CommonCrawl-CreativeCommons-strict
收藏Hugging Face2025-08-28 更新2025-08-29 收录
下载链接:
https://huggingface.co/datasets/BramVanroy/CommonCrawl-CreativeCommons-strict
下载链接
链接失效反馈官方服务:
资源简介:
Common Crawl Creative Commons Corpus Strict (C5s) 是一个经过筛选的 Common Crawl Creative Commons 语料库,仅保留满足特定条件的样本:也出现在 FineWeb 或 FineWeb-2 数据集中;没有许可证分歧(所有找到的许可证类型相同;版本号可能不同);不是“非商业性”的(许可证中的“nc”);不是“cc-unknown”;名称中不含“wiki”(旨在包含维基百科和其他高质量资源中的维基数据,这些数据使用更好的解析器进行解析)。
Common Crawl Creative Commons Corpus Strict (C5s) is a curated Common Crawl Creative Commons corpus that retains only samples meeting specific criteria: samples must also appear in the FineWeb or FineWeb-2 dataset; there are no license discrepancies (all identified license types are identical, though version numbers may differ); they are not "non-commercial" licenses (containing the "nc" tag in the license); they are not marked as "cc-unknown"; and their names do not include the substring "wiki". This corpus is designed to include wikidata from Wikipedia and other high-quality resources, which are parsed using more advanced parsers.
创建时间:
2025-08-14
原始信息汇总
Common Crawl Creative Commons Corpus Strict (C5s) 数据集概述
数据集基本信息
- 许可证: Creative Commons (cc)
- 任务类别: 文本生成
- 任务ID: 语言建模
- 支持语言: 南非荷兰语 (afr)、德语 (deu)、英语 (eng)、法语 (fra)、弗里斯兰语 (fry)、意大利语 (ita)、荷兰语 (nld)、西班牙语 (spa)
数据集描述
该数据集是Common Crawl Creative Commons Corpus (C5) 的严格过滤版本,仅保留符合以下条件的样本:
- 同时存在于FineWeb或FineWeb-2数据集中
- 无许可证分歧(所有发现的许可证类型相同,版本号可能不同)
- 不包含"非商业"许可证(许可证中不含"nc")
- 不包含"cc-unknown"许可证
- 名称中不包含"wiki"(建议从其他高质量资源中包含Wikipedia和Wikidata,并使用更好的解析器解析)
数据特征
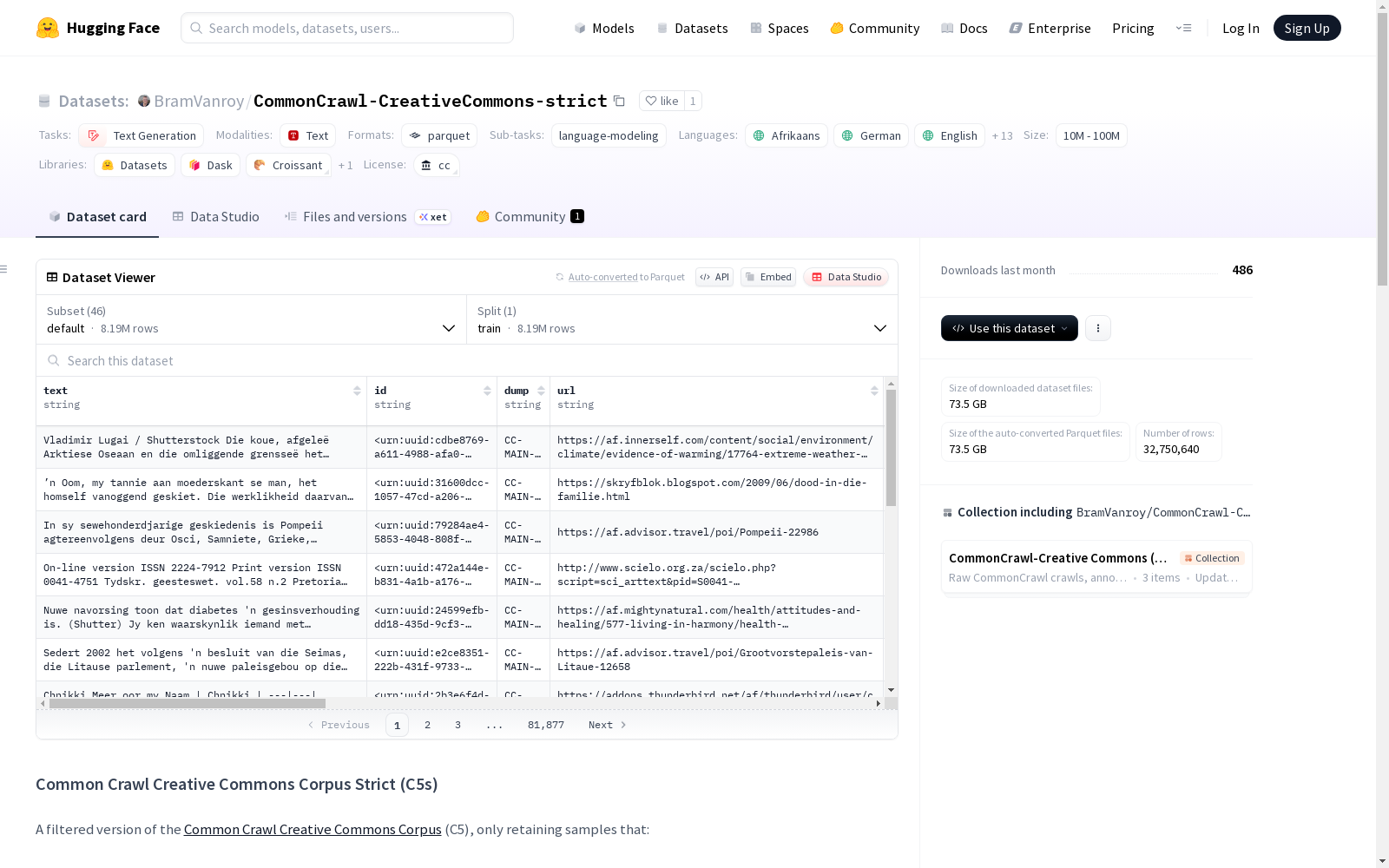
数据集包含以下特征字段:
- text: 文本内容(字符串类型)
- id: 标识符(字符串类型)
- dump: 转储信息(字符串类型)
- url: 来源URL(字符串类型)
- date: 日期(字符串类型)
- file_path: 文件路径(字符串类型)
- license_abbr: 许可证缩写(字符串类型)
- license_version: 许可证版本(字符串类型)
- license_location: 许可证位置(字符串类型)
- license_in_head: 许可证在头部(布尔类型)
- license_in_footer: 许可证在底部(布尔类型)
- license_parse_error: 许可证解析错误(布尔类型)
- license_disagreement: 许可证分歧(布尔类型)
- language_script: 语言脚本(字符串类型)
- language: 语言(字符串类型)
- language_score: 语言得分(浮点类型)
- potential_licenses: 潜在许可证(结构体类型,包含abbr、in_footer、in_head、location、version等字段)
数据集规模
- 总下载大小: 18,241,370,199 字节
- 总数据集大小: 35,049,867,677 字节
- 总样本数量: 8,187,660 条
- 训练集分割: 包含所有样本
包含的爬取数据配置
数据集包含多个配置,按爬取时间和语言分类:
- 时间配置: CC-MAIN-2019-30、CC-MAIN-2020-05、CC-MAIN-2022-05、CC-MAIN-2023-06、CC-MAIN-2024-46、CC-MAIN-2024-51
- 语言配置: afr、deu、eng、fra、fry、ita、nld、spa
- 默认配置: 包含所有训练数据
数据量统计
| 语言 | 原始文档数 | 严格版本文档数 | 原始令牌数 | 严格版本令牌数 |
|---|---|---|---|---|
| afr | 312,262 | 350 | 358,873,448 | 913,178 |
| deu | 9,530,746 | 89,340 | 11,362,859,534 | 84,408,955 |
| eng | 92,635,372 | 7,843,160 | 87,537,859,958 | 7,035,305,977 |
| fra | 9,234,900 | 44,824 | 12,366,480,025 | 43,143,952 |
| fry | 230,910 | 1 | 197,430,774 | 1,092 |
| ita | 10,734,597 | 68,418 | 11,913,669,333 | 58,765,829 |
| nld | 2,827,636 | 18,266 | 2,757,074,705 | 18,957,134 |
| spa | 22,226,944 | 123,301 | 22,515,709,432 | 113,258,753 |
| 总计 | 147,733,367 | 8,187,660 | 149,009,957,209 | 7,354,754,870 |
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,大规模语料库的构建需兼顾质量与版权合规性。CommonCrawl-CreativeCommons-strict数据集通过多阶段过滤机制形成:首先从Common Crawl原始数据中筛选同时存在于FineWeb或FineWeb-2数据集的样本,随后采用严格版权验证策略,排除存在许可协议分歧、非商业许可(含nc条款)及cc-unknown类型的文档,同时移除名称含wiki的条目以确保数据源解析质量。该过程通过自动化脚本实现跨年度网络爬取数据的标准化处理。
使用方法
研究者可通过HuggingFace数据集库以配置项形式灵活加载该资源,支持按爬取批次(如CC-MAIN-2019-30)或语言类别(如eng英语专属子集)进行模块化调用。数据以Parquet格式存储,兼容主流数据处理框架。典型应用场景包括多语言语言模型训练、网络文本版权合规性研究及跨语言信息检索系统开发。使用时应遵循Creative Commons许可协议,特别注意商业用途中对nc条款的规避要求。
背景与挑战
背景概述
在数字时代大规模文本数据资源日益重要的背景下,CommonCrawl-CreativeCommons-strict数据集由研究团队基于Common Crawl项目构建,专注于筛选符合严格许可标准的网络文本。该数据集聚焦多语言语料处理与版权合规性,旨在为自然语言处理领域提供高质量、法律清晰的训练数据,支持语言模型优化及跨语言研究,自2019年起持续扩展语料规模与覆盖语种。
当前挑战
该数据集核心挑战在于解决网络文本版权状态模糊性与多语言质量均衡问题,需精确识别兼容Creative Commons许可的内容并排除非商业限制。构建过程中面临网页结构异质性导致的许可信息提取困难,以及低资源语言如弗里斯兰语样本稀缺,同时需协调大规模数据存储与高效清洗流程的技术复杂度。
常用场景
经典使用场景
在自然语言处理领域,大规模语料库是训练语言模型的基础资源。CommonCrawl-CreativeCommons-strict数据集通过严格筛选机制,为研究者提供了高质量的多语言文本数据。该数据集最经典的应用场景是作为预训练语料,支持Transformer架构的生成式语言模型进行自监督学习,特别是在跨语言建模任务中展现出色性能。其经过精细过滤的文本内容确保了训练数据的纯净度,为模型理解不同语言的语法结构和语义关系奠定了坚实基础。
解决学术问题
该数据集有效解决了多语言自然语言处理中的关键学术问题。通过提供严格遵循知识共享协议的清洁文本,它克服了网络爬取数据中常见的版权争议和内容质量问题。数据集的多语言平行特性为跨语言迁移学习研究提供了理想素材,支持学者探索语言间的语义对齐和表示学习机制。其精细的元数据标注体系更为研究数字内容许可协议与文本分布关系提供了独特视角,推动了计算语言学与法律 informatics 的交叉研究。
实际应用
在实际应用层面,该数据集为多语言服务系统开发提供了重要支撑。企业可利用其训练面向特定语种的智能客服机器人,提升跨语言沟通效率。教育科技公司基于该数据集开发的语言学习工具,能够为学习者提供更自然的语言环境模拟。内容创作平台则借助其训练文本生成模型,辅助用户进行多语言内容创作。这些应用不仅促进了数字内容的全球化传播,更为保护知识产权提供了技术实现路径。
数据集最近研究
最新研究方向
在自然语言处理领域,CommonCrawl-CreativeCommons-strict数据集作为高质量多语言语料库,正推动大语言模型预训练的前沿研究。其严格的知识共享许可筛选机制与FineWeb数据集的交叉验证,为模型训练提供了法律合规且语义丰富的文本资源。当前研究热点聚焦于多语言模型对齐、跨语言迁移学习以及版权合规的文本生成技术,该数据集通过提供精确的语言标注和许可信息,显著降低了模型训练中的法律风险。随着欧盟人工智能法案等法规的实施,这类经过严格过滤的开源数据集已成为构建合规AI系统的重要基石,对推动负责任人工智能发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


