DialoSpeech
收藏arXiv2025-10-09 更新2025-10-11 收录
下载链接:
https://tiamojames.github.io/DialoSpeech/
下载链接
链接失效反馈官方服务:
资源简介:
DialoSpeech数据集是一个用于对话文本到语音合成的双轨对话数据集,包含约5000小时的中文对话数据,包括来自Biaobei Corp.的3000小时专业录音对话和5000小时的自发多说话人中文播客数据,以及2000小时的英文电话对话数据。数据集通过双轨数据流程处理,生成与说话人对应的语义标记序列。该数据集旨在解决多说话人对话合成中自然性、上下文一致性和互动动态性等方面的挑战,支持中文和英文以及跨语言语音合成。
DialoSpeech is a dual-track dialogue dataset for conversational text-to-speech synthesis. It contains approximately 5,000 hours of Chinese dialogue data, including 3,000 hours of professionally recorded dialogue from Biaobei Corp., 5,000 hours of spontaneous multi-speaker Chinese podcast data, and 2,000 hours of English telephone conversation data. The dataset is processed via a dual-track data pipeline to generate semantic token sequences corresponding to specific speakers. This dataset aims to address the challenges in multi-speaker dialogue synthesis, such as naturalness, contextual consistency and interactive dynamics, and supports text-to-speech synthesis for Chinese, English as well as cross-lingual scenarios.
提供机构:
西北工业大学声学实验室, DataBaker (Qingdao) Technology
创建时间:
2025-10-09
原始信息汇总
DialoSpeech: Dual-Speaker Dialogue Generation with LLM and Flow Matching
摘要
- 提出DialoSpeech,一种结合大型语言模型和分块流匹配的双轨架构,用于表达性、类人对话语音合成。
- 生成自然的多轮对话,具有连贯的说话人轮换和自然重叠。
- 支持中文、英语和跨语言语音合成。
- 引入数据处理流程构建双轨对话数据集,促进可扩展训练和实验验证。
- 实验表明模型优于基线,为生成类人语音对话提供解决方案。
演示样本
中文对话样本
- 对话文本1:
- [s1] 我觉得啊,就是经历了这么多年的经验, 就是补剂的作用就是九分的努力, 十分之一的补剂。 嗯,选的话肯定是九分更重要,但是我觉得补剂它能够让你九分的努力更加的有效率,更加的避免徒劳无功。 嗯,就是你,你你得先得真的锻炼,真的努力,真的健康饮食,然后再考虑补剂, 那你再加十十分之一的补剂的话,他可能就是说啊, 一半是心理作用,
- [s2] 对,其实很多时候心理作用是非常重要的。嗯,然后我每次用补剂的时候,我就会更加努力,就比如说我在健身之前我喝了一勺蛋白粉,我就会督促自己多练,
- [s1] 其实心理作用只要能实现你的预期目的就可以了。 就比如说给自行车链条加油, 它其实不是必要的,但是它可以让你骑行更顺畅, 然后提高你骑行的频率。
- 对话文本2:
- A: 哎,好久不见,李明听说你研究生是保研到了西北工业大学的 ASLP 实验室是吗?
- B: 嗯,是的,我之前就一直对像音频啊语音合成这些特别感兴趣,刚好实验室也在专注研究这块,就真的,嗯,挺幸运的吧呵呵。
- A: 哦?那今天能和大家分享一下你们最近在语音合成方面的一些进展吗?感觉大家呃现在对这方面都挺感兴趣呢。
- B: 对,最近我们刚开发出了一个用16万小时中英文数据训练的模型,呃效果怎么说呢,嗯,真的非常不错。
DialoSpeech vs. CoVoMix (英文)
- 对话文本1:
- [s1]he was in jail for fourteen times and they finally deported him [s2] fourteen times [s1] yeah his family spent over two hundred thousand dollars keeping him here [s2] wow [s1] and then finally they said no that’s it he’s out can’t even come back to visit
- 对话文本2:
- [s1]my life was like consumed with the television and it was it was just sad i it that was awful [s2] and i remember the i think the day after and like gas prices went up to like three bucks a gallon [s1] oh i know [s2]everybody was like filling up with gas in the town i live in panicking and mhm [s1] really wow
- 对话文本3:
- [s1]something around there yeah that’s that’s good [s2] i don’t think they’d ever get a divorce [s1] no i know
- 对话文本4:
- [s1]so i’m not i don’t know what it is i don’t know what the minimum wage is or [s2] uh it’s five fifteen now it was like four seventy five something like that [s1] my gosh
- 对话文本5:
- [s1]which is uh very strange it’s not something i ever thought would happen [s2] yeah that’s not good [s1] no
- 对话文本6:
- [s1]hard choice to make especially when you get peer pressure and then once you start doing it hey look now i’m cool [s2] mhm but in reality if you actually had to do that to be cool you’re hanging with the wrong parents anyways right right i think my brother in law and his
搜集汇总
数据集介绍
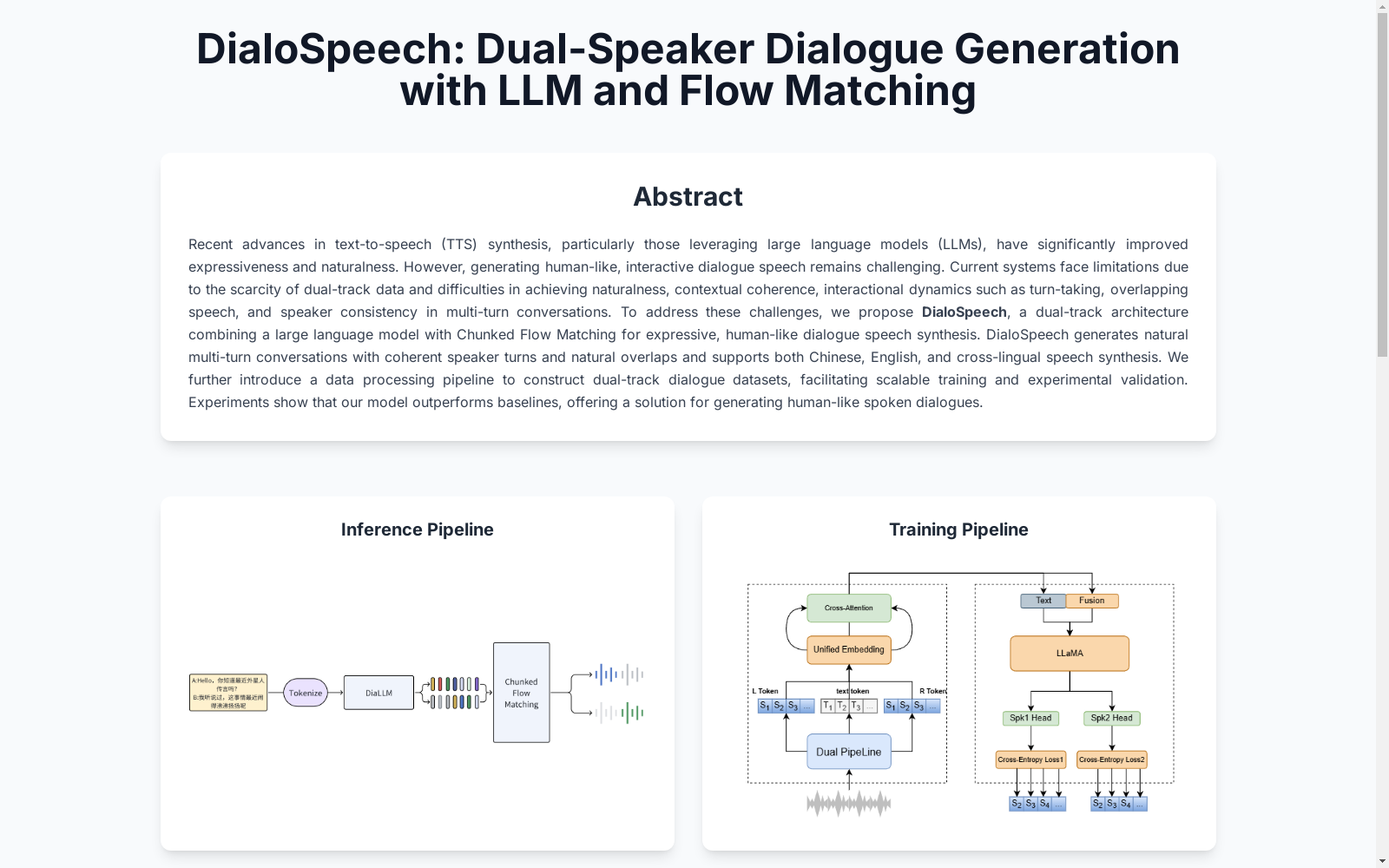
构建方式
在对话语音合成领域面临高质量双声道数据稀缺的背景下,DialoSpeech构建了一套模块化数据处理流程。该流程通过采集播客和视频博客等长音频资源,采用并行处理策略将原始音频分割为20分钟片段,同步执行语音活动检测、Paraformer自动语音识别和Pyannote说话人日志分析。通过多阶段过滤机制确保数据质量,包括信噪比筛选、说话人聚类一致性验证和DNSMOS感知质量评估,最终利用SpatialNet实现重叠语音分离,形成标准化双轨对话数据集。
特点
DialoSpeech数据集展现出多维度技术特征,其核心在于双轨语义令牌表示体系,能够精准捕捉对话中的说话人转换与重叠语音现象。数据集涵盖中英双语及跨语言合成能力,通过ECAPA-TDNN说话人嵌入实现零样本语音克隆。独特的块状流匹配机制支持长音频流式处理,而因果交叉注意力架构则有效建模说话人间的交互动态。数据规模达万小时级,包含专业对话、自发播客和电话录音等多源数据,为对话生成研究提供丰富素材。
使用方法
该数据集适用于分阶段对话生成任务,首先通过S3令牌化器将输入文本转化为双轨语义令牌,经由基于LLaMA的DiaLM模型解析对话上下文并预测令牌序列。在波形重建阶段,采用分块条件流匹配模型将语义令牌转换为梅尔频谱图,最后通过BigVGAN声码器生成高质量波形。评估时需结合主观指标(自然度、连贯性、可懂度)和客观指标(词错误率、说话人相似度、UTMOS),特别注重完整对话片段的整体感知质量评估。
背景与挑战
背景概述
DialoSpeech数据集由西北工业大学音频语言与语音处理实验室于2025年提出,聚焦于双说话人对话语音生成的前沿研究。该数据集通过整合大规模播客对话、专业录制语音及跨语言语料,构建了包含5000小时多模态对话数据的高质量语料库,旨在解决传统单说话人语音合成系统在自然对话交互中存在的语义连贯性与语音动态性不足的瓶颈。其创新性地融合大语言模型与流匹配技术,显著提升了多轮对话中说话人身份一致性、语音重叠和话轮转换的建模能力,为智能语音助手和虚拟人交互系统提供了关键技术支撑。
当前挑战
DialoSpeech需应对对话语音合成领域的两大核心挑战:在领域问题层面,传统系统难以精准模拟人类对话中的动态交互特征,包括话轮转换的时序协调性、语音重叠的声学真实性以及跨说话人身份一致性的保持;在数据构建层面,高质量双通道对话语料的稀缺性成为主要制约因素,需通过复杂的数据处理流程解决原始音频中说话人分离、重叠语音检测、多模态对齐等问题,同时需克服跨语言语料异构性带来的声学特征不一致与语义标注复杂性。
常用场景
经典使用场景
在语音合成领域,DialoSpeech数据集被广泛用于训练多说话人对话生成系统,其核心应用场景是模拟真实人类对话中的交互动态。该数据集通过双轨架构捕捉说话人轮换、重叠语音和上下文连贯性,为研究自然对话合成提供了关键数据支撑。典型使用方式包括构建零样本语音克隆系统,以及评估模型在跨语言对话生成中的表现,有效推动了交互式语音合成技术的发展。
实际应用
该数据集在智能语音助手、虚拟主播和交互式教育系统中具有广泛应用。其双轨对话生成能力可赋能智能客服实现多轮自然对话,支持跨语言播客内容自动生产,并为社交机器人提供拟人化交互基础。实际部署中,系统能根据文本脚本实时生成带有个性化音色的对话语音,显著提升了人机交互的沉浸感与效率。
衍生相关工作
基于DialoSpeech衍生的经典研究包括改进型双轨Transformer架构、跨语言流匹配声学模型,以及对话状态跟踪算法。这些工作继承其双轨数据处理范式,进一步发展了动态注意力机制和块状解码策略。相关成果已延伸至多媒体内容生成领域,如CoVoMix的混合语音增强版本和MoonCast的长格式对话扩展,共同推动了对话生成技术的演进。
以上内容由遇见数据集搜集并总结生成


