doraking/ryukyuan-okinawan-corpus
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/doraking/ryukyuan-okinawan-corpus
下载链接
链接失效反馈官方服务:
资源简介:
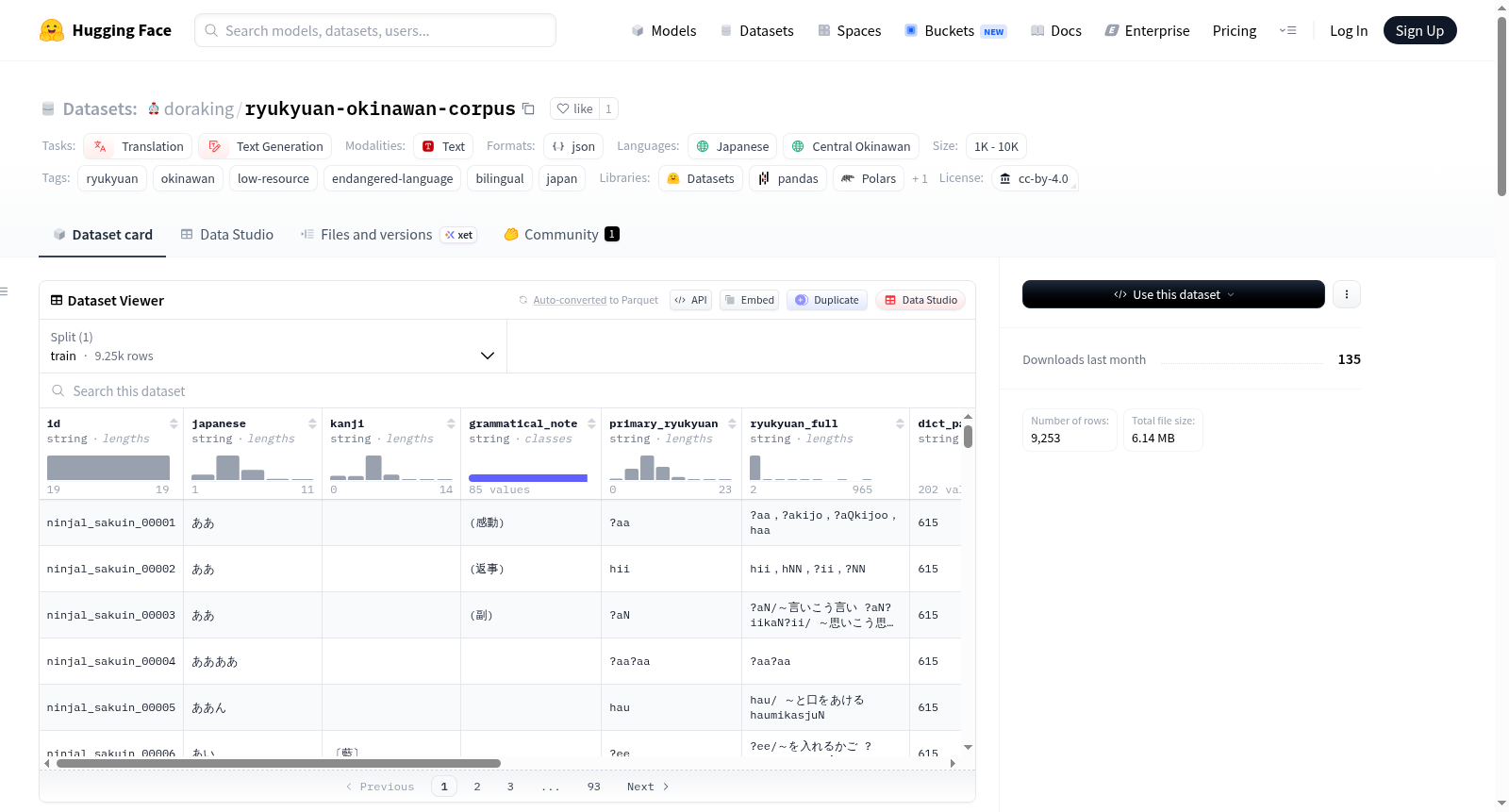
这是一个由日本国立语言研究所发布的日语与琉球语(首里方言)的双语词典数据集。数据集基于《冲绳语辞典》索引篇(CC BY 4.0)结构化而成,包含9,253条记录,涵盖日语到琉球语的翻译。琉球语被联合国教科文组织列为濒危语言,目前使用者估计不足数百人。数据集格式包括CSV和JSONL,包含日语词条、汉字表记、语法注释、琉球语词条等信息。数据集适用于机器翻译、低资源语言建模、语言保存和多语言词典构建等任务。
This is a bilingual dictionary dataset of Japanese and Ryukyuan (Shuri dialect) released by the National Institute for Japanese Language and Linguistics. The dataset is structured based on the Okinawan Language Dictionary index (CC BY 4.0) and contains 9,253 records covering translations from Japanese to Ryukyuan. Ryukyuan is classified as an endangered language by UNESCO, with current speakers estimated to be fewer than a few hundred. The dataset format includes CSV and JSONL, containing Japanese entries, kanji notation, grammatical notes, Ryukyuan entries, and more. The dataset is suitable for tasks such as machine translation, low-resource language modeling, language preservation, and multilingual dictionary construction.
提供机构:
doraking
搜集汇总
数据集介绍
构建方式
本数据集基于国立国語研究所公开发表的《沖縄語辞典》索引篇(CC BY 4.0)进行结构化整理而成,构建过程严格遵循语言学编纂规范,通过系统化的数据清洗与字段映射,将原始辞典条目转化为适用于自然语言处理任务的日本语—琉球语(首里方言)双语平行语料,共计9,253条记录,涵盖汉字表记、品词注解及方言变体等丰富信息。
使用方法
数据集以CSV与JSONL两种格式提供,用户可直接加载至数据框架中进行预处理,适用于机器翻译、低资源语言建模、语言文献记录及多语言词典构建等任务,需注意琉球语字段包含复合词与相关语形,建议根据具体研究需求选择主词条或全字段进行实验,并遵循CC BY 4.0许可协议标注来源。
背景与挑战
背景概述
琉球语作为联合国教科文组织认定的濒危语言,其数字资源极度匮乏。2026年,国立国语研究所基于1963年刊行的《冲绳语辞典》索引篇,构建了首个面向自然语言处理的琉球语(冲绳语)与日语双语词典语料库。该数据集由日本国立国语研究所主导,采用CC BY 4.0许可协议公开,核心研究问题在于为濒危语言保护提供可计算的语言资源。数据集收录了9253条日语—琉球语(首里方言)对照条目,覆盖汉字表记、语法标注等多种信息,填补了低资源语言机器翻译与语言建模领域的空白。其发布对数位人文学科与濒危语言数字化保存具有里程碑意义,为后续冲绳语方言的NER、词性标注等任务奠定了数据基础。
当前挑战
该数据集所解决的领域挑战主要有三层。其一,语言资源的极端稀缺性:琉球语现存仅数百名母语者,缺乏大规模标注语料,传统辞典的数字化转化需解决学术转写符号(如声门闭锁音?、促音Q等)在文本生成中的统一表达问题。其二,构建过程中的方言变体与数据稀疏困境:数据集仅涵盖首里方言,冲绳本岛其他次方言(如那霸方言、岛尻方言)因无成典资源而无法纳入;同时,品词标注字段仅覆盖295条记录(占总量3.2%),高质量语法标注的不足限制了深层语言模型的训练。其三,跨领域适配瓶颈:数据为词典格式而非自然对话文本,用于翻译任务时需依赖额外上下文重构,且在OCR校验、罗马字转写歧义消解等预处理阶段面临较高的工程技术挑战。
常用场景
经典使用场景
在语言文档与机器翻译的交叉领域,琉球语-冲绳语语料库作为一份珍贵且稀缺的日语-琉球语(首里方言)双语对话资源,为低资源语言建模提供了典范性的训练语料。研究者可利用其结构化的对齐条目,开展从日语到琉球语的神经机器翻译实验,探索在极端低资源条件下如何借助迁移学习、数据增强或跨语言预训练模型来缓解数据匮乏问题。该语料库的9,253条记录虽规模有限,却涵盖了汉字表记、品词标注与发音转写等多维信息,使其成为评估小语种翻译质量与模型泛化能力的理想基准,同时为理解琉球语语法与词汇的演变提供了不可替代的实证基础。
解决学术问题
该数据集直面了濒危语言数字化保存与计算语言学资源极度匮乏的双重挑战。在学术层面,它系统性地解决了琉球语作为无标准书写系统、语料稀疏的语言在自然语言处理中面临的语料采集与标注难题,填补了日本语言多样性与语系演变研究的计算资源空白。通过提供规范的罗马字转写与ISO语言代码映射,该数据集使得研究者能够将注意力转向如何在小样本场景下构建有效的序列到序列模型、评估形态复杂语言的表示学习技术,以及对比不同世代方言的变化轨迹,从而推动语言消亡的定量分析与语言保护技术的创新。
实际应用
在真实世界的应用场景中,该数据集赋能了面向琉球语母语社区的语言学习与数字传承工具开发。基于其双语条目,可构建交互式移动词典、智能问答系统或自动翻译接口,帮助年轻一代和语言学习者跨越方言与标准日语之间的沟通鸿沟。此外,该资源支持博物馆与档案馆中的文物说明自动翻译、地方文化内容的跨语言检索,以及面向语言学田野调查者的辅助标注平台,使濒危语言的记录、教学与传播不再受限于少数专家的手工操作,而是融入可扩展的信息技术体系中,焕发新的生命力。
数据集最近研究
最新研究方向
该数据集聚焦于极度濒危语言——琉球语(冲绳语首里方言)与日语的平行语料构建,为低资源自然语言处理开辟了崭新天地。在当前人工智能浪潮中,语言消亡速度加快,全球每年约有数十种语言失去最后一位母语者,而该语料库的发布恰逢联合国‘国际土著语言十年’(2022-2032)的关键节点,为计算语言学的语言复兴工程提供了可量化的基础。其9,253条对齐条目虽规模有限,却承载着音系转写语法注解与词源信息的精妙结构,使零样本机器翻译与跨语言预训练模型得以在微型语料上微调,从而实证性地推动‘濒危语言数字化生存’这一前沿命题。这不仅关乎技术突破,更是文化多样性的数字挽歌——当语言消逝,数据便是记忆的方舟。
以上内容由遇见数据集搜集并总结生成


