NuminaMath-Enhanced-CoT-JA-50K
收藏Hugging Face2025-01-13 更新2025-01-16 收录
下载链接:
https://huggingface.co/datasets/Inoichan/NuminaMath-Enhanced-CoT-JA-50K
下载链接
链接失效反馈官方服务:
资源简介:
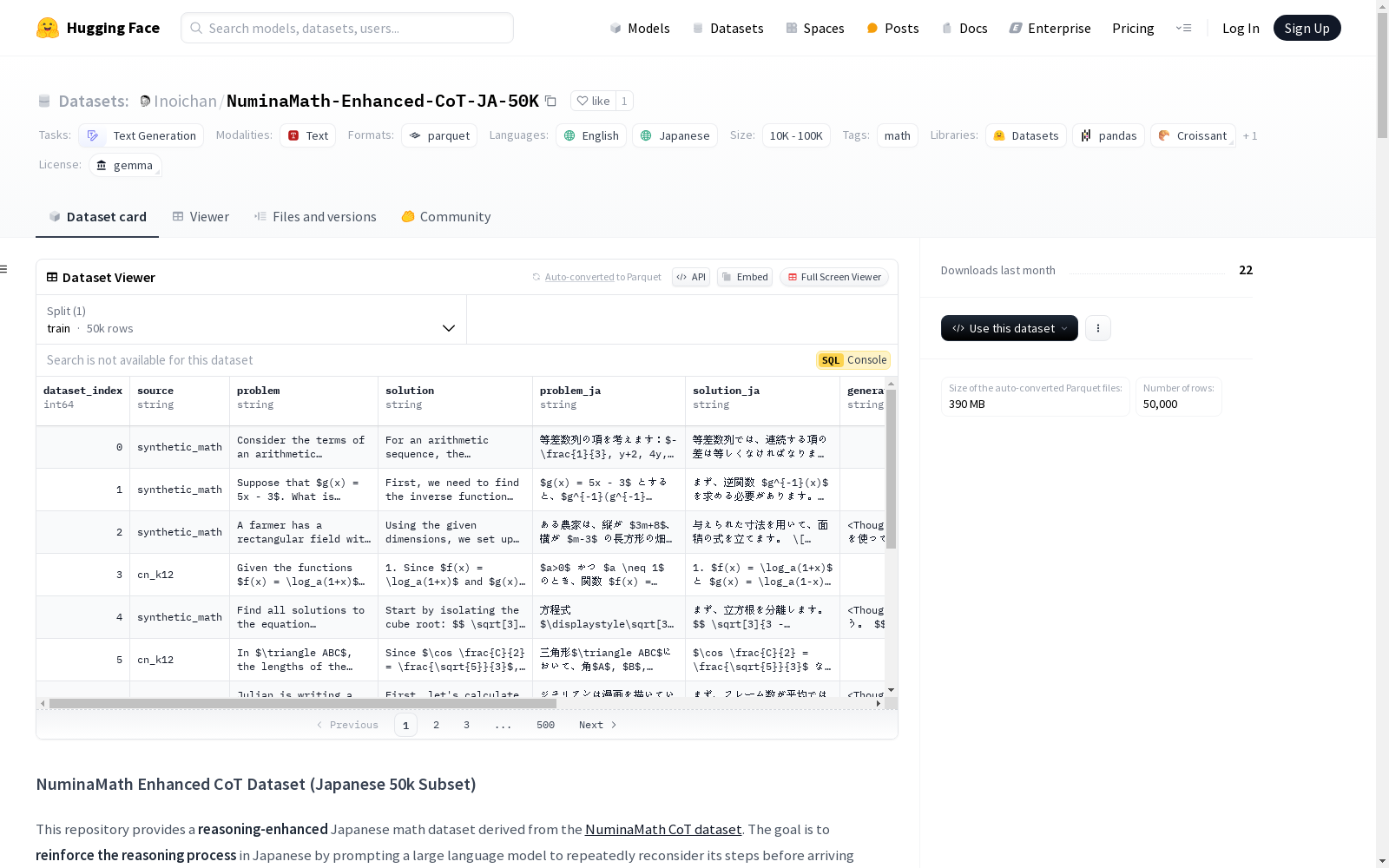
NuminaMath Enhanced CoT Dataset (Japanese 50k Subset) 是一个从NuminaMath CoT数据集派生出来的日语数学数据集,旨在通过让大型语言模型反复思考其步骤来加强日语中的推理过程。该数据集包含50,000个样本,每个样本的英文数学问题和解决方案被翻译成日语,并通过模型生成四个日语解决方案。数据集的结构包括原始问题的索引、来源、英文问题和解决方案、日文翻译问题和解决方案、生成的解决方案以及所有四个生成的解决方案。数据集的生成过程涉及使用google/gemma-2-27b-it模型进行多次推理尝试,并通过精确匹配检查来确定最佳解决方案。数据集的使用受到Apache License 2.0和Gemma使用条款的限制。
The NuminaMath Enhanced CoT Dataset (Japanese 50k Subset) is a Japanese mathematical dataset derived from the NuminaMath CoT Dataset, designed to enhance reasoning processes in Japanese by having large language models repeatedly deliberate over their solution steps. This dataset contains 50,000 samples: for each sample, the original English mathematical problem and its corresponding solution are translated into Japanese, and four Japanese-language solutions are generated via models. The dataset structure includes the index of the original problem, its source, the English problem and solution, the Japanese-translated problem and solution, the optimal generated solution, and all four of the initially generated solutions. The dataset generation process involves using the google/gemma-2-27b-it model to perform multiple rounds of reasoning attempts, and identifying the optimal solution through exact match validation. The usage of this dataset is governed by the Apache License 2.0 and the Gemma Terms of Service.
创建时间:
2025-01-05
搜集汇总
数据集介绍
构建方式
NuminaMath-Enhanced-CoT-JA-50K数据集的构建基于NuminaMath CoT数据集,该数据集包含英文数学问题及其链式思维(CoT)解答。通过使用大型语言模型(如google/gemma-2-27b-it),每个英文问题及其解答被生成四次日文解答,并通过精确字符串匹配筛选出与原始解答最终答案一致的日文解答。若四次生成中无匹配结果,则保留所有生成的解答以供进一步分析。
使用方法
该数据集适用于数学推理模型的训练与评估,尤其适用于日文语境下的多步推理任务。用户可通过`problem_ja`和`solution_ja`字段获取日文问题及其解答,并通过`generated_solution`字段获取匹配成功的日文解答。若未匹配成功,用户可参考`all_solutions`字段中的四次生成结果进行手动分析。数据集的使用需遵守Apache License 2.0及Gemma使用条款。
背景与挑战
背景概述
NuminaMath-Enhanced-CoT-JA-50K数据集是基于NuminaMath CoT数据集的一个增强版本,专注于日语数学问题的多步推理过程。该数据集由Yuichi Inoue于2025年创建,旨在通过大型语言模型的反复推理能力,强化日语数学问题中的反思性推理。数据集的核心研究问题在于如何通过迭代反思提升模型在解决复杂数学问题时的准确性和逻辑一致性。该数据集不仅为日语数学教育提供了宝贵的资源,还为自然语言处理领域中的推理模型研究开辟了新的方向。
当前挑战
NuminaMath-Enhanced-CoT-JA-50K数据集在构建过程中面临多重挑战。首先,数据集的生成依赖于对原始英语问题的精确翻译和推理步骤的反复生成,这导致了翻译质量和推理一致性的问题。其次,由于依赖于字符串匹配的精确性,格式上的微小差异可能导致匹配失败,进而影响数据的可用性。此外,数据集仅涵盖了原始数据集的前50,000个样本,可能存在样本分布不均或代表性不足的问题。最后,大型语言模型在生成过程中偶尔会产生矛盾或不合理的推理步骤,尽管引入了反思机制,但仍无法完全保证推理的正确性和一致性。
常用场景
经典使用场景
NuminaMath-Enhanced-CoT-JA-50K数据集在数学推理领域具有广泛的应用,尤其是在多步推理和反思性推理的研究中。该数据集通过将英语数学问题及其链式推理(CoT)解决方案翻译为日语,并引入多次生成和反思机制,显著提升了模型在日语环境下的推理能力。经典的使用场景包括数学问题的自动解答、多步推理模型的训练与评估,以及跨语言推理能力的比较研究。
解决学术问题
该数据集解决了数学推理模型在跨语言环境下的表现问题,尤其是日语环境中的多步推理和反思性推理。通过引入多次生成和反思机制,数据集不仅增强了模型在复杂数学问题上的推理能力,还为研究多步推理的准确性和一致性提供了丰富的实验数据。这一数据集的出现填补了日语数学推理数据集的空白,推动了跨语言推理模型的研究进展。
实际应用
在实际应用中,NuminaMath-Enhanced-CoT-JA-50K数据集可用于开发智能教育系统,帮助日语学习者更好地理解和解决复杂的数学问题。此外,该数据集还可用于构建多语言数学推理助手,支持跨语言的数学问题解答和推理过程展示。通过提供详细的反思性推理步骤,数据集为教育技术领域的创新应用提供了有力支持。
数据集最近研究
最新研究方向
近年来,随着大语言模型在数学推理任务中的广泛应用,NuminaMath-Enhanced-CoT-JA-50K数据集在数学问题求解领域引起了广泛关注。该数据集通过增强多步反思推理能力,特别针对日语环境下的数学问题求解进行了优化。其核心在于通过反复提示模型重新审视推理步骤,从而提升模型的反思能力。这一研究方向与当前大语言模型在复杂推理任务中的表现密切相关,尤其是在开放性问题求解和跨语言推理领域。该数据集不仅为日语数学问题的自动化求解提供了新的资源,还为研究多语言环境下的推理模型提供了重要的实验基础。未来,结合语义匹配和近似推理技术,该数据集有望在数学教育、自动解题系统等领域发挥更大的作用。
以上内容由遇见数据集搜集并总结生成


