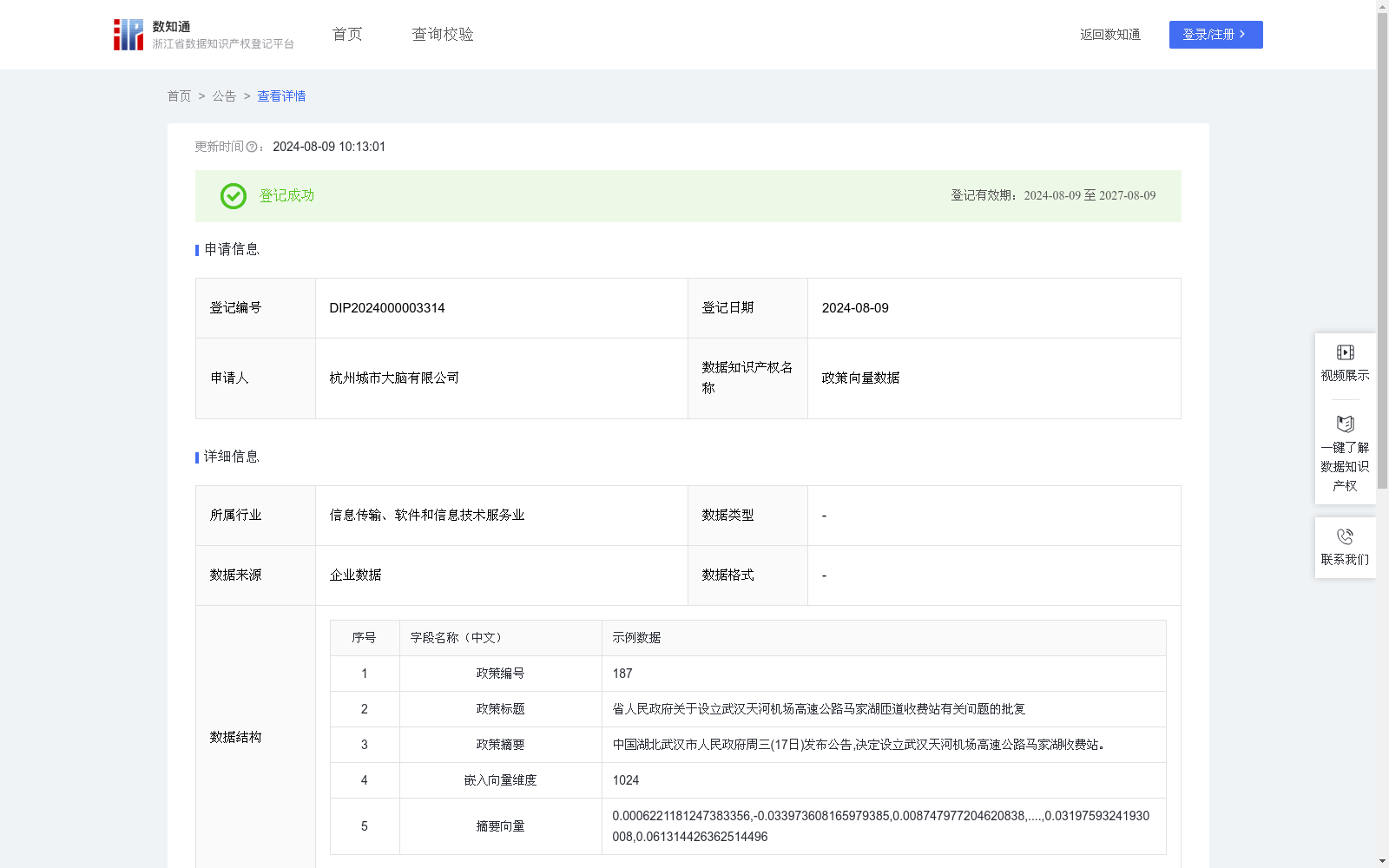
政策向量数据
收藏浙江省数据知识产权登记平台2024-08-09 更新2024-08-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/48725
下载链接
链接失效反馈官方服务:
资源简介:
简洁明了的政策摘要有助于社会各界更好地理解政策,便于新闻媒体进行报道,提高政策的社会知晓度,从而促进政策的广泛接受和执行。在后续政策检索中,政策摘要也可作为政策公文的重要组成部分,基于政策的摘要向量数据,可以实现政策的快速检索与归档,提高政策管理的效率。1.数据处理:对采集的政策文本数据进行数据清洗,仅保留可用的政策公文信息。剔除文本数据中可能存在的URL、IP地址、电子邮件、手机号码、电话号码、身份证号码信息;剔除无效的政策文本数据,判断标准为汉字数量是否少于10、符号比例是否低于50%、中英文字符和数字的占有比例是低于10%、中文字符比例是否低于10%。
2.政策摘要生成:对清洗后的文本数据进行摘要提取,基于注意力机制序列模型得到各政策原文对应的政策摘要文本。对于每一个政策数据文本,将Embedding后的数据按顺序输入到模型的编码器A中后得到每一个时间点的隐藏状态。之后计算注意力系数告诉编码器A在何处查找生成下一个词,以此得到编码器A隐藏状态的加权和。将源文件中读取固定大小内容与解码器A的隐藏状态连接,通过两个线性层进行馈送,最终得到待生成词汇的分布P,以P中概率最大的词作为当前时间点的输出词,最终得到各政策文本数据的摘要内容。
3.摘要数据向量化:使用bge-large-zh-v1.5嵌入模型对生成的政策摘要文本进行向量化处理,摘要文本与向量存入数据库,以供后续的业务使用。
Concise and clear policy summaries help all sectors of society better understand policies, facilitate news media coverage, improve public awareness of policies, and thus promote the widespread acceptance and implementation of policies. In subsequent policy retrieval, policy summaries can also serve as an important component of policy documents. Based on the vector data of policy summaries, rapid retrieval and archiving of policies can be achieved, enhancing the efficiency of policy management.
1. Data Processing: Perform data cleaning on the collected policy text data, only retaining available policy document information. Remove possible URLs, IP addresses, email addresses, mobile phone numbers, landline phone numbers, and ID card numbers from the text data. Invalid policy text data will be eliminated, with the following judgment criteria: whether the number of Chinese characters is less than 10, whether the proportion of symbols is lower than 50%, whether the proportion of Chinese, English characters and numbers is lower than 10%, and whether the proportion of Chinese characters is lower than 10%.
2. Policy Summary Generation: Extract summaries from the cleaned text data, and obtain the policy summary text corresponding to each original policy document based on a sequence model with attention mechanism. For each piece of policy text data, input the embedded data into the model's Encoder A in sequence to obtain the hidden state at each time step. Then calculate attention coefficients to guide Encoder A on where to locate for generating the next token, thereby obtaining the weighted sum of the hidden states of Encoder A. Connect the fixed-size content read from the source file with the hidden state of Decoder A, feed them through two linear layers, and finally obtain the probability distribution P over the target vocabulary. Take the word with the highest probability in P as the output token at the current time step, and finally generate the summary content for each piece of policy text data.
3. Summary Data Vectorization: Use the bge-large-zh-v1.5 embedding model to conduct vectorization processing on the generated policy summary text. Store the summary text and their corresponding vectors in a database for subsequent business applications.
提供机构:
杭州城市大脑有限公司
创建时间:
2024-07-16
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


