DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5
收藏Hugging Face2025-07-25 更新2025-07-26 收录
下载链接:
https://huggingface.co/datasets/teamcore/DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5
下载链接
链接失效反馈官方服务:
资源简介:
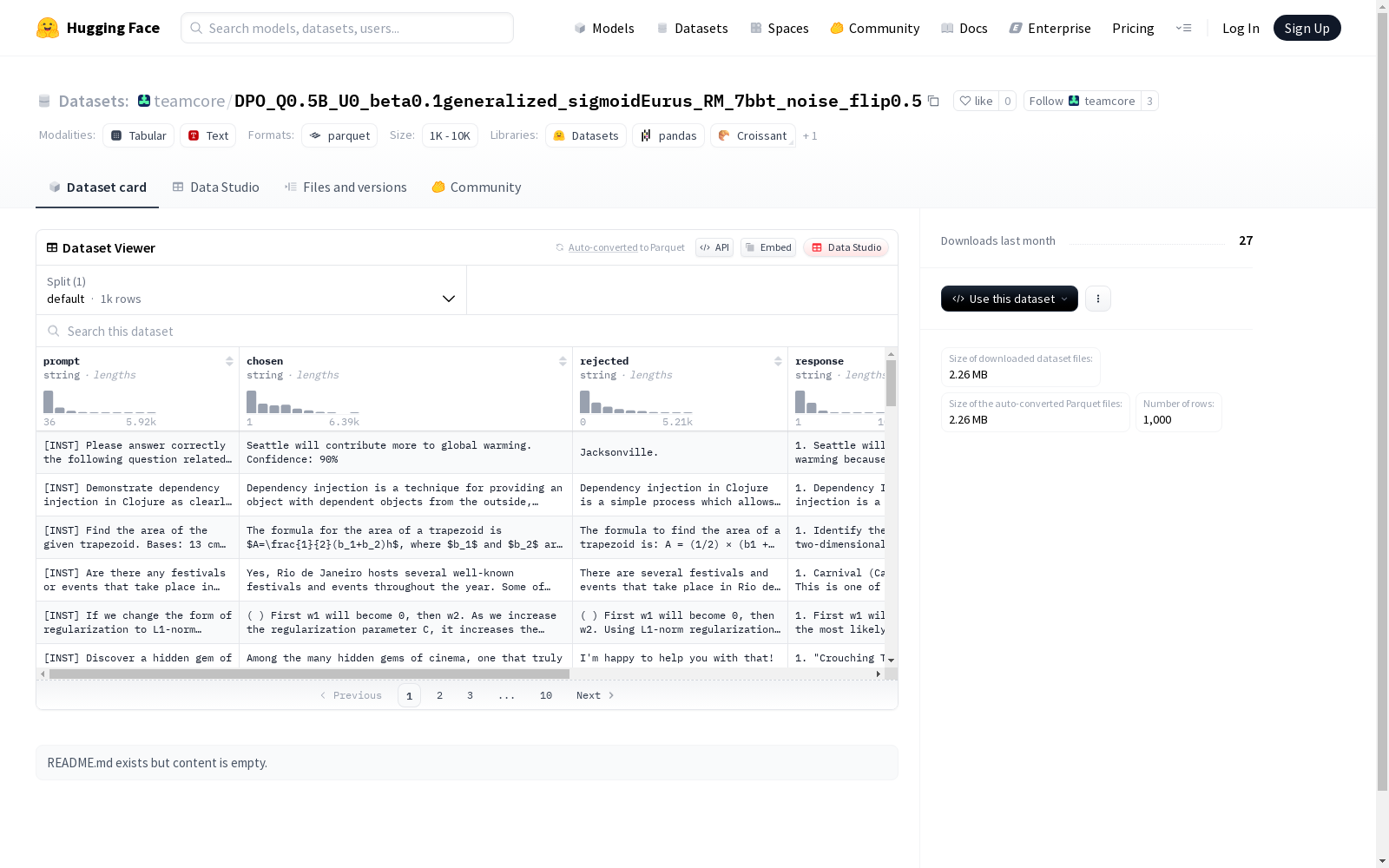
该数据集包含了提示(prompt)、选择(chosen)、拒绝(rejected)、回应(response)以及生成的奖励分数(reward_score_generated)和选择的奖励分数(reward_score_chosen)等字段。数据集分为default部分,共有1000个示例,数据集大小为4219142字节。
This dataset consists of fields such as prompt, chosen, rejected, response, reward_score_generated, and reward_score_chosen. It is partitioned into the default split, containing a total of 1000 examples, with an overall size of 4,219,142 bytes.
创建时间:
2025-07-24
原始信息汇总
数据集概述
基本信息
- 数据集名称: teamcore/DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5
- 配置名称: tag2
- 下载大小: 2256729 字节
- 数据集大小: 4219142 字节
- 示例数量: 1000
数据集特征
- prompt: 字符串类型
- chosen: 字符串类型
- rejected: 字符串类型
- response: 字符串类型
- reward_score_generated: 浮点数类型 (float64)
- reward_score_chosen: 浮点数类型 (float64)
数据分割
- 默认分割:
- 字节数: 4219142
- 示例数: 1000
- 数据文件路径: tag2/default-*
搜集汇总
数据集介绍
构建方式
在强化学习与偏好对齐研究领域,DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5数据集通过系统化数据采集流程构建,其核心框架包含prompt(输入指令)、chosen(优选响应)、rejected(劣选响应)三元组结构。构建过程中采用广义Sigmoid函数进行奖励建模,并引入0.5概率的噪声翻转机制以增强数据鲁棒性,最终形成包含1000个样本的高质量对比数据集。
特点
该数据集显著特征体现在多维度奖励评分体系,除常规文本对比较外,额外提供reward_score_generated(生成响应得分)和reward_score_chosen(优选响应得分)两个精细化评估指标。数据字段采用严格的类型标注,字符串与浮点数值分离存储,且通过7B参数规模的奖励模型进行质量验证,确保每个样本的对比有效性符合偏好对齐研究的实验需求。
使用方法
研究者可通过HuggingFace平台直接加载tag2配置下的default分片,数据以标准键值对形式组织。典型应用场景包括:通过prompt-response对进行指令微调,利用chosen-rejected对实施直接偏好优化(DPO),或结合双奖励分数开发新型强化学习算法。数据集内置的噪声机制特别适用于研究模型在对抗性环境中的稳定性表现。
背景与挑战
背景概述
DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5数据集是近年来在强化学习与自然语言处理交叉领域涌现的重要语料资源,由专业研究团队为优化对话系统奖励模型而构建。该数据集聚焦于通过直接偏好优化(DPO)方法解决生成文本的质量评估难题,其核心设计理念体现在对prompt-response配对的多维度人工标注,包括优选回复(chosen)、次选回复(rejected)及对应的奖励分数。数据结构的精巧设计反映了当前大语言模型微调范式从传统监督学习向人类反馈强化学习的范式转变,为对话系统的可控生成提供了关键基准。
当前挑战
该数据集面临的挑战主要体现在两个维度:在领域问题层面,如何准确量化文本生成的细微质量差异成为核心难点,现有奖励分数标注体系对语义连贯性、事实准确性和伦理合规性的多目标平衡尚未形成统一标准;在构建过程层面,噪声标签处理(noise_flip参数显示标注噪声达50%)与广义Sigmoid函数的奖励建模增加了数据清洗和特征工程的复杂度,且规模受限(仅1000样本)导致模型泛化能力验证存在瓶颈。这些挑战深刻反映了人类偏好数据标注的主观性与强化学习客观优化目标之间的本质矛盾。
常用场景
经典使用场景
在强化学习与偏好对齐研究中,DPO_Q0.5B_U0_beta0.1generalized_sigmoidEurus_RM_7bbt_noise_flip0.5数据集通过提供带有人工标注偏好的对话响应对,成为训练奖励模型和策略优化的基准工具。其结构化数据特别适合用于对比学习框架,研究者可通过分析chosen与rejected响应的奖励分数差异,量化不同策略的偏好满足程度。
实际应用
实际部署中,该数据集支撑着智能客服系统的响应质量优化。企业可利用其奖励评分数据构建在线学习管道,持续改进对话策略。在教育领域,基于该数据集训练的模型能自动评估学生作答的语义质量,为自适应学习系统提供实时反馈。
衍生相关工作
该数据集的发布催生了多项对话策略优化的创新研究。例如基于广义Sigmoid奖励建模的Eurus框架,通过引入噪声翻转机制提升了策略鲁棒性;7B参数模型在该数据上验证了大规模语言模型与人类偏好的对齐效率,相关成果已应用于开源对话系统开发。
以上内容由遇见数据集搜集并总结生成


