medagents-benchmark
收藏Hugging Face2025-03-15 更新2025-03-16 收录
下载链接:
https://huggingface.co/datasets/super-dainiu/medagents-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
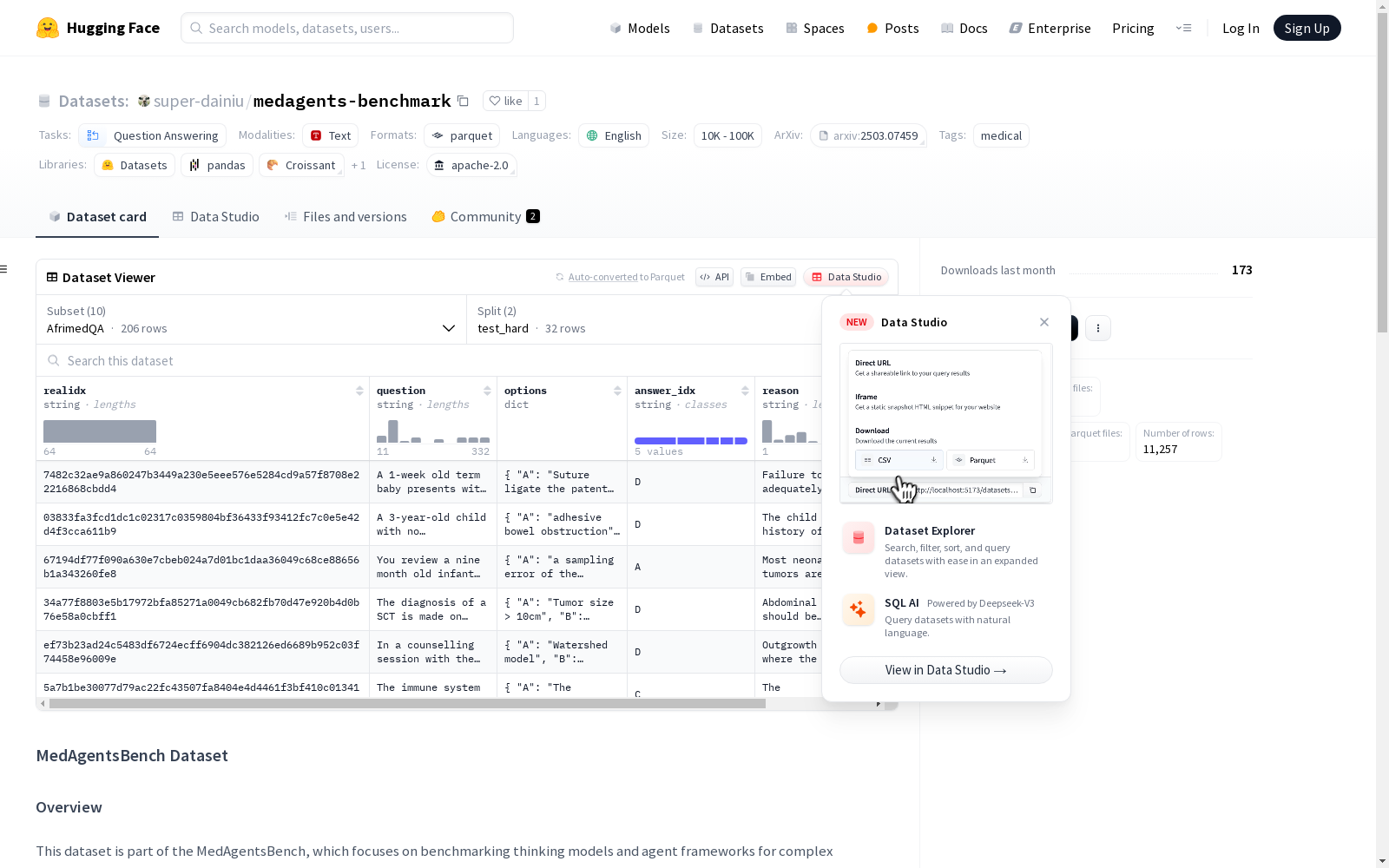
MedAgentsBench是一个医疗领域的问答数据集,它专注于为复杂医疗推理任务提供基准测试。该数据集包括多个子数据集,每个子数据集都包含针对特定医疗场景设计的问题,旨在评估模型在医疗推理方面的性能。
MedAgentsBench is a medical question answering dataset dedicated to providing benchmarking for complex medical reasoning tasks. It comprises multiple sub-datasets, each containing questions designed for specific medical scenarios, with the goal of evaluating the medical reasoning performance of models.
创建时间:
2025-03-12
搜集汇总
数据集介绍
构建方式
MedAgentsBench数据集针对医疗领域中的复杂推理问题,构建了多个子数据集,每个子数据集均包含经精心挑选的医学问题。这些问题旨在评估思维模型和代理框架在医疗推理任务上的表现。数据集通过收集不同难度级别的测试集,包括难度较高的'test_hard'和完整的'test'集,来模拟真实世界中医学问题的复杂性。
特点
该数据集的特点在于其涵盖了从非洲医疗环境到医学入学考试等多种医疗场景的问题。每个子数据集均具备不同的特征,如MedQA包含医疗领域的问题和答案,PubMedQA基于PubMed摘要提出问题,MedMCQA则是医学入学考试的多选题。此外,数据集还包含专家级别的推理和理解问题,为研究提供了丰富的多样性。
使用方法
使用MedAgentsBench数据集时,研究者可以根据具体的研究需求选择不同的子数据集和难度级别。数据集以HuggingFace的格式提供,可以通过HuggingFace的库轻松加载和进行处理。每个子数据集都包含了必要的测试集,研究者可以下载后直接用于模型评估和基准测试。
背景与挑战
背景概述
MedAgentsBench数据集是医学领域推理的基准测试,旨在评估思维模型和代理框架在复杂医学推理任务中的性能。该数据集的创建集合了多个医疗问答子数据集,涵盖了从非洲医疗环境到医学入学考试的各种问题,特别挑选了模型准确率低于50%的难题。该数据集由Tang等人于2025年提出,并在arXiv上发表了相关论文,为医学自然语言处理领域的研究提供了重要的资源和参考。
当前挑战
在构建MedAgentsBench数据集的过程中,研究人员面临了多个挑战。首先,如何确保所选问题对现有模型具有足够的难度,以检验其推理能力是一个关键挑战。其次,整合多个来源和格式不同的医疗数据集,保持数据质量和一致性,也是构建过程中的一个难点。此外,领域内的专家知识和医学文献的复杂性为构建高质量的问题和答案对带来了额外的挑战。
常用场景
经典使用场景
MedAgentsBench数据集在医学问题回答领域具有重要的应用价值,其经典使用场景主要在于为医学推理任务提供了一系列具有挑战性的问题,这些问题经过精心设计,确保了模型在复杂医疗推理场景下的性能评估具有可靠性和有效性。
实际应用
在实际应用中,MedAgentsBench数据集可用于评估和改进医疗诊断辅助系统、智能问诊机器人等人工智能产品,有助于提高医疗服务质量和效率,同时为医学教育和医学研究提供了丰富的数据资源。
衍生相关工作
基于MedAgentsBench数据集,衍生出了多项相关研究工作,包括对现有模型的改进、新型医学推理框架的提出以及跨领域知识融合等,这些研究进一步推动了医学人工智能领域的发展和应用。
以上内容由遇见数据集搜集并总结生成


