MNLP_M3_quantized_dataset
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/casimiir/MNLP_M3_quantized_dataset
下载链接
链接失效反馈官方服务:
资源简介:
MMLU STEM和健康数据集是从MMLU数据集中筛选出来的,只包含被归类为STEM(科学、技术、工程和数学)和健康类别的主题。这个数据集是将所有选定的STEM和健康主题测试集合并、随机打乱(使用固定种子)并分配唯一ID后创建的一个统一校准集。
The MMLU STEM and Health Dataset is a curated subset extracted from the original MMLU dataset, which only retains topics classified under STEM (Science, Technology, Engineering, and Mathematics) and health-related categories. This dataset is a unified calibration set constructed by merging the test sets of all selected STEM and health topics, randomly shuffling the combined samples with a fixed random seed, and assigning unique identifiers to each sample.
创建时间:
2025-06-07
原始信息汇总
MMLU STEM and Health 数据集概述
数据集基本信息
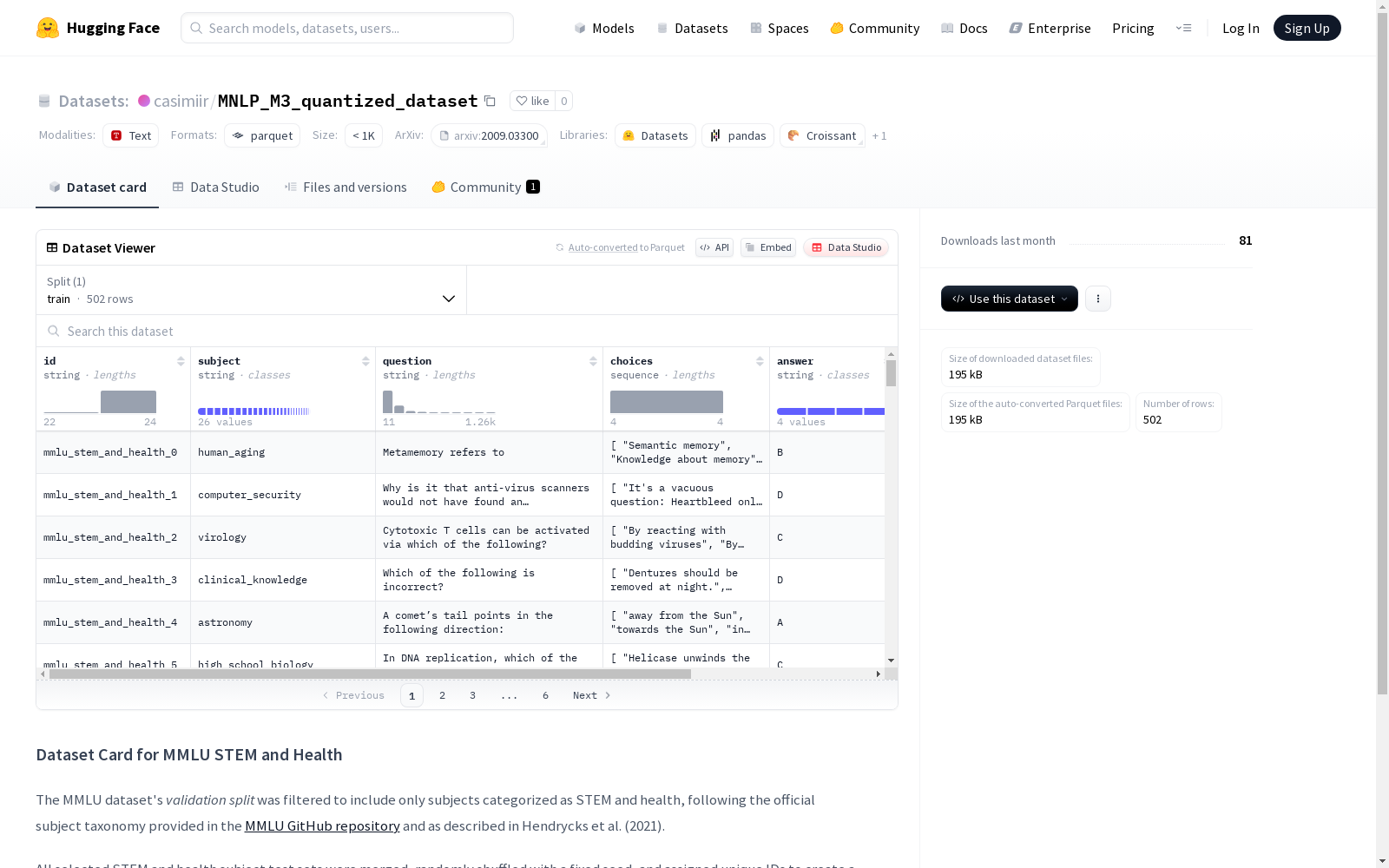
- 数据集名称: MMLU STEM and Health
- 存储大小: 333,700 字节
- 下载大小: 195,234 字节
- 训练集样本数: 502 个
- 数据格式: 结构化数据
数据特征
- id: 字符串类型,唯一标识符
- subject: 字符串类型,学科类别
- question: 字符串类型,问题内容
- choices: 字符串序列,选项列表
- answer: 字符串类型,正确答案
- prompt: 字符串类型,提示信息
数据来源与处理
- 基于 MMLU 数据集的验证集筛选
- 筛选标准: 仅包含 STEM 和健康类别的学科
- 数据处理步骤:
- 合并选定的 STEM 和健康学科测试集
- 使用固定种子随机打乱
- 分配唯一 ID 创建统一校准集
相关文献
- 原始 MMLU 论文: "Measuring Massive Multitask Language Understanding" (Hendrycks et al., 2021)
- 官方 GitHub 仓库: MMLU GitHub repository
搜集汇总
数据集介绍
构建方式
该数据集基于MMLU(Massive Multitask Language Understanding)的验证集筛选构建,专注于STEM(科学、技术、工程、数学)和健康领域的学科内容。通过官方学科分类体系,从原始数据中提取相关主题的测试集,经过合并与随机打乱处理,并赋予唯一标识符,最终形成一个统一的校准集合。这一过程严格遵循了Hendrycks等人在2021年提出的方法,确保了数据的科学性和一致性。
特点
数据集以多选问答形式呈现,涵盖广泛的STEM和健康领域知识,每个样本包含问题、选项和正确答案。其结构化设计便于模型校准和评估,特别适合用于测试语言模型在专业领域的理解能力。数据经过精心筛选和整理,具有高度的专业性和代表性,为研究者提供了可靠的基准测试资源。
使用方法
该数据集可直接用于模型微调或评估,尤其适合测试模型在STEM和健康领域的性能。用户可通过加载训练集文件获取数据,每个样本包含完整的问答上下文及提示信息。建议结合原始MMLU论文中的评估方法,对模型的多任务理解能力进行系统分析。数据集的设计兼容常见机器学习框架,便于集成到现有工作流程中。
背景与挑战
背景概述
MNLP_M3_quantized_dataset源于2021年Hendrycks等学者提出的MMLU(Massive Multitask Language Understanding)数据集,专注于STEM(科学、技术、工程、数学)与健康领域的知识评估。该数据集由加州大学伯克利分校的研究团队构建,旨在通过多学科选择题形式,衡量语言模型在复杂专业领域的理解能力。作为MMLU的子集,其筛选逻辑遵循原论文定义的学科分类体系,通过合并验证集中的STEM与健康类题目并赋予唯一标识符,为模型校准提供了标准化基准。这一工作推动了语言模型在垂直领域评估的精细化发展,成为后续研究的重要参照。
当前挑战
该数据集面临的核心挑战体现在两方面:领域问题的复杂性要求模型同时掌握跨学科专业知识与逻辑推理能力,例如医学术语的准确解析或物理公式的上下文应用;数据构建过程中需平衡学科覆盖广度与题目质量,原始MMLU的57个子学科分类体系导致筛选标准制定、题目重复检测及难度校准等环节均需人工介入。此外,量化过程中如何保留语义多样性而避免信息损失,亦是预处理阶段的技术难点。
常用场景
经典使用场景
在自然语言处理领域,MNLP_M3_quantized_dataset作为经过量化的专业数据集,主要服务于大规模多任务语言理解模型的评估与校准。该数据集通过对STEM和健康学科问题的系统整合,为研究者提供了跨学科知识理解的标准化测试平台,特别适合用于检验模型在数学、物理、生物医学等专业领域的推理能力。其结构化的问题-选项-答案三元组设计,使得它成为衡量模型细粒度知识掌握程度的理想基准。
实际应用
在实际应用中,该数据集被广泛用于医疗问答系统、教育智能辅助工具的研发测试。医疗机构借助其生物医学子集验证诊断辅助系统的可靠性,在线教育平台则利用数学和物理题目评估智能辅导系统的解题能力。数据集的量化特性显著降低了计算资源消耗,使得在边缘设备部署专业领域NLP应用成为可能。
衍生相关工作
基于该数据集衍生的研究包括多模态知识图谱构建、专业领域few-shot学习策略等方向。典型工作如STEM-QNet将量化问题嵌入与知识图谱相结合,提升了模型在物理化学问题的推理能力;HealthPrompt则利用该数据集开发了医疗领域提示词优化框架,相关成果发表在ACL和EMNLP等顶级会议。
以上内容由遇见数据集搜集并总结生成


