SEED_balanced
收藏SEED_balanced 数据集概述
数据集基本信息
- 数据集名称: SEED_balanced
- 数据集类型: 公开平衡版本
- 语言: 英语
- 许可证: 其他
- 任务类别: 图像分类、图像分割
- 标签: 深度伪造、人脸取证、扩散模型、序列编辑、来源追溯、面部操纵
- 规模类别: 10K < n < 100K
核心描述
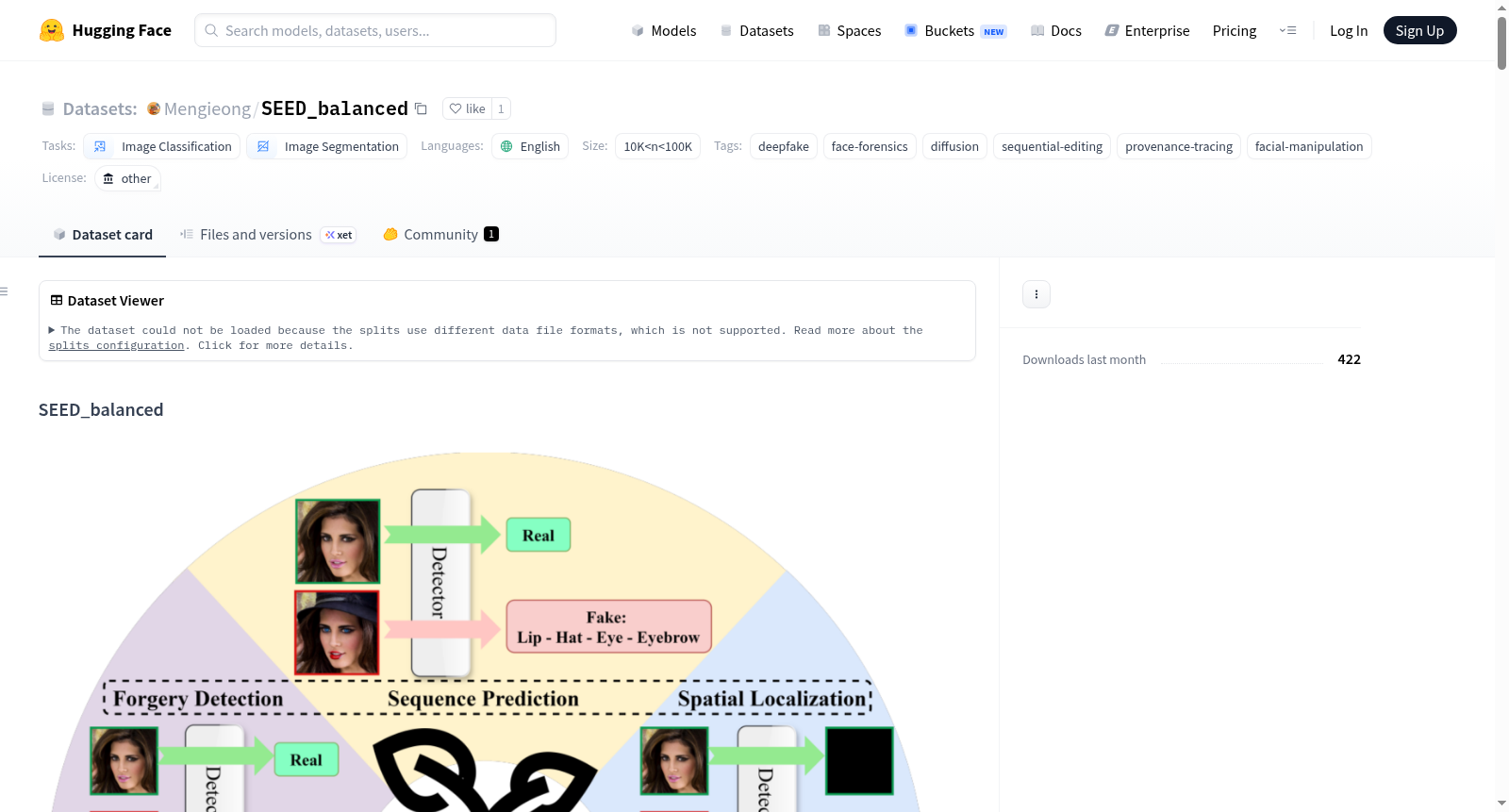
SEED_balanced 是 SEED 基准的公开平衡发布版本,该基准用于序列深度伪造面部编辑中的来源追溯。与专注于单步操纵或二元真伪检测的传统深度伪造数据集不同,SEED 模拟基于扩散模型的多步面部编辑轨迹,并支持三个互补任务:真实性分析、编辑痕迹分析和空间证据分析。完整 SEED 基准包含 91,526 张图像,并带有逐步来源标注;而平衡的基准分区包含 100,000 张图像,序列长度(L=0,1,2,3,4)的比例相等。
数据详情
- 完整基准规模: 91,526 张图像
- 平衡基准规模: 100,000 张图像
- 领域: 面部图像
- 编辑类型: 基于扩散模型的序列面部编辑
- 源真实数据集: FFHQ, CelebAMask-HQ
- 逐步元数据: 编辑顺序、属性标签、提示词、掩码、编辑器身份
- 官方评估平台: CodaBench
支持的任务
| 任务 | 描述 | 输出 |
|---|---|---|
| 真实性分析 | 区分真实图像与序列编辑图像 | 二元或基于序列的决策 |
| 编辑痕迹分析 | 预测编辑属性及其时间顺序 | 有序属性序列 |
| 空间证据分析 | 定位被操纵区域 | 掩码 / 定位图 |
数据构建
SEED 构建自 FFHQ 和 CelebAMask-HQ,并使用基于扩散模型的流程进行编辑。每个被操纵的样本通过顺序应用一到四个属性编辑生成,每个步骤都记录了来源元数据,包括被编辑的属性、提示词、掩码和编辑模型。
构建阶段
| 阶段 | 描述 |
|---|---|
| 预处理 | 构建特定属性掩码和文本条件 |
| 序列操纵 | 采样序列长度 L ∈ {1,2,3,4},选择属性,并逐步应用扩散编辑器 |
| 质量评估 | 使用感知和语义一致性检查过滤退化结果 |
使用的编辑器
- UltraEdit
- LEdits
- SDXL
- SD3-style models fine-tuned with UltraEdit
提示词模板示例
| 属性 | 指令模板 | 描述模板 |
|---|---|---|
| 眼睛 | Make the eyes {color}. | A person with {color} eyes. |
| 嘴唇 | Change the lipstick color to {color}. | A person with {color} lipstick. |
| 头发 | Turn the hair {color}. / Make the hair {style}. | A person with {color} hair. / A person with {style} hair. |
| 眉毛 | Make the eyebrows {style}. | A person with {style} eyebrows. |
| 眼镜 | Add a pair of {glasses}. | A person wearing {glasses}. |
| 帽子 | Add a {hat}. | A person wearing a {hat}. |
数据集统计
完整 SEED 统计
| 统计项 | 数值 |
|---|---|
| 完整 SEED 图像 | 91,526 |
| 序列长度 L=1 | 29.91% |
| 序列长度 L=2 | 26.21% |
| 序列长度 L=3 | 21.88% |
| 序列长度 L=4 | 22.00% |
| UltraEdit 编辑 | 38.28% |
| LEdits 编辑 | 37.34% |
| SDXL 编辑 | 24.38% |
属性分布
| 属性 | 比例 |
|---|---|
| 嘴唇 | 28% |
| 眉毛 | 18% |
| 眼睛 | 17% |
| 帽子 | 14% |
| 头发 | 14% |
| 眼镜 | 9% |
平衡分区与划分协议
| 长度桶 | 数量 |
|---|---|
| L=0,真实 | 20,000 |
| L=1 | 20,000 |
| L=2 | 20,000 |
| L=3 | 20,000 |
| L=4 | 20,000 |
| 总计 | 100,000 |
基准评估
官方评估在 CodaBench 上进行,使用三种指标:
| 指标 | 含义 |
|---|---|
| Fixed-Acc | 固定序列比较协议下的令牌级准确率 |
| Adaptive-Acc | 自适应序列比较下的令牌级准确率 |
| Full-Acc | 精确序列匹配,最严格的指标 |
论文报告的平均结果
| 模型 | Fixed-Acc | Adaptive-Acc | Full-Acc |
|---|---|---|---|
| Shuai et al. | 71.50 | 54.07 | 48.72 |
| FreqNet | 70.08 | 52.59 | 48.27 |
| Ba et al. | 68.78 | 54.80 | 50.80 |
| SeqFakeFormer | 81.62 | 68.53 | 66.97 |
| FAITH (DCT) | 81.70 | 68.56 | 67.02 |
| FAITH (FFT) | 81.75 | 68.58 | 67.03 |
| FAITH (DWT) | 81.87 | 68.84 | 67.26 |
鲁棒性设置评估
论文还在以下扰动下评估了鲁棒性:
| 扰动 | 级别 |
|---|---|
| JPEG 压缩 | 25%, 50%, 75% |
| 高斯噪声 | 10%, 15%, 20% |
仓库内容
此 Hugging Face 仓库仅托管公开发布内容。
| 文件 | 描述 |
|---|---|
seqdeepfake_train_data.zip |
公共训练存档 |
README.md |
数据集卡片 |
sample_submission.csv |
可选的示例提交文件 |
此仓库不包含:
- 隐藏测试标签
- 隐藏参考标注
- 官方私有评估数据
这些组件通过 CodaBench 处理。
预期用途
此数据集预期用于:
- 深度伪造取证研究
- 扩散编辑来源追溯
- 编辑顺序预测
- 定位和证据分析
- 图像退化下的鲁棒性基准测试
数据使用政策
请仅将此数据集用于研究、基准测试和取证分析。 请不要将其用于:
- 身份识别或监控
- 基于面部分析
- 欺骗性内容生成
- 对真实个人的未经授权推断
用户还应尊重原始源数据集的许可证和使用条件,以及任何特定于基准的发布条件。
引用
如果使用此数据集,请引用 SEED 论文。 bibtex @inproceedings{seed2026, title={SEED: A Large-Scale Benchmark for Provenance Tracing in Sequential Deepfake Facial Edits}, author={Anonymous ECCV 2026 Submission}, booktitle={Proceedings of the European Conference on Computer Vision}, year={2026} }