SingingHead
收藏arXiv2023-12-08 更新2024-06-21 收录
下载链接:
https://wsj-sjtu.github.io/SingingHead/
下载链接
链接失效反馈官方服务:
资源简介:
SingingHead是由上海交通大学创建的大型4D数据集,专注于歌唱头部动画。该数据集包含超过27小时的同步歌唱视频、3D面部运动、歌唱音频和背景音乐,来自76个不同个体和8种音乐类型。数据集的创建过程考虑了数据质量和多样性,确保了高分辨率的视频和准确的3D面部扫描。SingingHead数据集的应用领域包括虚拟头像、扩展现实(XR)和娱乐等,旨在解决歌唱特定数据集的缺乏问题,推动歌唱头部动画技术的发展。
SingingHead is a large-scale 4D dataset dedicated to singing head animation, developed by Shanghai Jiao Tong University. It encompasses over 27 hours of synchronized singing videos, 3D facial motions, singing audio and background music, sourced from 76 unique individuals and spanning 8 music genres. The development of this dataset prioritizes both data quality and diversity, guaranteeing high-resolution videos and accurate 3D facial scans. Application scenarios of the SingingHead dataset cover virtual avatars, extended reality (XR), entertainment and other relevant fields, with the goal of addressing the scarcity of singing-specific datasets and advancing the development of singing head animation technologies.
提供机构:
上海交通大学
创建时间:
2023-12-07
搜集汇总
数据集介绍
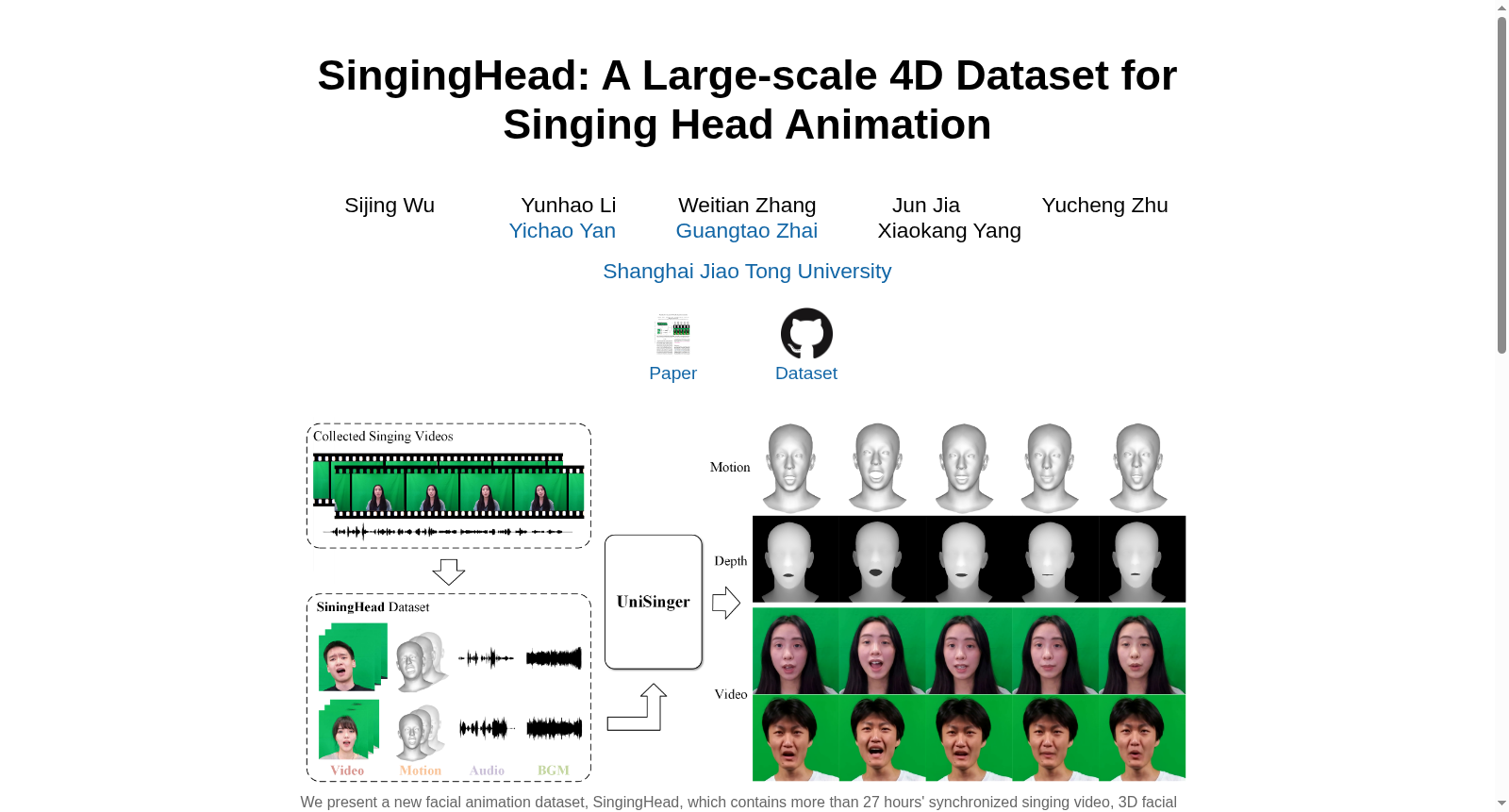
构建方式
在音频驱动面部动画领域,歌唱动画因缺乏高质量数据而长期受限。SingingHead数据集通过实验室采集构建,招募了76名志愿者,涵盖专业歌手与业余爱好者,确保数据多样性。利用Azure Kinect相机以3840×2160分辨率录制视频,同步采集干声与伴奏音频,并通过光场相机获取高精度三维面部扫描。数据处理阶段,采用MTCNN进行面部检测与裁剪,生成1024×1024的肖像视频序列;结合单目三维重建与扫描拟合,优化FLAME模型参数,最终形成包含超过27小时同步视频、三维运动、音频及背景音乐的多模态数据集。
使用方法
该数据集适用于音频驱动的三维与二维歌唱面部动画研究。使用时可分割为8秒片段,按比例划分为训练、验证与测试集。三维动画任务可直接利用FLAME参数与音频对,训练如VAE等生成模型,以合成与输入同步的面部运动。二维动画则需结合参考图像,通过渲染模块将生成的三维运动转化为肖像视频。评估时可采用最小距离、平均距离等指标衡量三维运动的准确性与多样性,或使用FID、SSIM等评估视频质量。数据集的发布促进了UniSinger等统一框架的开发,推动了歌唱动画领域的进展。
背景与挑战
背景概述
在音频驱动面部动画领域,歌唱作为一种仅次于说话的重要面部运动,长期以来因缺乏专门数据集而鲜有研究。上海交通大学的研究团队于2023年发布了SingingHead数据集,旨在填补歌唱头部动画数据的空白。该数据集包含超过27小时的高质量同步数据,涵盖76位受试者的歌唱视频、三维面部运动、干声演唱音频及背景音乐,其规模与多样性均达到业界前沿水平。该数据集的构建不仅推动了歌唱面部动画这一细分领域的发展,也为跨文化情感交流与娱乐应用提供了关键的数据基础。
当前挑战
SingingHead数据集致力于解决歌唱头部动画这一特定领域的挑战,其核心在于克服歌唱与说话在节奏、幅度和表现力上的显著差异。现有基于说话数据集训练的方法难以直接迁移至歌唱场景,导致生成的面部动画缺乏同步性与表现力。在数据构建过程中,研究团队面临多重挑战:需在实验室环境中同步采集高分辨率视频与干声音频,确保数据质量;需处理志愿者在演唱时的身体晃动,实现面部区域的稳定裁剪与序列化;还需从二维肖像视频中精确重建三维面部运动,这一病态问题通过结合三维面部扫描与优化算法得以缓解,以保障运动参数的准确性。
常用场景
经典使用场景
在音频驱动面部动画领域,歌唱作为一种仅次于说话的重要面部运动形式,其独特的节奏和幅度变化对现有模型构成了显著挑战。SingingHead数据集通过提供超过27小时的高质量同步歌唱视频、三维面部运动数据、干声及背景音乐,为歌唱头部动画研究奠定了数据基础。该数据集最经典的使用场景是训练和评估音频驱动的歌唱面部动画模型,特别是针对歌唱与说话之间的领域鸿沟,为生成与歌唱音频精准同步且富有表现力的三维面部运动或二维肖像视频提供关键训练样本。
解决学术问题
该数据集有效解决了歌唱面部动画研究中长期存在的关键学术问题。首先,它填补了高质量、大规模歌唱专用面部动画数据集的空白,克服了以往研究因依赖说话数据集或小规模歌唱数据而导致的领域适应难题。其次,数据集提供的同步多模态数据(视频、三维运动、音频)使得模型能够学习歌唱特有的节奏、幅度与面部运动的复杂映射关系,促进了歌唱与说话动画的域间差异研究。其意义在于为音频驱动动画领域开辟了新的研究方向,推动了虚拟化身在艺术表达与娱乐应用中的自然性与表现力。
实际应用
SingingHead数据集的实际应用场景广泛覆盖数字娱乐与虚拟交互领域。在虚拟偶像与数字人产业中,该数据集可用于驱动虚拟歌手生成高度同步且富有情感的歌唱表演,提升演唱会的沉浸感与真实度。在扩展现实(XR)与元宇宙应用中,它能赋能虚拟化身进行个性化的歌唱表达,增强社交互动与情感交流。此外,在音乐教育、游戏角色动画以及影视特效制作中,该数据集支持生成与任意输入歌唱音频匹配的逼真面部动画,显著降低了高质量歌唱内容制作的技术门槛与成本。
数据集最近研究
最新研究方向
在音频驱动面部动画领域,歌唱头部动画作为情感表达与艺术娱乐的重要分支,正逐渐成为研究热点。SingingHead数据集的发布填补了歌唱专用数据集的空白,其包含超过27小时的高质量同步视频、三维面部运动、歌唱音频及背景音乐,为跨模态生成任务提供了丰富资源。前沿研究聚焦于利用该数据集训练统一框架如UniSinger,以同时解决三维面部运动生成与二维肖像视频合成的双重挑战,突破传统语音驱动模型在歌唱节奏与幅度上的局限。这一进展不仅推动了虚拟化身在娱乐产业的应用,也为跨文化情感交流的数字化呈现开辟了新路径。
相关研究论文
- 1SingingHead: A Large-scale 4D Dataset for Singing Head Animation上海交通大学 · 2023年
以上内容由遇见数据集搜集并总结生成


