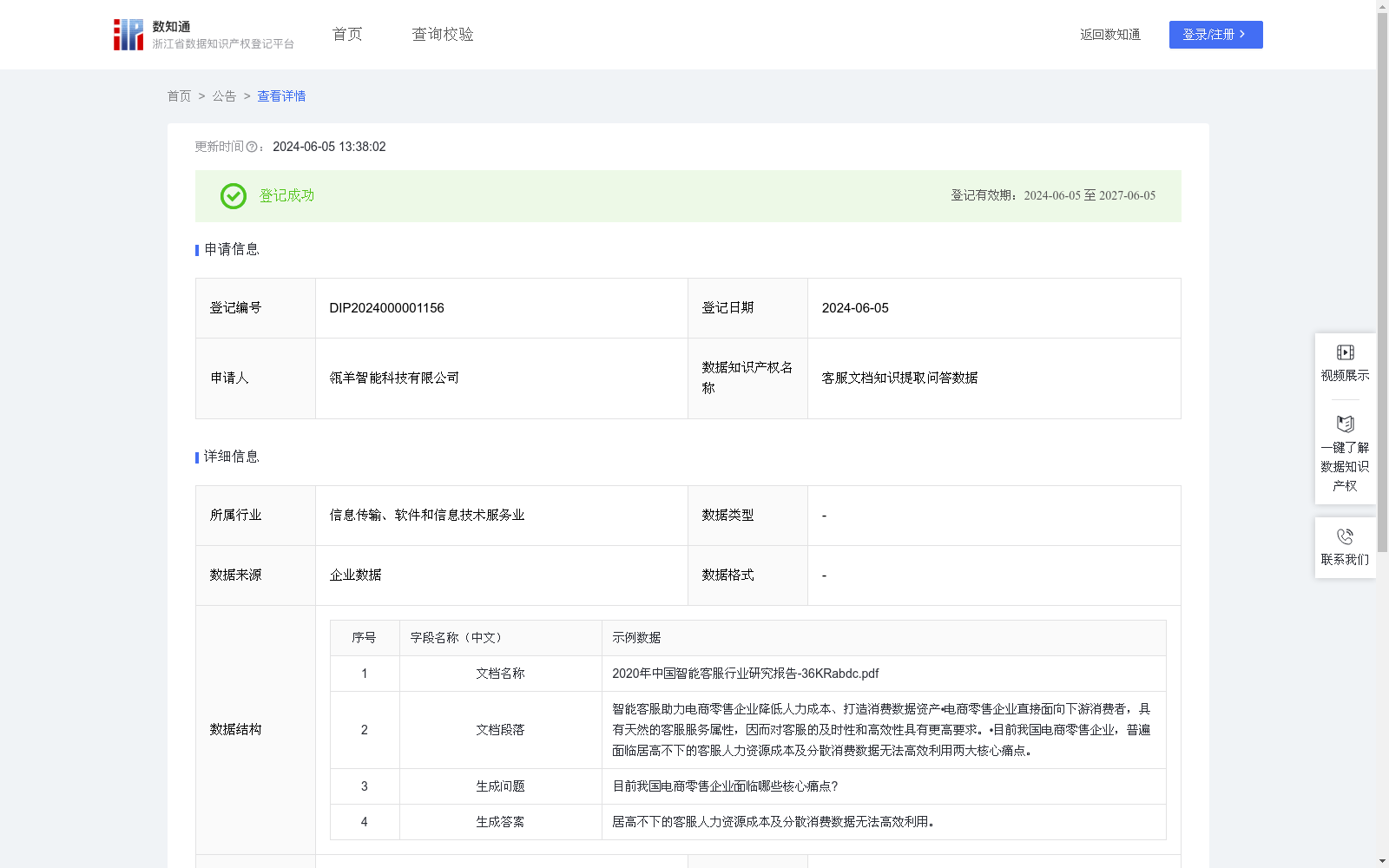
客服文档知识提取问答数据
收藏浙江省数据知识产权登记平台2024-06-05 更新2024-06-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/33792
下载链接
链接失效反馈官方服务:
资源简介:
对合法采集的企业文档数据进行分析、处理,帮助企业快速提取文档中的问答对,提升企业知识运营效率,完善机器人知识库等系统。客服文档知识提取问答数据的算法规则包括:
1、数据采集和处理:客户通过产品页面,上传PDF/DOCX等文档数据,含文字和图片等内容。
2、算法加工:针对上传的文档文件等数据,通过OCR、版面分析等文档解析模型,识别出文件中的文字和图片等文档段落信息内容。这样,完成了从文档源格式文件到文档段落内容的提取。基于每个文档段落,应用NLP大模型(基于抽样的文本段落和相应的标定的问答对SFT训练的大模型),从这些信息中,抽取出若干个问答对(包含问题和答案部分)。汇总所有文档段落的问答对结果,即得到了整篇文档的所有问答对抽取结果。
This dataset analyzes and processes legally collected enterprise document data, aiming to help enterprises rapidly extract question-answer pairs from documents, enhance enterprise knowledge operation efficiency, and optimize systems such as robot knowledge bases. The algorithmic rules for extracting question-answer pairs from customer service document knowledge are as follows:
1. Data Collection and Processing: Customers upload document data containing text and images (such as PDF/DOCX files) via the product page.
2. Algorithmic Processing: For uploaded document files and related data, document parsing models including OCR and layout analysis are adopted to recognize text, images and other document paragraph information within the files, thereby completing the extraction from the original document format files to document paragraph content. Based on each individual document paragraph, the NLP large language model (a large model trained via Supervised Fine-Tuning (SFT) using sampled text paragraphs and their corresponding annotated question-answer pairs) is applied to extract multiple question-answer pairs (including question and answer sections) from this information. Summarizing the question-answer pair results of all document paragraphs yields the complete set of question-answer pair extraction results for the entire document.
提供机构:
瓴羊智能科技有限公司
创建时间:
2024-04-30
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


