bentrevett/caltech-ucsd-birds-200-2011
收藏Hugging Face2024-03-19 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/bentrevett/caltech-ucsd-birds-200-2011
下载链接
链接失效反馈官方服务:
资源简介:
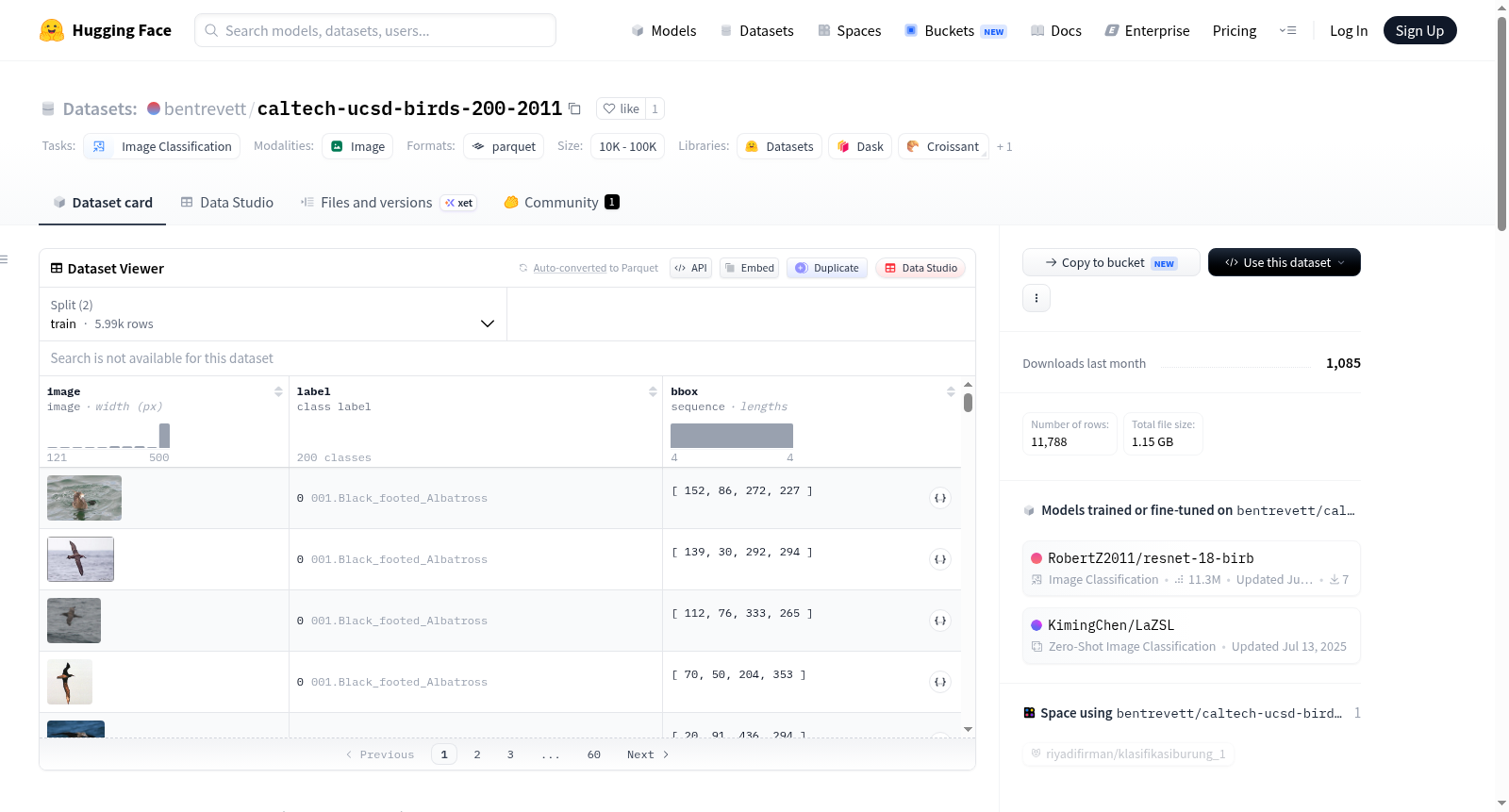
该数据集包含Caltech-UCSD Birds-200-2011(CUB-200-2011)数据集,其中每个样本包括一张图片、一个标签和一个边界框。数据集分为训练集和测试集,共有200个类别,每个类别在训练集中有29-30个示例。此外,数据集还提供了边界框的详细信息和如何在图像上绘制边界框的示例代码。
该数据集包含Caltech-UCSD Birds-200-2011(CUB-200-2011)数据集,其中每个样本包括一张图片、一个标签和一个边界框。数据集分为训练集和测试集,共有200个类别,每个类别在训练集中有29-30个示例。此外,数据集还提供了边界框的详细信息和如何在图像上绘制边界框的示例代码。
提供机构:
bentrevett
原始信息汇总
数据集概述
数据集信息
特征
- 图像 (image): 数据类型为图像。
- 标签 (label): 数据类型为类别标签,包含200个不同的鸟类名称。
- 边界框 (bbox): 数据类型为浮点数序列。
数据分割
- 训练集 (train): 包含5994个实例,占用578565600.046字节。
- 测试集 (test): 包含5794个实例,占用571979272.934字节。
数据集大小
- 下载大小: 1145059821字节。
- 数据集大小: 1150544872.98字节。
配置
- 默认配置 (default):
- 训练集文件路径:
data/train-* - 测试集文件路径:
data/test-*
- 训练集文件路径:
任务类别
- 图像分类 (image-classification)
大小类别
- 10K<n<100K
数据集详情
数据分割
- 训练集: 5994个实例,每个类别包含29-30个样本。
- 测试集: 5794个实例,每个类别样本数有较大变化,最少为11个。
边界框
- 每个边界框格式为
[x0, y0, x1, y1],可用于图像标注。
引用信息
@techreport{WahCUB_200_2011, Title = The Caltech-UCSD Birds-200-2011 Dataset, Author = {Wah, C. and Branson, S. and Welinder, P. and Perona, P. and Belongie, S.}, Year = {2011} Institution = {California Institute of Technology}, Number = {CNS-TR-2011-001} }
搜集汇总
数据集介绍
构建方式
Caltech-UCSD Birds-200-2011(CUB-200-2011)数据集源自加州理工学院与加州大学圣地亚哥分校的联合研究项目,旨在为细粒度图像分类任务提供基准。该数据集通过系统收集200种北美鸟类的自然图像构建而成,每张图像均经过人工标注,包含类别标签和边界框(bounding box)信息。边界框以[x0, y0, x1, y1]格式记录,精准定位鸟类主体。数据集划分为训练集(5,994张图像)和测试集(5,794张图像),每类在训练集中约有29-30个样本,确保了类别平衡性。此外,原始数据还包含部件位置(如喙、眼睛)和属性标签(如喙形状、羽毛颜色),但当前版本仅保留图像、标签和边界框,以简化使用。
特点
该数据集的核心特点在于其细粒度分类的挑战性,涵盖200个鸟类子类别,类别间视觉差异细微,如不同种类的信天翁或麻雀,对模型区分能力要求极高。每张图像均提供边界框,支持目标检测与分类联合任务,并可通过简单代码可视化标注效果。数据集规模适中,总样本数约11,788张,属于中等规模,便于快速迭代实验。值得注意的是,部分图像与ImageNet数据集重叠,这为迁移学习研究提供了便利。此外,数据集的类别命名规范且具有层次性,例如'001.Black_footed_Albatross',便于索引与检索。
使用方法
使用该数据集时,可通过HuggingFace的datasets库直接加载,命令为`datasets.load_dataset('bentrevett/caltech-ucsd-birds-200-2011')`。加载后,数据以字典形式组织,包含'image'(PIL图像对象)、'label'(整数类别索引)和'bbox'(浮点数列表)字段。边界框可用于目标定位,例如通过PIL的ImageDraw绘制矩形框。数据预分为'train'和'test'两个子集,可直接用于模型训练与评估。对于分类任务,可忽略边界框;对于检测任务,则需结合边界框进行损失计算。建议使用预训练模型(如ResNet)进行微调,以应对细粒度分类的挑战。
背景与挑战
背景概述
Caltech-UCSD Birds-200-2011(CUB-200-2011)数据集由加州理工学院与加州大学圣地亚哥分校的研究团队于2011年创建,核心研究人员包括Wah、Branson、Welinder、Perona和Belongie。该数据集聚焦于细粒度图像分类这一核心研究问题,旨在推动计算机视觉领域对高度相似物种的精准识别能力。作为细粒度视觉识别领域的里程碑式资源,CUB-200-2011提供了200种北美鸟类的图像,每张图像均附带类别标签、边界框以及部件位置和属性标注,为模型学习类间细微差异提供了丰富基准。其影响力深远,不仅催生了大量细粒度分类算法,还成为评估注意力机制和局部特征提取能力的标准测试平台。
当前挑战
该数据集所解决的领域挑战在于细粒度图像分类中类间差异极小的问题,例如区分黑脚信天翁与莱桑信天翁,需要模型捕捉羽毛纹理、喙形等局部细节。构建过程中面临的主要挑战包括:确保200个类别在数据分布上的均衡性,训练集每类仅29至30个样本,测试集样本数量波动较大(最低仅11例),增加了模型泛化难度;边界框标注需精确覆盖每只鸟的轮廓,而图像中鸟类姿态多变、背景复杂,提升了标注一致性维护的难度;此外,部分图像与ImageNet重叠,要求数据集在提供补充信息的同时避免冗余,以聚焦于细粒度特征的独立评估。
常用场景
经典使用场景
Caltech-UCSD Birds-200-2011(CUB-200-2011)数据集作为细粒度图像分类领域的标志性基准,被广泛用于评估模型在高度相似子类别间进行精准辨别的能力。该数据集涵盖200种北美鸟类,每类包含约30张图像,并提供了边界框标注,使得研究者能够聚焦于目标区域,从而有效检验卷积神经网络、注意力机制及Transformer架构在局部特征提取与判别性表示学习上的性能。其经典用法在于推动从全局分类向部件级细粒度识别的范式演进。
实际应用
在实际应用中,CUB-200-2011衍生的技术被部署于生态监测、生物多样性保护及农业害虫识别等领域。例如,通过部署基于该数据集训练的轻量级模型,可自动分析野外相机捕获的鸟类图像,实现种群动态监测与濒危物种追踪。此外,其细粒度分类框架被迁移至植物叶片、昆虫等生物鉴定场景,助力非专家用户通过移动端应用快速获取物种信息,从而赋能公民科学项目与生态教育。
衍生相关工作
围绕CUB-200-2011衍生出大量经典工作,包括Part-based R-CNN引入部件检测以增强局部特征,以及Bilinear CNN Models通过双线性池化捕获二阶特征交互。近年来,Vision Transformer(ViT)与Swin Transformer等架构在此数据集上验证了自注意力机制对细粒度模式的建模优势。此外,弱监督部件定位方法如WILDCAT与注意力图对齐技术进一步推动了标注效率的提升,这些工作共同构成了细粒度视觉理解的里程碑式进展。
以上内容由遇见数据集搜集并总结生成


