lm-diagnostics-negsimp
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/SebastiaanBeekman/lm-diagnostics-negsimp
下载链接
链接失效反馈官方服务:
资源简介:
LM Diagnostics (cprag)是一个心理语言学诊断数据集,用于研究语言模型在生成预测时使用的信息。该数据集通过一系列源自人类语言实验的诊断,对语言模型在上下文中生成预测的能力提出针对性问题。以BERT模型为案例,研究发现该模型能够区分涉及共享类别或角色反转的好坏完成度,但相较于人类,其敏感性较低;它能稳健地检索名词上位词,但在处理具有挑战性的推理和基于角色的事件预测方面存在困难,尤其是在否定语境的影响下表现出明显的敏感性不足。
LM Diagnostics (cprag) is a psycholinguistic diagnostic dataset designed to investigate the information that language models utilize when generating predictions. This dataset poses targeted questions about the predictive generation abilities of language models in contextual settings, using a suite of diagnostics derived from human psycholinguistic experiments. Taking BERT as a case study, research has found that the model can distinguish between well-formed and ill-formed completions involving shared categories or role reversals, but exhibits lower sensitivity than human subjects. It can robustly retrieve hypernyms of nouns, yet struggles with challenging reasoning and role-based event prediction tasks, particularly showing marked insensitivity when processing negative contextual cues.
创建时间:
2025-09-03
原始信息汇总
数据集概述
基本信息
- 名称:LM Diagnostics (cprag) Clone
- 许可证:MIT License
- 语言:英语(en)
- 数据规模:小于1K样本(n<1K)
来源与背景
- 该数据集是用于语言模型诊断的测试集(cprag),源自Allyson Ettinger的研究论文《What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models》。
- 旨在通过心理语言学诊断工具评估语言模型(如BERT)的 linguistic capacities,特别是对否定语境(negation)的敏感性。
主要用途
- 评估语言模型在上下文预测中的信息使用能力,包括但不限于:
- 区分共享类别或角色反转的完成质量
- 名词上位词检索
- 挑战性推理和基于角色的事件预测
- 对否定语境影响的敏感性检测
引用信息
- 论文标题:What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models
- 作者:Ettinger, Allyson
- 期刊:Transactions of the Association for Computational Linguistics
- 年份:2020
- DOI:https://doi.org/10.1162/tacl_a_00298
搜集汇总
数据集介绍
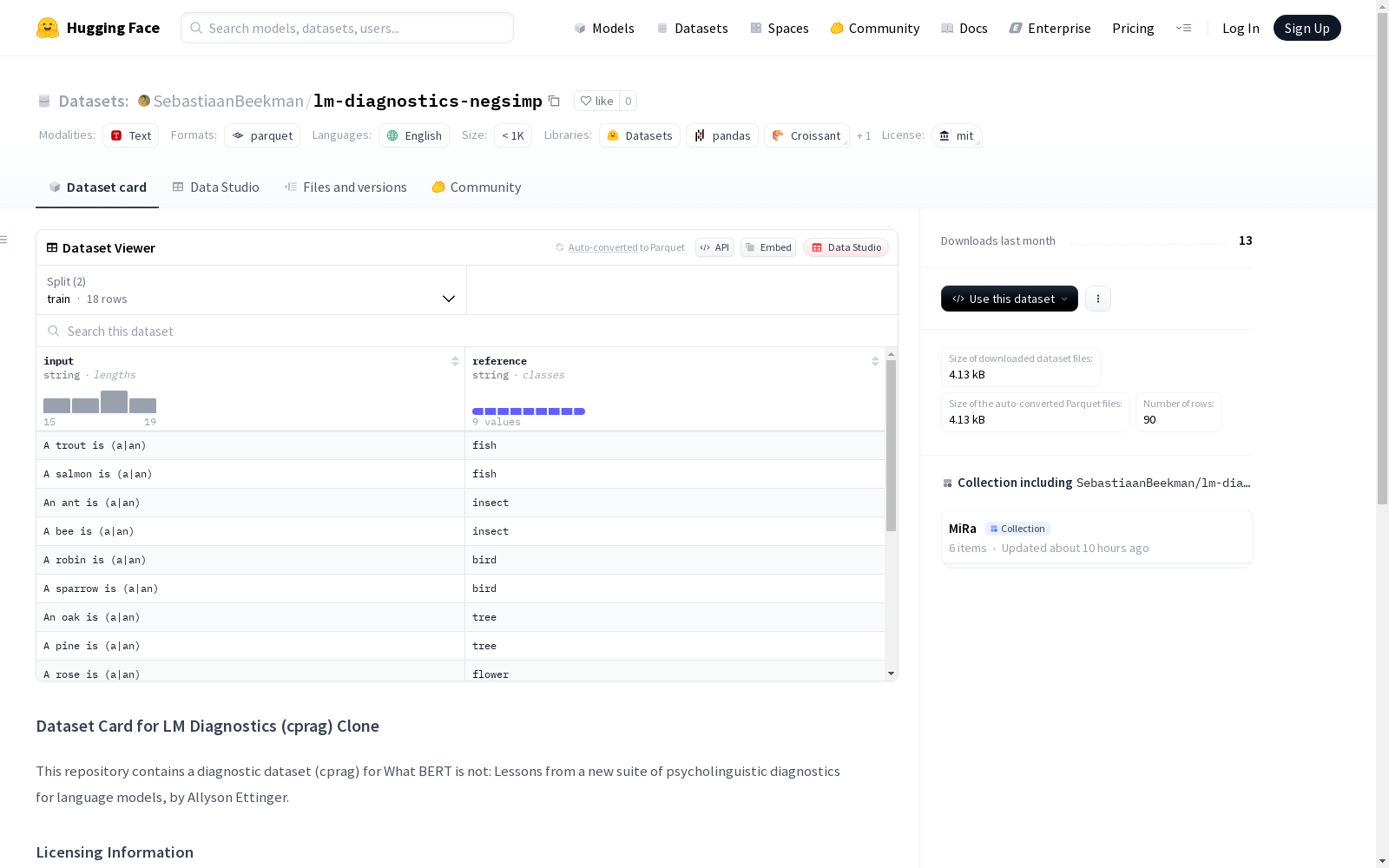
构建方式
在心理语言学与计算语言学的交叉领域,lm-diagnostics-negsimp数据集通过精心设计的诊断任务构建而成。该数据集基于人类语言实验范式,针对语言模型在否定语境下的理解能力设计测试项目,采用控制变量法生成正负例样本,确保每项测试均聚焦于特定语言现象。数据构建过程严格遵循实验语言学原则,通过对比完整句与否定变体,系统评估模型对否定语义的敏感性。
特点
该数据集的核心特征在于其高度靶向性的诊断设计,专门揭示语言模型对否定结构的处理缺陷。数据集包含精心控制的对比样本,其中否定词引发的语义反转构成关键测试维度。样本规模虽不足千条,但每条数据均承载着特定的语言学诊断目标,能够有效探测模型在语义推理、角色预测和语境适应等方面的表现。其设计充分体现了心理语言学实验的严谨性与计算诊断的精确性。
使用方法
研究人员可将该数据集作为标准化的评估工具,用于检验语言模型对否定结构的语义理解能力。典型使用方式是通过对比模型在原始句与否定变体上的预测差异,量化其否定敏感性指标。建议在模型微调或零样本评估场景下,系统分析模型完成否定句补全任务的表现。数据集提供的诊断结果可用于指导模型改进,特别是在增强语境推理与语义理解方面提供实证依据。
背景与挑战
背景概述
语言模型诊断数据集(lm-diagnostics-negsimp)由Allyson Ettinger于2020年提出,旨在系统评估预训练语言模型的心理语言学能力。该数据集基于认知科学实验设计,聚焦于模型在上下文预测中对否定、推理及事件角色等复杂语言现象的处理机制。作为BERT等主流模型的重要评测工具,它推动了计算语言学与心理语言学的跨学科融合,为模型可解释性研究提供了关键数据支撑。
当前挑战
该数据集核心挑战在于检测语言模型对否定结构的敏感性缺失问题,例如模型需区分“医生治愈患者”与“医生未治愈患者”的语义差异。构建过程中需克服心理语言学实验范式向机器学习任务的转化难题,包括控制词汇频率、句法复杂度等混淆变量,并确保诊断项兼具科学严谨性与计算可操作性。
常用场景
经典使用场景
在心理语言学与计算语言学的交叉领域,lm-diagnostics-negsimp数据集被广泛用于评估预训练语言模型对否定结构的敏感性。研究者通过设计包含否定转换的句子对,检验模型在上下文推理中是否能够准确捕捉否定词带来的语义反转,这一场景深刻揭示了模型对逻辑运算符的隐含处理机制。
解决学术问题
该数据集解决了预训练语言模型在否定推理方面的评估空白,通过量化模型对否定语境的理解偏差,为解释模型内部表征的局限性提供了实证基础。其意义在于推动了语言模型可解释性研究,促使研究者开发更具逻辑一致性的神经网络架构,弥补形式逻辑与统计学习之间的鸿沟。
衍生相关工作
基于该数据集衍生的经典研究包括对BERT、RoBERTa等模型的系统性诊断框架,如《Negated LAMA》探针实验揭示了模型知识检索中的否定盲区。后续工作进一步扩展到多语言否定评估,推动了HELM等综合性评估基准的构建,为模型鲁棒性研究提供了关键范式。
以上内容由遇见数据集搜集并总结生成


