katanaml/cord
收藏Hugging Face2022-03-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/katanaml/cord
下载链接
链接失效反馈官方服务:
资源简介:
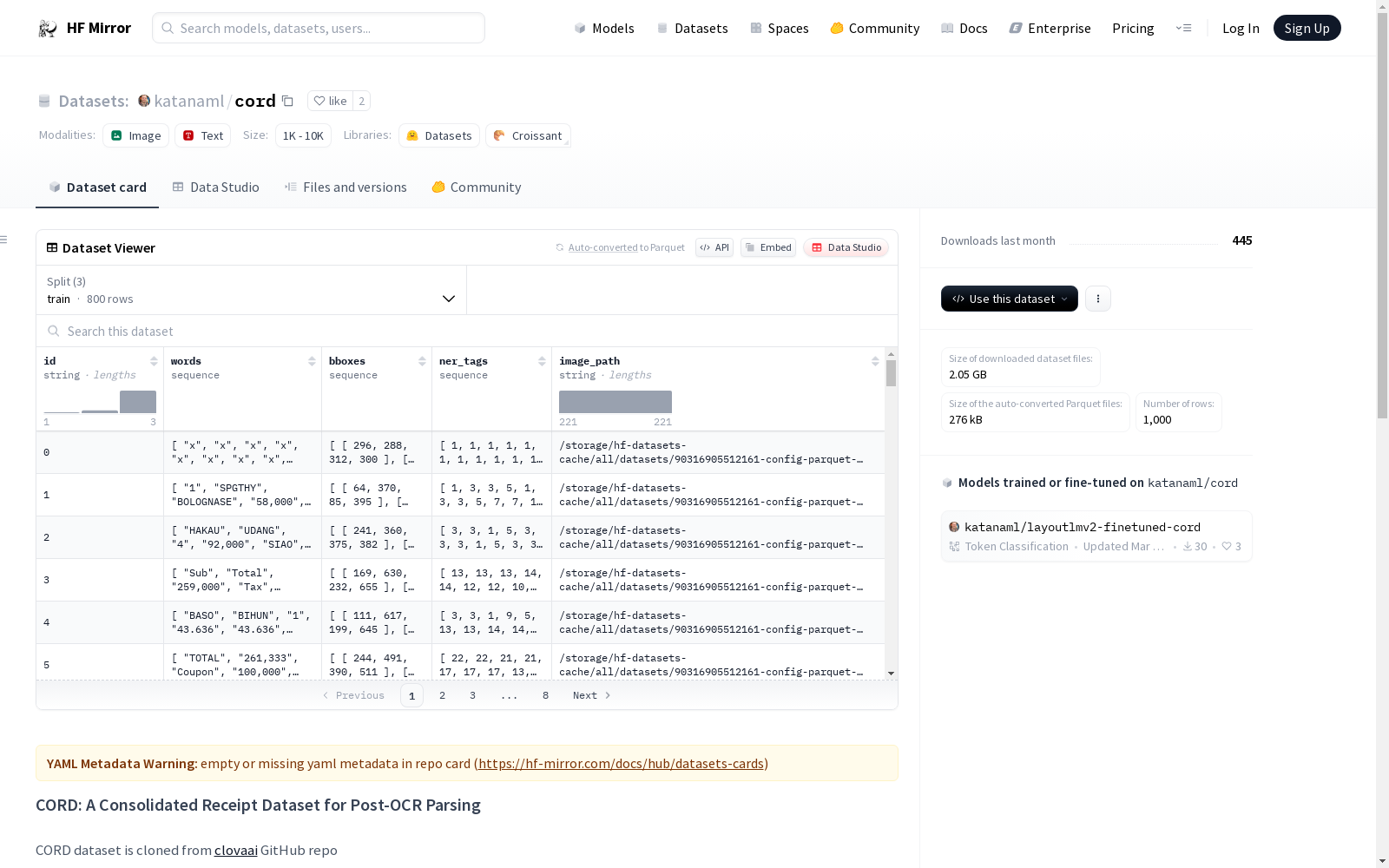
CORD数据集是一个用于后OCR解析的收据数据集,其框坐标相对于图像的宽度和高度进行了归一化处理。对于出现频率较低的标签,数据集进行了替换处理,例如将menu.etc、menu.itemsubtotal等标签替换为O。该数据集最初是从clovaai的GitHub仓库克隆而来。
The CORD dataset is a receipt dataset intended for post-OCR parsing, where all bounding box coordinates are normalized relative to the width and height of the source image. For infrequent labels, the dataset applies label replacement: for example, labels such as menu.etc and menu.itemsubtotal are replaced with O. This dataset was originally cloned from the GitHub repository of clovaai.
提供机构:
katanaml
原始信息汇总
CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
数据集概述
- 名称: CORD
- 来源: 克隆自 clovaai GitHub 仓库
- 特点:
- 框坐标相对于图像的宽度和高度进行了标准化处理。
- 出现频率极低的标签被替换为 O。
替换标签列表
- menu.etc
- menu.itemsubtotal
- menu.sub_etc
- menu.sub_unitprice
- menu.vatyn
- void_menu.nm
- void_menu.price
- sub_total.othersvc_price
引用信息
CORD: A Consolidated Receipt Dataset for Post-OCR Parsing
@article{park2019cord, title={CORD: A Consolidated Receipt Dataset for Post-OCR Parsing}, author={Park, Seunghyun and Shin, Seung and Lee, Bado and Lee, Junyeop and Surh, Jaeheung and Seo, Minjoon and Lee, Hwalsuk}, booktitle={Document Intelligence Workshop at Neural Information Processing Systems}, year={2019} }
Post-OCR parsing: building simple and robust parser via BIO tagging
@article{hwang2019post, title={Post-OCR parsing: building simple and robust parser via BIO tagging}, author={Hwang, Wonseok and Kim, Seonghyeon and Yim, Jinyeong and Seo, Minjoon and Park, Seunghyun and Park, Sungrae and Lee, Junyeop and Lee, Bado and Lee, Hwalsuk}, booktitle={Document Intelligence Workshop at Neural Information Processing Systems}, year={2019} }
搜集汇总
数据集介绍
构建方式
CORD数据集的构建,旨在为后OCR解析提供统一格式的收据数据。该数据集从clovaai的GitHub仓库克隆而来,通过将框坐标归一化至图像的宽高比例,以及将出现频率极低的标签统一替换为'O:',实现了数据的一致性和标准化处理。
特点
CORD数据集的特点在于其数据的一致性和标准化,为后OCR解析任务提供了便利。数据集包含的标签类别经过精简,去除了罕见标签,使得模型训练更为高效。此外,CORD数据集的构建考虑到了实际应用场景,为研究者提供了丰富的实例和挑战。
使用方法
使用CORD数据集时,研究者可以通过引用相关文献来了解数据集的详细构建过程和特点。具体使用时,可以按照Sparrow项目中的指引进行,该项目为数据集的使用提供了详细的说明和示例。数据集的标准化处理使得其易于集成到现有的后OCR解析框架中。
背景与挑战
背景概述
在文档解析领域,光学字符识别(OCR)后的文本解析是关键一环。CORD数据集,全称为Consolidated Receipt Dataset,由韩国高级科学技术研究院(KAIST)的研究人员于2019年创建,旨在为后OCR解析研究提供统一和综合的收据数据集。该数据集的核心研究问题是提高解析算法的准确性和鲁棒性,以应对实际场景中收据格式和内容的多样性。CORD数据集的发布,对文档解析和自然语言处理领域产生了深远影响,推动了相关技术的发展和应用。
当前挑战
CORD数据集在构建过程中面临了诸多挑战。首先,数据集需涵盖多种收据格式和布局,这要求在数据采集和标注过程中保证样本的多样性和代表性。其次,由于收据中存在大量的类别标签,数据集中对出现频率较低的标签进行了合并处理,以减少模型训练的复杂性。此外,后OCR解析领域的问题挑战包括如何准确识别和解析收据中的细粒度信息,如商品名称、价格、税额等,这些信息往往伴随着不同的格式和表述方式,增加了解析的难度。
常用场景
经典使用场景
在文献解析与信息提取的领域内,CORD数据集以其全面且规范化的收据格式,成为后OCR解析任务中的经典使用案例。该数据集通过提供标准化的框坐标以及类别标签,支持研究者开展对收据图像的细粒度识别与理解工作,进而提高解析的准确性。
解决学术问题
CORD数据集解决了学术研究中,特别是在后OCR处理阶段,对于收据等文档解析时遇到的分类不一致、标注信息缺失等问题。它为研究者提供了一个统一标注的基准,有助于模型泛化能力的提升,并为评估不同解析算法的性能提供了可靠的标准。
衍生相关工作
基于CORD数据集,学术界衍生出了诸多经典工作,如构建简单健壮的解析器通过BIO标记方法,以及提出各种高效的后OCR解析框架。这些工作不仅推动了文档解析技术的进步,也为相关领域的理论研究和实践应用提供了新的视角和方法论。
以上内容由遇见数据集搜集并总结生成


