grundtvigs-works
收藏Hugging Face2025-06-24 更新2025-06-25 收录
下载链接:
https://huggingface.co/datasets/chcaa/grundtvigs-works
下载链接
链接失效反馈官方服务:
资源简介:
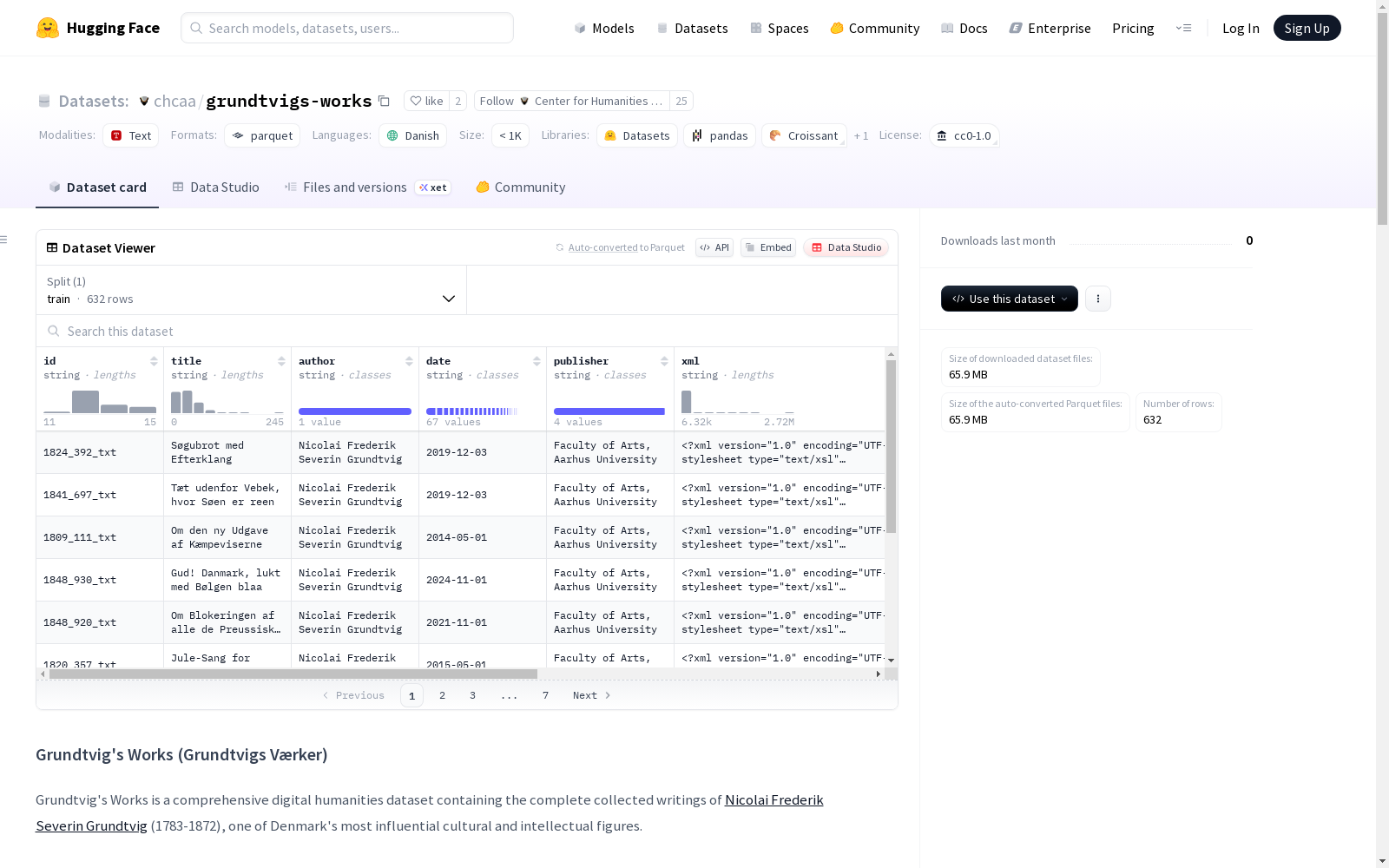
Grundtvig's Works是一个全面的数字人文数据集,包含了Nicolai Frederik Severin Grundtvig(1783-1872)的全部作品集,他是丹麦最有影响力的文化和知识分子之一。这个数据集包含了632部作品,作品格式多样,主要语言为19世纪的丹麦语。数据集由奥胡斯大学的Grundtvig中心策划,属于公共领域(CC0)。
Grundtvig's Works is a comprehensive digital humanities dataset containing the complete collected works of Nicolai Frederik Severin Grundtvig (1783–1872), one of Denmark’s most influential cultural and intellectual figures. This dataset includes 632 works in various formats, predominantly in 19th-century Danish. Curated by the Grundtvig Centre at Aarhus University, the dataset is released into the public domain under CC0.
提供机构:
Center for Humanities Computing Aarhus
创建时间:
2025-06-24
搜集汇总
数据集介绍
构建方式
在数字人文领域,Grundtvig's Works数据集的构建体现了对丹麦文化遗产的系统性保护。该数据集源自奥胡斯大学Grundtvig中心的权威典藏,通过专业数字化流程将19世纪丹麦思想家N.F.S. Grundtvig的632部作品转化为结构化数据。原始XML文件经过标准化处理,转换为Markdown和纯文本格式,并保留完整的元数据框架,包括作品标题、作者、出版年份等关键信息。技术团队采用版本控制机制确保数据转换的可追溯性,相关处理脚本已在平台公开。
使用方法
研究者可通过Hugging Face平台直接访问该数据集的三种文本格式,XML版本适合数字人文领域的标记分析,Markdown格式便于快速浏览,而TXT文本则适用于自然语言处理任务。数据集已预分割为训练集,用户可根据需要提取特定年代或主题的作品子集。对于北欧语言模型开发,建议结合丹麦Dynaword项目其他语料共同使用。使用时应注意到19世纪丹麦语的词汇和语法特征,宗教与哲学文本的专业性可能要求特定的预处理步骤。奥胡斯大学Grundtvig中心提供原始数据的学术咨询支持。
背景与挑战
背景概述
Grundtvig's Works数据集是数字人文领域的重要资源,收录了丹麦文化巨擘N.F.S. Grundtvig(1783-1872)的全部著作。作为19世纪丹麦神学、教育和民主思想的核心人物,Grundtvig的著作对斯堪的纳维亚文化认同产生了深远影响。该数据集由奥胡斯大学Grundtvig中心精心整理,包含632件作品的多格式文本,涵盖XML、Markdown和纯文本三种形式,为研究丹麦文化遗产、宗教历史和欧洲思想史提供了结构化数据支持。该资源的数字化不仅实现了文化资产的永久保存,更通过纳入丹麦语语言模型训练集Dynaword,将传统人文研究与前沿人工智能技术相融合。
当前挑战
该数据集面临双重挑战:在学术层面,19世纪丹麦语的古语特征与现代语言模型预训练存在语义鸿沟,需要解决历史拼写变体与当代词汇的对齐问题;在技术层面,原始XML文件的跨格式转换涉及复杂的文本规范化处理,特别是诗歌等特殊文类的版式保留具有较高难度。数据集构建过程中,如何平衡数字化保真度与机器学习可用性成为关键矛盾,且部分元数据字段(如日期标注标准)尚需进一步澄清。这些挑战直接影响着该文化遗产在数字时代的阐释与再利用效能。
常用场景
经典使用场景
在数字人文研究领域,Grundtvig's Works数据集为学者提供了研究19世纪丹麦文化、神学和教育思想的珍贵原始资料。该数据集收录了丹麦重要思想家格伦特维的全部著作,其多格式文本结构特别适合进行跨学科分析,包括文学风格计算、历史语义变迁追踪以及宗教文本比较研究。数字化的文本格式极大便利了远距离阅读和文本挖掘技术的应用。
解决学术问题
该数据集有效解决了北欧研究领域原始文献获取困难的关键问题,使研究者能够系统考察格伦特维思想体系的演变轨迹。通过结构化存储的文本数据,学者可以深入分析丹麦民族启蒙运动时期语言特征与思想传播的关系,为文化记忆研究提供量化依据。数据集包含的XML标注版本更为语义分析和概念网络构建创造了技术条件。
实际应用
在教育领域,该数据集被用于开发丹麦文学数字教学资源,通过文本可视化展示思想发展脉络。文化机构利用其构建在线展览,向公众传播丹麦文化遗产。在语言技术领域,作为Danish Dynaword项目的组成部分,这些经过整理的文本为训练丹麦语NLP模型提供了高质量的历史语料,弥补了北欧小语种资源不足的现状。
数据集最近研究
最新研究方向
近年来,Grundtvig's Works数据集在数字人文领域引发了广泛关注,尤其在文化遗产数字化保存和北欧思想史研究方面展现出独特价值。该数据集收录了丹麦文化巨擘格伦特维的完整著作,为19世纪北欧宗教改革、民主思想演变及教育体系发展提供了珍贵的一手文献。当前研究热点集中在三个维度:基于XML标记的文本结构分析揭示了格伦特维独特的修辞体系;跨模态转换技术(如XML到Markdown的自动转换)提升了古籍数字化的效率;该数据集作为丹麦Dynaword项目的组成部分,正被用于训练新一代北欧语言模型,推动文化遗产与人工智能的深度融合。这些探索不仅拓展了数字人文方法论的边界,更为小语种文化资源的智能化处理提供了范式参考。
以上内容由遇见数据集搜集并总结生成


