monte-inc/tau2-banking-baselines
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/monte-inc/tau2-banking-baselines
下载链接
链接失效反馈官方服务:
资源简介:
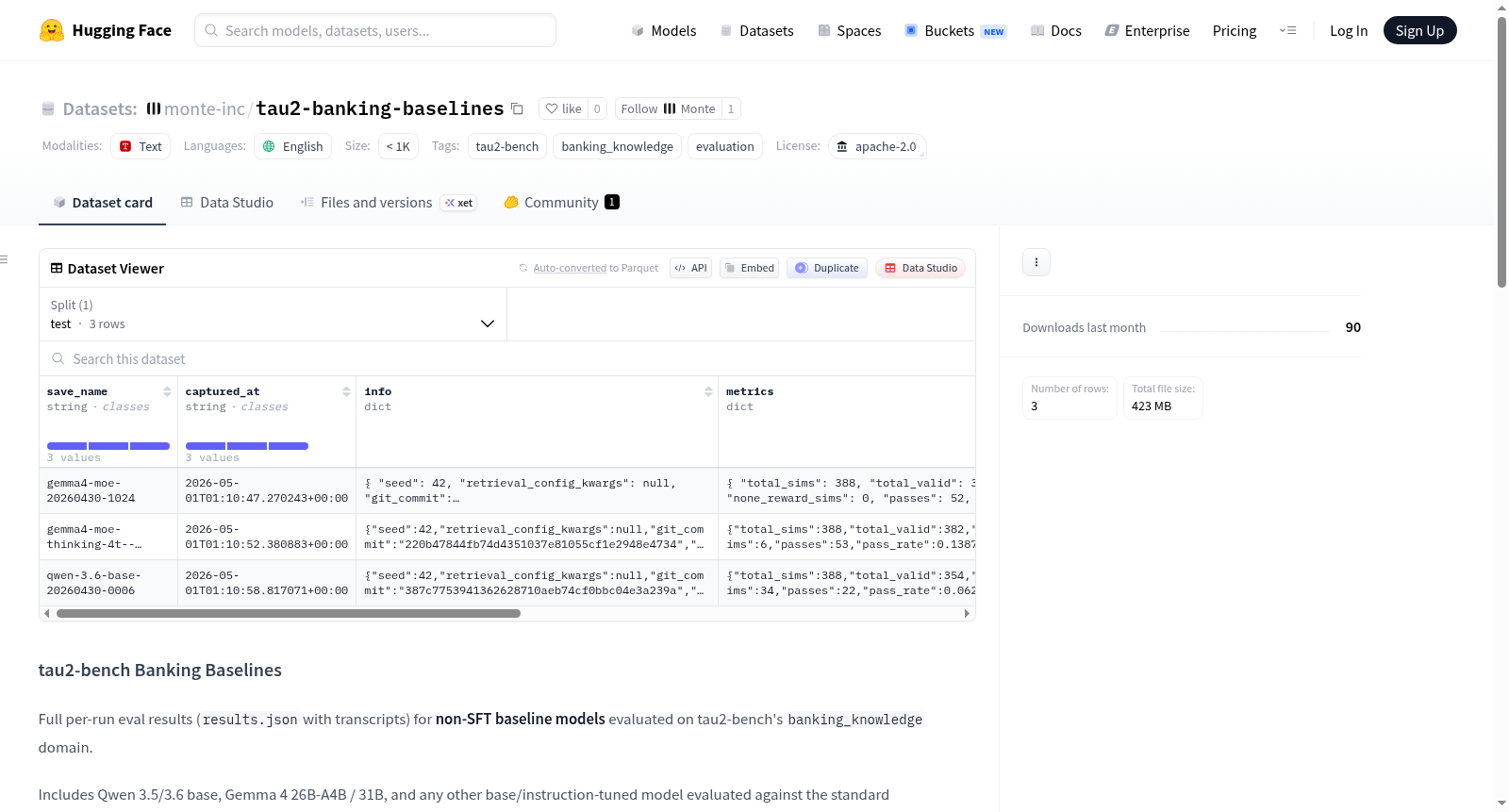
tau2-bench Banking Baselines数据集包含了对非SFT基线模型在tau2-bench的banking_knowledge领域上的完整评估结果。数据集提供了每次运行的评估结果(results.json,包含转录本),并包括了Qwen 3.5/3.6 base、Gemma 4 26B-A4B / 31B等基线模型的评估结果。这些结果可以作为比较锚点,用于评估SFT运行结果。数据集还详细描述了标准配置、每次运行的文件夹布局、使用方法以及数据来源。
tau2-bench Banking Baselines contains full per-run eval results (`results.json` with transcripts) for non-SFT baseline models evaluated on tau2-benchs `banking_knowledge` domain. It includes Qwen 3.5/3.6 base, Gemma 4 26B-A4B / 31B, and other base/instruction-tuned models evaluated against the standard pinned config. These results serve as comparison anchors for SFT runs. The dataset also details the standard configuration, per-run folder layout, usage instructions, and data source.
提供机构:
monte-inc
搜集汇总
数据集介绍
构建方式
该数据集源于tau2-bench评估框架中的banking_knowledge领域,专为非SFT基线模型设计。其构建过程通过固定配置参数(如采用terminal_use检索方式、gpt-5.2用户模拟器、模型温度设为0.0、最大步数为200、默认4次试验及种子42)在标准pinned配置下运行评估,收集Qwen 3.5/3.6 base、Gemma 4 26B-A4B/31B等基础与指令微调模型的逐次运行结果。每个运行文件夹内包含results.json(完整模拟结果,含逐任务消息记录、奖励信息、数据库检查及动作检查)、eval_summary.json(紧凑任务摘要)与serving_config.json(vLLM服务快照),数据由monte-inc/demo-tau2-banking-sft仓库生成并通过脚本发布。
特点
该数据集以完整性与可比性为核心特色。results.json作为事实来源,详细记录了每次模拟的完整交互过程,涵盖用户与模型之间的消息转录、任务完成奖励、数据库状态验证及动作有效性检查,为深入分析模型行为提供丰富素材。紧凑的eval_summary.json则提炼出通过/失败、耗时与成本等关键指标,便于快速概览。所有运行均采用统一硬件配置与固定随机种子,确保跨模型评估的可重复性。支持从HuggingFace Hub直接下载任意运行文件夹,为SFT微调模型提供可靠的性能锚点基准。
使用方法
使用该数据集时,首先通过huggingface_hub库的hf_hub_download函数指定仓库ID为monte-inc/tau2-banking-baselines,数据集类型为dataset,并设定所需运行的文件夹名称及results.json文件名进行下载。加载后以JSON格式解析内容,提取simulations字段中的每项任务模拟数据。通过访问reward_info下的reward键获取奖励值,筛除无效奖励后计算通过率(奖励≥1.0的任务占比),从而量化模型在banking_knowledge领域的基础表现。此外,可通过同理下载eval_summary.json与serving_config.json获取任务摘要与模型服务配置信息,以满足不同分析需求。
背景与挑战
背景概述
在对话式人工智能与任务导向型智能代理迅猛发展的当下,如何精确评估大语言模型在真实金融场景中的知识检索与执行能力,已成为学术界与工业界共同关注的核心议题。tau2-banking-baselines数据集由Monte Inc.团队创建,旨在为tau2-bench评估框架下的银行知识领域提供非监督微调基线的全量评估结果。数据集收录了包括Qwen 3.5/3.6基座模型、Gemma 4 26B-A4B/31B等代表性模型在标准化配置下的运行日志与评测摘要,涵盖模拟交互、奖励信息与动作检查等关键指标。作为tau2-banking评估体系的重要锚点,该数据集为对比监督微调效果、推进金融领域语言模型研究提供了可靠的基准参考。
当前挑战
该数据集涉及的领域问题核心挑战在于,银行知识场景对模型的事实准确性与错误容忍度要求极为严苛,单一错误可能导致严重的金融风险,传统通用评估指标难以捕捉此类领域特有的复杂约束。构建过程中,研究团队面临多项技术难点:如何模拟真实用户的多样化意图与表达方式,如何设计合理的奖励函数以平衡任务完成度与成本效率,以及如何在固定种子与温度参数下确保可复现的评估结果。此外,跨模型之间的上下文长度差异、服务配置的实时性变化以及少数早期运行仅单次试验带来的统计不确定性,均对评估的公平性与可比较性构成了实质挑战。
常用场景
经典使用场景
在金融领域知识密集型任务中,tau2-banking-baselines数据集被广泛用作非监督微调(non-SFT)基线模型的评估基准。该数据集完整记录了多种基础模型在tau2-bench的banking_knowledge领域上的逐轮实验结果,包括Qwen 3.5/3.6、Gemma 4 26B-A4B及31B等模型的完整仿真对话记录。研究人员通过加载results.json文件,提取每项任务的奖励值,即可精确计算任务通过率,从而系统性地评估模型在开放域银行知识问答场景中的表现。这一标准化配置使得不同模型之间的横向比较成为可能,为后续的微调优化提供了稳固的对照基准。
解决学术问题
该数据集有效解决了金融知识对话系统中缺乏统一评估标准的问题。在学术研究中,不同研究团队常因评测配置不一致导致结果难以复现和比较。tau2-banking-baselines通过固定领域、检索策略、用户模拟器、智能体温度、最大步数及随机种子等关键参数,构建了高度规范化的评估框架。研究者可借助这一基准,客观衡量模型在复杂银行知识任务上的真实能力,避免了因实验环境差异带来的偏差,推动了对话系统评估方法的科学化与标准化。
衍生相关工作
基于tau2-banking-baselines,研究者已发展出多项衍生工作。其中最具代表性的是monte-inc/tau2-banking-eval-results数据集,它聚焦于对基础模型进行监督微调(SFT)后的完整评估记录,与基线构成直接对照。此外,该数据集所依托的demo-tau2-banking-sft项目,提供了从评估脚本到结果发布的全链路工具,催生了一系列关于银行知识对话中检索增强生成与多轮对话策略的研究。这些工作共同构建了金融领域对话评估的生态系统,推动了技术迭代与标准化进程。
以上内容由遇见数据集搜集并总结生成


