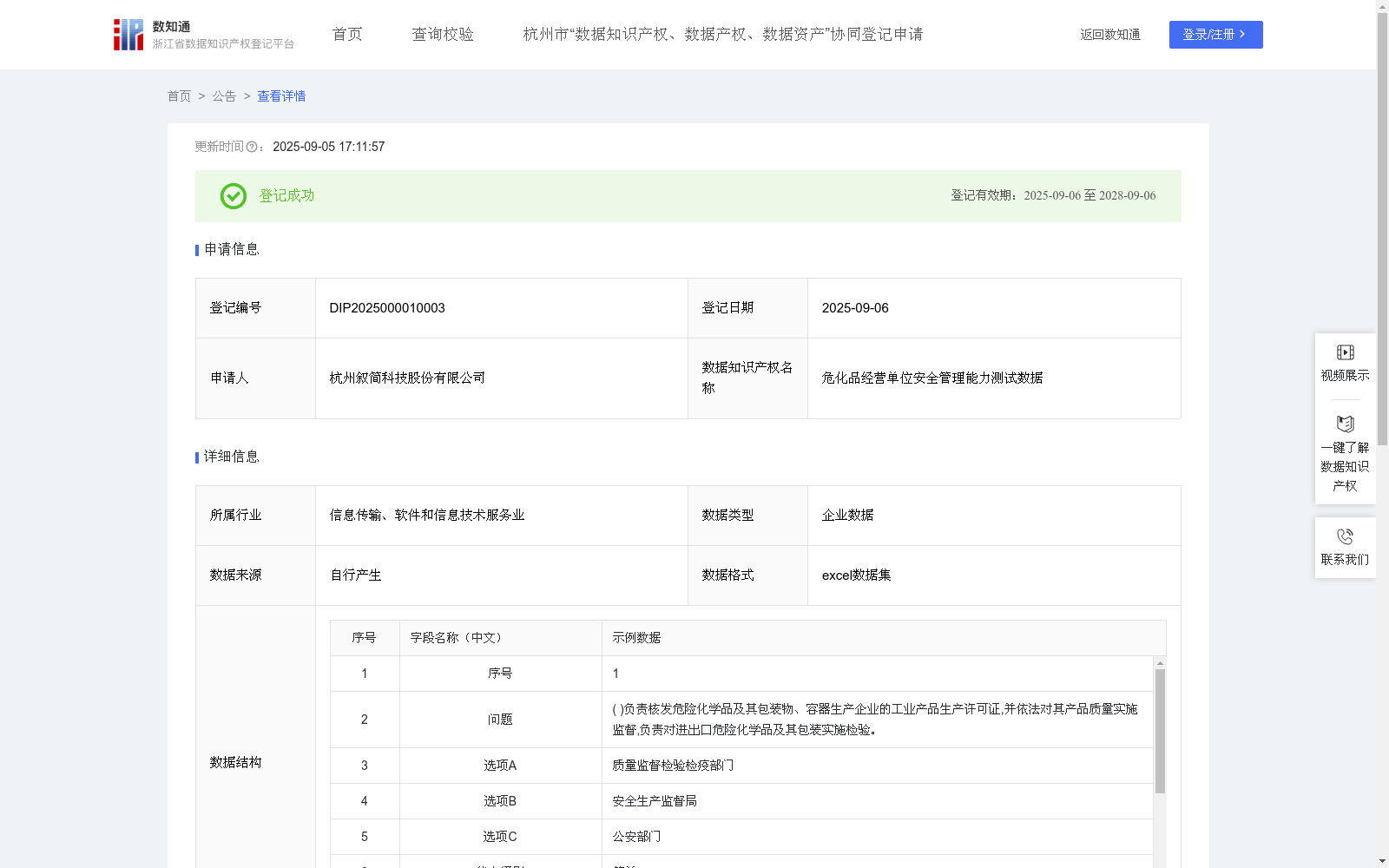
危化品经营单位安全管理能力测试数据
收藏浙江省数据知识产权登记平台2025-09-05 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/175809
下载链接
链接失效反馈官方服务:
资源简介:
通过对危化品经营单位安全管理领域知识测评数据进行上下文标注,形成具有高度针对性和语义复杂性的训练集。这些数据通过数据解析和安全合规验证,从而生成危化品经营单位安全管理领域的专业样本,为全面评估AI大模型的危化品经营单位安全管理知识提供了专业全面的测试样例,在危化品安全管理问答题解答中的语义理解能力、语言表达能力和思维推导能力评估,以及测试和提升危化品经营单位安全管理领域AI模型对场景理解的适用性。1.数据采集:采集《中华人民共和国安全生产法》《中华人民共和国消防法》《危险化学品安全管理条例》《危险化学品经营许可证管理办法》《使用有毒物品作业场所劳动保护条例》《生产安全事故报告和调查处理条例》《建筑设计防火规范》《常用危险化学品分类及标志》等相关法律法规、规章制度涉及的危化品经营单位安全管理领域公开测试、考试题目,得到待分析原始数据的危化品安全管理类文献题目数据集。
2.数据处理:1)采用文本标注,标注题目的难度级别(简单、中等、困难);2)采用TextRank提取摘要的方式提取每个段落的一个关键句,将关键句按照段落的顺序排列,组成新的文本内容;对文本内容提取出的关键句序列再进行一轮关键句提取,根据迭代传播权重计算各个句子的得分,再将每个句子输入序列标注模型,得到实体序列标注结果,包含实体越多的句子给予越高的重要度权重倾斜,实体权重得分和句子重要度得分之和即作为每个句子最终的重要度分数。每次设置一个范围在[1,3]的整型随机数r,提取排名前r的关键句作为该题的正确候选答案(即在TextRank模型中,T=r),将正确候选答案分类存储;3)在答案集中随机选择字符长度与原正确候选答案最为接近的2个答案成为该题目的错误候选答案,若答案集中符合要求的错误候选答案数量不足,则采用NLTK生成该答案的反义词作为错误候选答案的补充。
3.数据应用:该数据集可用来测试和提升危化品单位安全管理领域AI模型对场景理解的适用性。
We constructed a highly targeted and semantically complex training dataset through contextual annotation of knowledge assessment data in the safety management field for hazardous chemical business entities. These data undergo data parsing and safety compliance validation to generate professional samples in the safety management field of hazardous chemical business entities, which serve as comprehensive and professional test examples for fully evaluating the safety management knowledge of hazardous chemical business entities by AI Large Language Models (LLMs). The dataset supports assessments of semantic understanding, linguistic expression, and reasoning derivation capabilities when answering hazardous chemical safety management questions, as well as testing and improving the applicability of AI models in the field of hazardous chemical business entity safety management for scenario understanding.
1. Data Collection: Collect publicly available test and examination questions related to the safety management of hazardous chemical business entities from relevant laws, regulations and rules including the Law of the People's Republic of China on Work Safety, Fire Protection Law of the People's Republic of China, Regulations on the Safety Management of Hazardous Chemicals, Measures for the Administration of Hazardous Chemical Business Licenses, Regulations on the Labor Protection of Workplaces Using Toxic Substances, Regulations on the Reporting and Investigation of Production Safety Accidents, Code for Fire Protection in Building Design, Classification and Labels of Commonly Used Hazardous Chemicals, thereby obtaining a raw dataset of hazardous chemical safety management literature questions for subsequent analysis.
2. Data Processing:
1) Conduct text annotation to label the difficulty level of each question (simple, medium, difficult);
2) Adopt TextRank-based abstract extraction to extract one key sentence from each paragraph, and arrange these key sentences in the original paragraph order to form new text content. Perform another round of key sentence extraction on the obtained key sentence sequence: calculate the score of each sentence based on iterative propagation weights, input each sentence into a sequence labeling model to acquire entity sequence labeling results. Allocate higher importance weights to sentences containing more entities, and the sum of the entity weight score and the sentence importance score is taken as the final importance score of each sentence. Set an integer random number r ranging from [1, 3] each time, extract the top-ranked r key sentences as the correct candidate answers for the question (i.e., T = r in the TextRank model), and store the correct candidate answers in categorized sets;
3) Randomly select two answers from the answer set with the closest character length to the original correct candidate answers as the wrong candidate answers for the question. If the number of eligible wrong candidate answers in the answer set is insufficient, use NLTK to generate antonyms of the original answers as supplements for the wrong candidate answers.
3. Data Application: This dataset can be used to test and improve the applicability of AI models in the field of safety management for hazardous chemical business entities for scenario understanding.
提供机构:
杭州叙简科技股份有限公司
创建时间:
2025-07-01
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含737条危化品经营单位安全管理领域的测试题目,源自相关法律法规,每年更新,用于评估AI模型在危化品安全管理中的语义理解和推导能力。数据以excel格式存储,具有结构化字段如问题、选项、答案和解析,通过专业算法处理确保质量和适用性。
以上内容由遇见数据集搜集并总结生成


