HumAID
收藏arXiv2021-04-08 更新2024-06-21 收录
下载链接:
https://crisisnlp.qcri.org/humaid_dataset.html
下载链接
链接失效反馈官方服务:
资源简介:
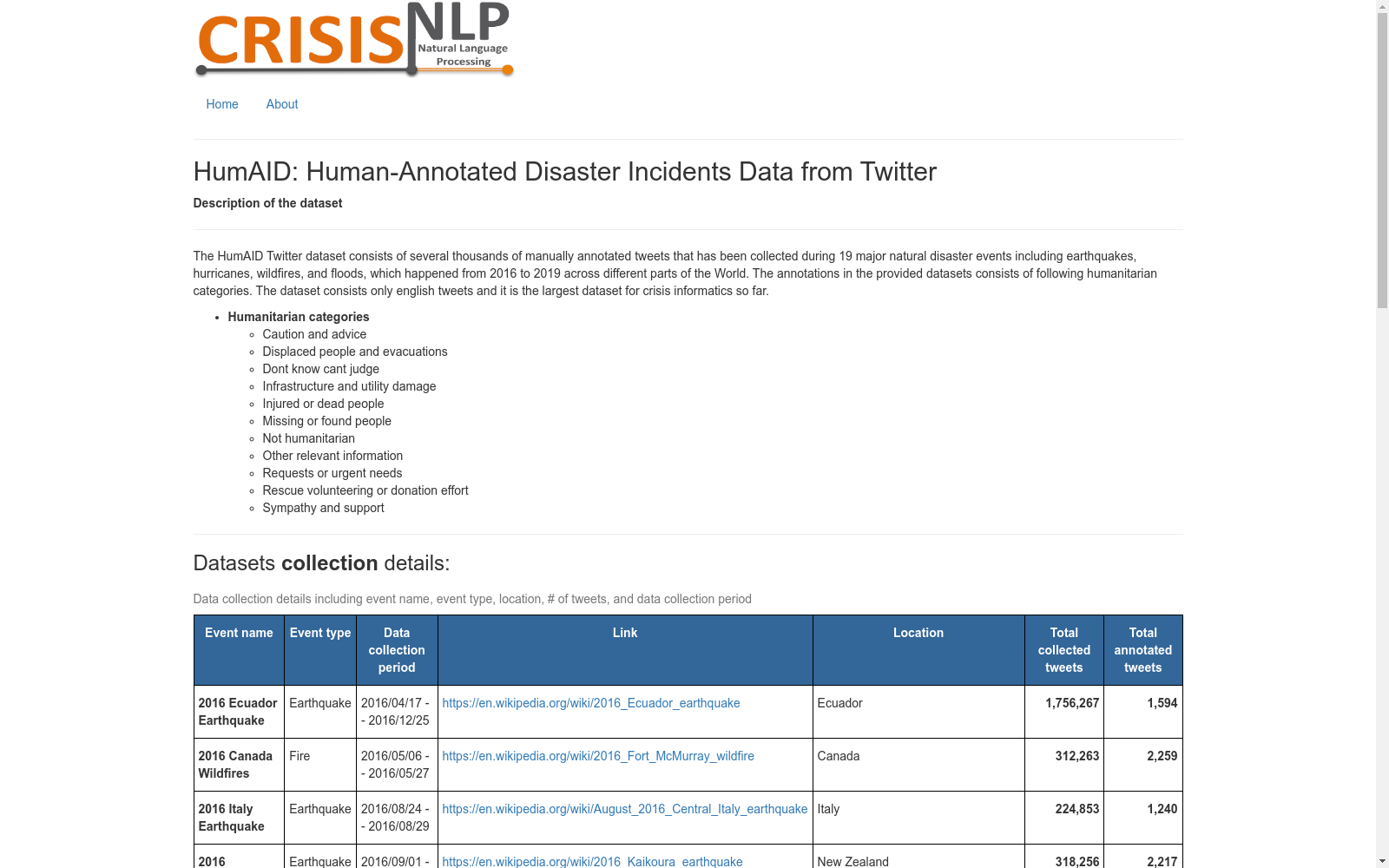
HumAID是由卡塔尔计算研究机构创建的大规模人类标注灾难事件数据集,包含约77,000条从2016至2019年间发生的19个灾难事件中抽取的推文。数据集内容涵盖多种灾难类型,如飓风、地震、野火和洪水,旨在为深度学习模型提供丰富的训练资源,以支持危机信息学研究。数据集通过精细的数据过滤和采样流程创建,确保了数据的质量和多样性,适用于训练能够理解和分类灾难相关信息的模型,以辅助人道主义组织在灾难发生时做出快速反应。
HumAID is a large-scale human-annotated disaster event dataset created by the Qatar Computing Research Institute. It contains approximately 77,000 tweets extracted from 19 disaster events that occurred between 2016 and 2019. The dataset covers a variety of disaster types including hurricanes, earthquakes, wildfires and floods. Its core purpose is to provide rich training resources for deep learning models to support crisis informatics research. Developed through meticulous data filtering and sampling processes, the dataset ensures data quality and diversity, and is suitable for training models that can understand and classify disaster-related information to assist humanitarian organizations in making rapid responses during disasters.
提供机构:
卡塔尔计算研究机构
创建时间:
2021-04-07
搜集汇总
数据集介绍
构建方式
HumAID数据集的构建方法主要分为数据收集、过滤、采样和人工标注四个步骤。首先,研究者使用AIDR系统通过Twitter的流式API收集了2016年至2019年间发生的19次主要真实世界灾难期间的大约2400万条推文。接着,为了提高标注数据的质量,研究者进行了数据过滤,包括基于日期、位置、语言、分类器和词数等维度的筛选。最后,通过亚马逊Mechanical Turk平台进行人工标注,标注内容包括警告和建议、同情和支持、请求或紧急需求、流离失所者和疏散、受伤或死亡人员、失踪或找到的人员、基础设施和公用事业损害、救援、志愿者或捐赠活动、其他相关信息、非人道主义以及无法判断或不知道等11个类别。为了确保标注质量,研究者设置了资格测试和金标准评估,并要求标注者之间的标签一致性达到66%。
特点
HumAID数据集具有以下特点:一是规模大,包含约77,000条人工标注的推文;二是覆盖面广,涵盖了不同类型、不同时间段和不同地点的灾难事件;三是数据平衡性好,各类别的标注数量相对均衡;四是数据质量高,经过精心设计的数据过滤和采样流程确保了推文来源于灾难发生地,并尽可能多地包含了来自目击者或受影响个体的有用信息;五是标注体系全面,包含了11个类别,代表了多个人道主义组织在自然灾害期间的关键信息需求;六是与现有数据集相比,HumAID是危机信息学领域中最大的数据集。
使用方法
HumAID数据集的使用方法包括以下步骤:首先,用户可以从HumAID数据集的官方网站下载数据集和相关的资源;其次,用户可以根据自己的研究需求选择合适的标注类别进行数据筛选;然后,用户可以使用经典算法(如SVM和RF)或深度学习算法(如fastText和基于transformer的模型)进行模型训练和评估;最后,用户可以参考论文中提供的基准结果,对自己的模型性能进行评估和比较。为了方便用户使用,HumAID数据集提供了训练集、开发集和测试集的划分,并确保了数据的一致性和可比性。
背景与挑战
背景概述
HumAID数据集是一项重要的研究成果,旨在解决紧急情况下社交媒体内容的高噪声问题。该数据集由卡塔尔计算研究所的研究团队创建,时间跨度从2016年至2019年。其主要研究人员包括Firoj Alam、Umair Qazi、Muhammad Imran和Ferda Oflazer。HumAID数据集的核心研究问题是开发一个大规模、高质量的人标注数据集,以支持先进的深度学习模型在危机信息学领域的应用。该数据集的创建对相关领域产生了深远的影响,为研究人员提供了一个强大的基准,以评估和比较不同模型的性能,并推动危机信息学研究的进一步发展。
当前挑战
HumAID数据集面临的主要挑战包括数据收集和标注过程中的挑战。首先,社交媒体内容的高噪声特性使得从海量数据中提取有用信息变得困难。其次,构建大规模人标注数据集需要大量的时间和资源,尤其是在数据标注阶段。此外,由于社交媒体内容的多样性和主观性,确保标注的一致性和准确性也是一个挑战。最后,随着社交媒体平台和技术的不断发展,如何保持数据集的时效性和相关性也是一个长期挑战。
常用场景
经典使用场景
HumAID数据集在危机信息学领域有着广泛的应用前景。其最经典的使用场景是作为自然语言处理模型的训练数据,特别是在灾害事件中,利用HumAID数据集训练的模型可以帮助决策者快速有效地筛选、分类和总结社交媒体上的内容,从而促进有效的信息消费和决策。此外,HumAID数据集还可以用于评估和比较不同机器学习算法的性能,为危机信息学的研究提供可靠的基准。
解决学术问题
HumAID数据集解决了现有数据集在规模、多样性和标注一致性方面的不足。现有的灾害相关数据集往往规模较小,包含重复内容,且较少支持深度学习模型的发展。HumAID数据集包含了约77,000条人工标注的推文,涵盖了19次真实世界的大规模灾害事件,包括飓风、地震、野火和洪水等。此外,HumAID数据集还采用了精心设计的数据过滤和采样流程,确保了数据的质量和多样性,为危机信息学的研究提供了重要的数据资源。
衍生相关工作
HumAID数据集的发布为危机信息学领域的研究提供了重要的数据资源。基于HumAID数据集,研究人员可以开展各种研究,例如,开发更先进的自然语言处理模型,用于灾害事件中的信息筛选、分类和总结;研究不同灾害事件中社交媒体信息的特征和规律;开发基于社交媒体信息的灾害预测和预警模型等。HumAID数据集的发布将推动危机信息学领域的研究向前发展,为灾害事件的应对和管理提供更加有效的技术支持。
以上内容由遇见数据集搜集并总结生成


