BeIR/bioasq-generated-queries
收藏Hugging Face2022-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BeIR/bioasq-generated-queries
下载链接
链接失效反馈官方服务:
资源简介:
BEIR Benchmark是一个异构基准,由18个不同数据集构建而成,涵盖9种信息检索任务,包括事实核查、问答、生物医学信息检索、新闻检索、论点检索、重复问题检索、引用预测、推文检索和实体检索。该基准支持英语单一语言,并详细说明了数据集的结构,包括语料库、查询和相关性判断文件。此外,还提供了每个数据集大小的分类和数据分割信息。
BEIR Benchmark is a heterogeneous benchmark constructed from 18 distinct datasets, covering 9 types of information retrieval tasks, including fact checking, question answering, biomedical information retrieval, news retrieval, argument retrieval, duplicate question retrieval, citation prediction, tweet retrieval, and entity retrieval. This benchmark supports only the English language, and details the structure of the datasets, including corpora, query files, and relevance judgment files. Additionally, classifications of the size of each dataset and data split information are provided.
提供机构:
BeIR
原始信息汇总
数据集概述
名称: BEIR Benchmark
描述: BEIR是一个异构基准,由18个多样化的数据集组成,代表9种信息检索任务。这些数据集包括事实检查、问答、生物医学信息检索、新闻检索等多个领域。
语言: 英语 (en)
许可证: CC-BY-SA-4.0
多语言性: 单语种
数据集结构
-
数据集大小:
msmarco: 1M<n<10Mtrec-covid: 100k<n<1Mnfcorpus: 1K<n<10Knq: 1M<n<10Mhotpotqa: 1M<n<10Mfiqa: 10K<n<100Karguana: 1K<n<10Ktouche-2020: 100K<n<1Mcqadupstack: 100K<n<1Mquora: 100K<n<1Mdbpedia: 1M<n<10Mscidocs: 10K<n<100Kfever: 1M<n<10Mclimate-fever: 1M<n<10Mscifact: 1K<n<10K
-
数据格式:
corpus:.jsonl文件,包含文档的唯一标识符、标题和文本。queries:.jsonl文件,包含查询的唯一标识符和文本。qrels:.tsv文件,包含查询标识符、文档标识符和相关性评分。
任务和支持
任务类别:
- 文本检索
- 零样本检索
- 信息检索
- 零样本信息检索
具体任务:
- 段落检索
- 实体链接检索
- 事实检查检索
- 推文检索
- 引用预测检索
- 重复问题检索
- 论证检索
- 新闻检索
- 生物医学信息检索
- 问答检索
支持的Leaderboard: 评估模型在特定任务上的表现,如F1或EM,以及从维基百科检索支持信息的能力。
数据集创建
许可证信息: CC-BY-SA-4.0
引用信息:
@inproceedings{ thakur2021beir, title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models}, author={Nandan Thakur and Nils Reimers and Andreas R{"u}ckl{e} and Abhishek Srivastava and Iryna Gurevych}, booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)}, year={2021}, url={https://openreview.net/forum?id=wCu6T5xFjeJ} }
贡献者: 感谢@Nthakur20添加此数据集。
搜集汇总
数据集介绍
背景与挑战
背景概述
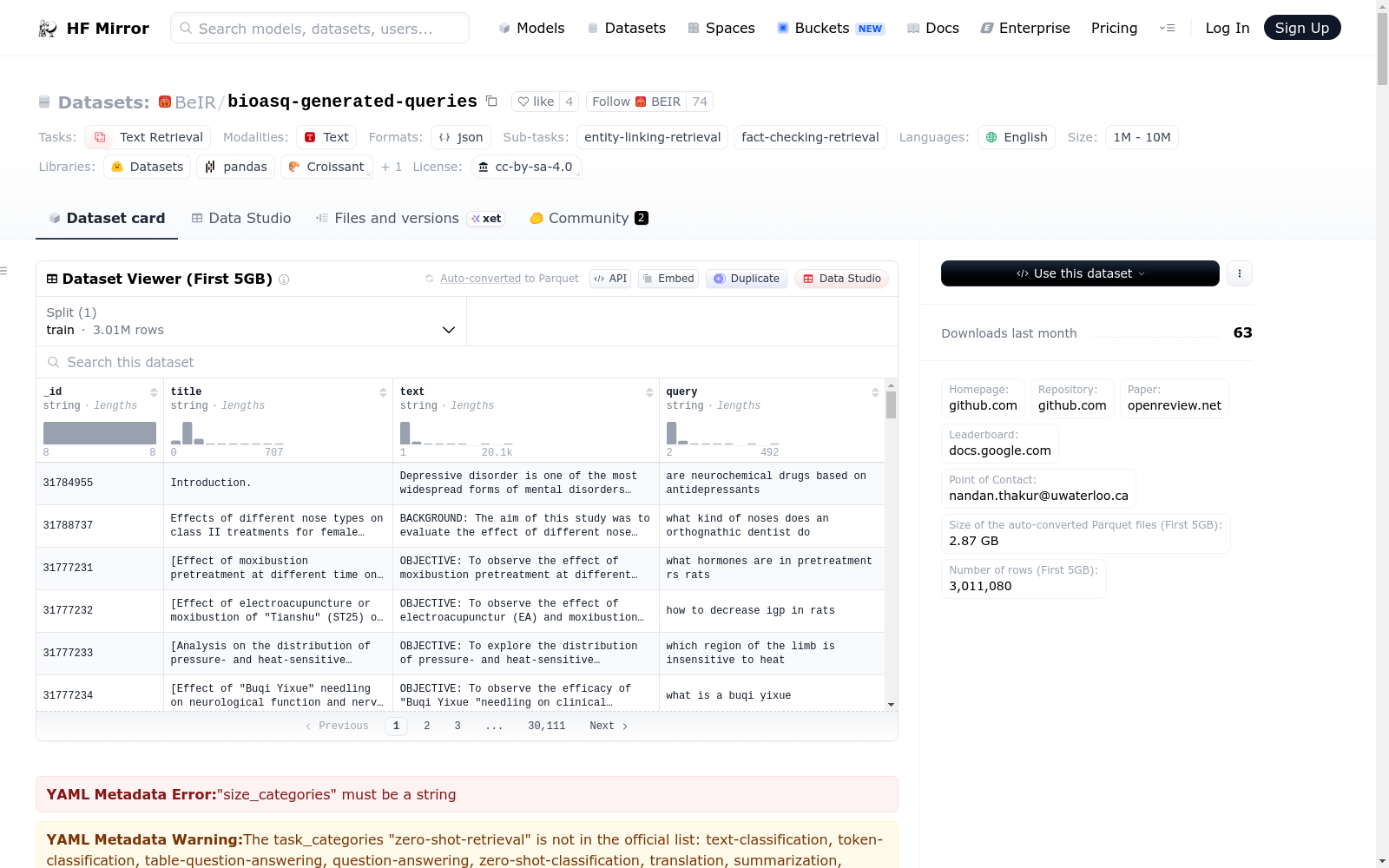
The 'BeIR/bioasq-generated-queries' dataset is a biomedical information retrieval resource within the BEIR benchmark, featuring generated queries for text retrieval tasks. It supports entity-linking and fact-checking sub-tasks, is formatted in JSON, and is available under a cc-by-sa-4.0 license. The dataset is substantial in size (1M - 10M entries) and is tailored for English-language biomedical research applications.
以上内容由遇见数据集搜集并总结生成


