个来自聋哑美国手语(ASL)使用者的孤立手语视频,填补了手语数据稀缺的空白。研究者们利用该数据集进行了一系列实验,特别是对手语的音位特征识别进行了深入探索。研究表明,结合音位特征的识别模型在孤立手语识别(ISR)任务中表现显著提升,尤其是在少样本学习场景下,模型性能提升了6%。此外,该数据集还通过多样化的测试集设计,帮助量化模型对不同种族和性别手语者的偏见。这些研究不仅推动了手语识别技术的发展,也为手语语言学的研究提供了新的视角,进一步促进了手语作为合法语言的认可与应用。
相关研究论文
- 1The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes南加州大学, 波士顿大学 · 2023年
以上内容由遇见数据集搜集并总结生成


