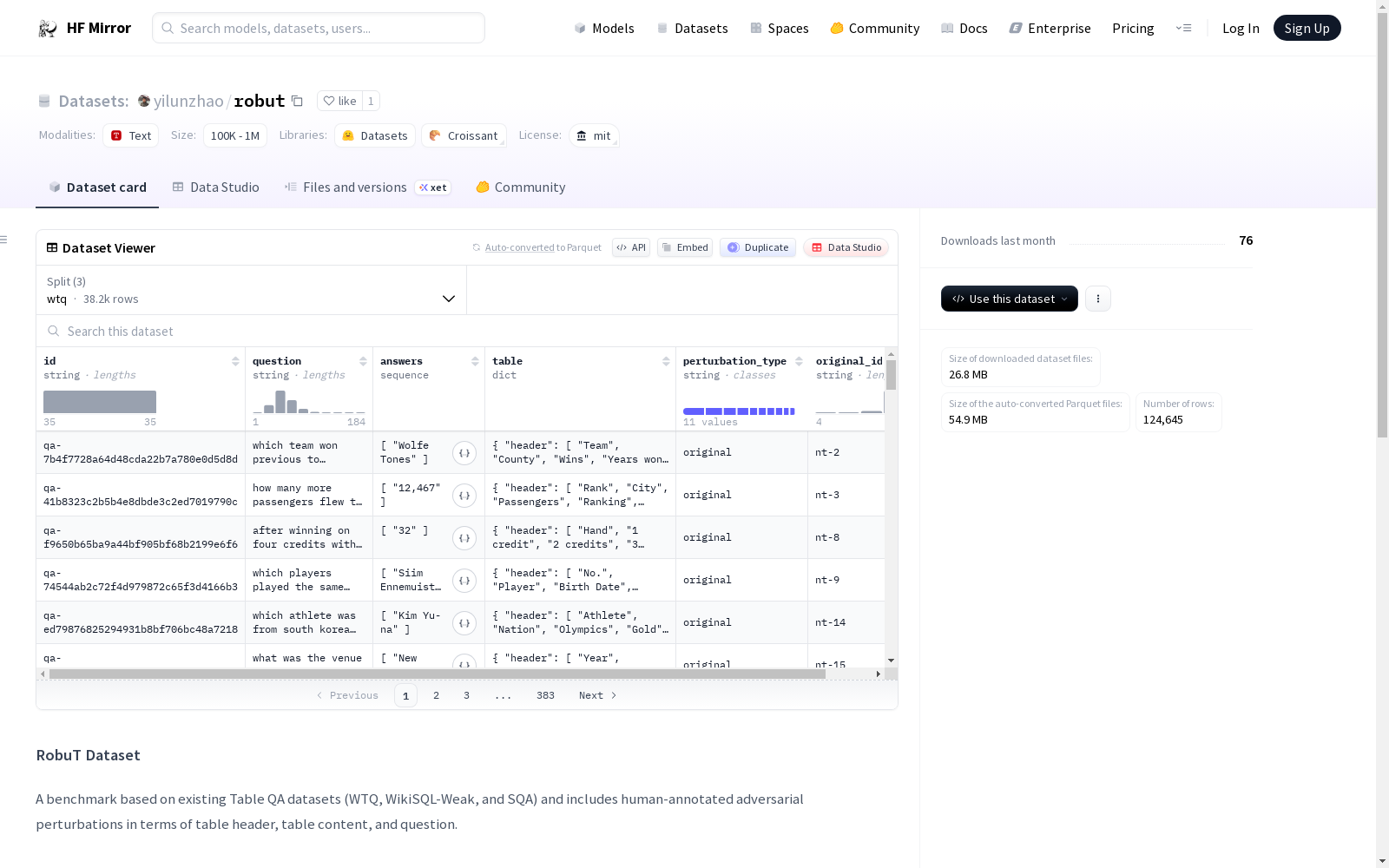
yilunzhao/robut
收藏RobuT Dataset
-
描述: 基于现有的Table QA数据集(WTQ, WikiSQL-Weak, 和 SQA)构建的基准数据集,包含人工标注的对抗性扰动,涉及表格标题、表格内容和问题。
-
许可证: MIT
-
引用:
@inproceedings{zhao-etal-2023-robut, title = "{R}obu{T}: A Systematic Study of Table {QA} Robustness Against Human-Annotated Adversarial Perturbations", author = "Zhao, Yilun and Zhao, Chen and Nan, Linyong and Qi, Zhenting and Zhang, Wenlin and Tang, Xiangru and Mi, Boyu and Radev, Dragomir", booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2023", address = "Toronto, Canada", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2023.acl-long.334", doi = "10.18653/v1/2023.acl-long.334", pages = "6064--6081", }