laion/captioned-ai-music-snippets
收藏Hugging Face2025-07-30 更新2025-07-05 收录
下载链接:
https://hf-mirror.com/datasets/laion/captioned-ai-music-snippets
下载链接
链接失效反馈官方服务:
资源简介:
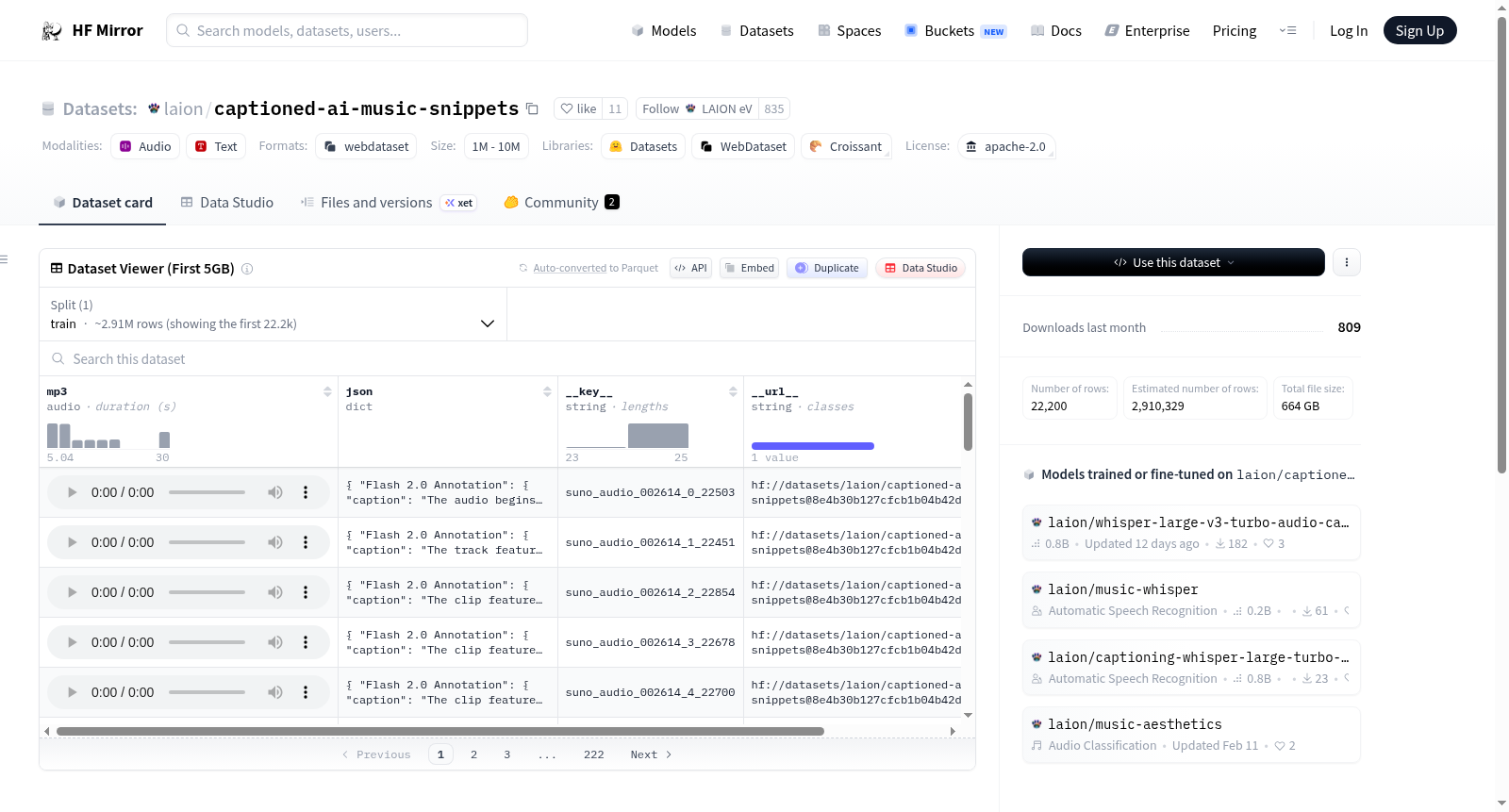
这是一个由3到30秒的短音频片段组成的集合,这些片段是从公开共享的Suno生成的歌曲中提取的,并使用Gemini Flash 2.0进行了高质量的音频描述标注。该数据集旨在用于训练和评估音频字幕模型。
This is a collection of short audio snippets (3-30 seconds) extracted from publicly shared Suno-generated songs and captioned with Gemini Flash 2.0 for high-quality audio descriptions. The dataset is designed for training and evaluating audio captioning models.
提供机构:
laion
搜集汇总
数据集介绍
构建方式
该数据集源自公开共享的Suno生成歌曲,从nyuuzyou/suno存储库中随机截取时长3至30秒的音频片段,并利用Gemini Flash 2.0模型为每个片段生成高质量、具有人类可读性的音频描述性标注,从而构建出面向音频字幕模型训练与评估的语料库。
特点
数据集涵盖多样化的AI生成音乐片段,标注信息由先进大语言模型自动生成,确保了描述的自然性与一致性。每个样本短小精悍,便于模型高效学习音频与文本之间的映射关系,同时采用Apache 2.0许可协议,为学术研究与商业应用提供了开放的资源基础。
使用方法
该数据集适用于训练和评估音频字幕生成模型,用户可直接加载音频片段及其对应的文本描述,用于监督学习任务。在应用时,可将音频特征提取后与描述文本对齐,构建序列到序列模型,或作为音频理解任务的基准测试集,评估模型对音乐内容语义的捕捉能力。
背景与挑战
背景概述
在人工智能生成内容(AIGC)迅猛发展的浪潮中,音乐生成模型如Suno已能产出大量富有表现力的音频片段,然而对这些非结构化音频内容的高效语义理解与自动描述仍是一个亟待开拓的领域。在此背景下,LAION社区于2024年发布了名为laion/captioned-ai-music-snippets的数据集,该数据集由nyuuzyou/suno仓库中公开共享的Suno生成歌曲中随机截取的短音频片段(时长3至30秒)构成,并借助Gemini Flash 2.0模型为每个片段生成了高质量、人类可读的音频描述。这一开创性工作聚焦于解决自动音频描述(Audio Captioning)的核心研究问题,即为机器生成的音乐内容建立语义标签与文本描述之间的映射桥梁。数据集采用Apache 2.0许可协议发布,旨在为全球研究者提供训练和评估音频描述模型的标准化基准,其影响力不仅推动了AIGC内容管理、音乐检索与智能标注技术的发展,也为多模态学习在音乐领域的应用奠定了数据基础。
当前挑战
该数据集所面临的挑战首先体现在领域问题层面:自动音频描述任务需要模型从短时音频中精准捕捉旋律、节奏、音色、情感以及可能的歌词片段等复杂声学特征,并将其转化为连贯、准确的自然语言描述,这对跨模态对齐与细粒度语义理解提出了极高要求。其次,在构建过程中,由于音频片段来源于AI生成音乐,其风格多样且可能包含非典型声学模式,使得从Gemini Flash 2.0获取的标注可能出现描述偏差或遗漏;同时,随机截取的方式可能导致部分片段缺乏完整音乐结构,增加了标注难度。此外,数据集规模有限且仅涵盖Suno单一来源,可能限制了模型对更广泛音乐类型的泛化能力,而标注过程依赖自动模型而非人工校验,也引入了潜在噪声与一致性不足的问题,这些因素共同构成了当前研究与应用的显著障碍。
常用场景
经典使用场景
该数据集由从Suno生成的公开音乐作品中截取的短音频片段(3至30秒)构成,并经由Gemini Flash 2.0模型生成高质量、可读性强的文字描述。其经典使用场景在于训练和评估音频字幕生成模型,即自动将音频内容转化为自然语言描述的任务。研究者可利用这些配对的音频-文本数据,构建能够理解音乐结构、乐器编排、情感氛围及节奏变化的深度学习系统,从而推动音频理解与生成领域的交叉发展。
实际应用
在实际应用中,该数据集可赋能音乐内容管理平台,实现基于自然语言查询的音频检索功能,例如用户输入“欢快的钢琴旋律”即可匹配相应片段。此外,它还能辅助音乐教育中的自动点评系统,为学习者提供即时的风格与结构反馈。在辅助创作领域,结合生成式模型,该数据集可用于开发智能配乐工具,根据文字描述自动生成或推荐匹配的音乐片段,提升内容创作效率与体验。
衍生相关工作
该数据集衍生出一系列经典工作,包括基于对比学习的音频-文本对齐模型,如CLAP的变体,用于提升跨模态检索精度;以及基于Transformer架构的端到端音频字幕生成模型,如引入注意力机制的音乐描述网络。此外,研究者还利用该数据集的标注特性,探索了音频驱动的文本到音乐生成任务,通过逆向映射实现从文字描述到音乐信号的合成,进一步拓展了生成式AI在音乐领域的应用边界。
以上内容由遇见数据集搜集并总结生成


