Matteo12345kgjdso/genius-lyrics
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Matteo12345kgjdso/genius-lyrics
下载链接
链接失效反馈官方服务:
资源简介:
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Dataset Card for Dataset Name
## Dataset Description
### Dataset Summary
This dataset consists of roughly 480k english (classified using nltk language classifier) lyrics with some more meta data. The id corresponds to the spotify id. The meta data was taken from the million playlist challenge @ AICrowd. The lyrics were crawled using "[song name] [artist name]" as string using the lyricsgenius python package which uses the genius.com search function. There is no guarantee that the lyrics are correct because the search is not perfect. And the data cleaning is not perfect:
### Data cleaning:
The data was first verified by using fuzzy matching since the first strings of the retrieved lyrics were always the song name itself + "Lyrics" (e.g. "HelloLyrics"). When the song names in the API request and in the resulting payload don't match, it wasn't included in this set of lyrics. This was done using the package fuzzywuzzy partial_ratio() string matching with a score of under 60, because partial_ratio() is still helpful for variants of the song like "Remix" or "feat. x" and 60 was deemed a good number for some edge cases. One special edge case was manually removed which were "This is x" lyrics which were special lyrics pages describing an artist (if a song has "this is" in it, the check will fail). Next, the song is checked whether it contains one of the key words "instrument", "non-lyric", "effect", "musical", "ambient", "vocal" and whether it is less than 25 words. These songs are classified as instrumentals and are not included.
Lastly, the following regex is applied:
#### remove text inside [] brackets
text = re.sub(\verb"[\(\{\[].*?[\)\]\}]", "", lyrics)
#### remove punctuation (\p{L} is for different language characters)
return " ".join(regex.findall(r\verb'[\\\p{L}a-zA-Z0-9]+', lyrics))
#### remove apostrophe and embed/you might also like token
return re.sub(r\verb'([Ee]mbed)+$|(\')|(\")|(’)|(,)|([Yy]ou might also like)|([Ll]ike[Ee]mbed])', "", lyrics)
### Notes/Limitations:
Some lyrics might not be fully english but have enough english to be classified as english using nltk language classifier. There is at least one outlier in length which shows the imperfect genius search.
### Genres:
49'985 rows have a list of genres, crawled from the official Spotify API. This list of genres are from the artist of the song since spotify doesn't provide genres for every individual song.
提供机构:
Matteo12345kgjdso
搜集汇总
数据集介绍
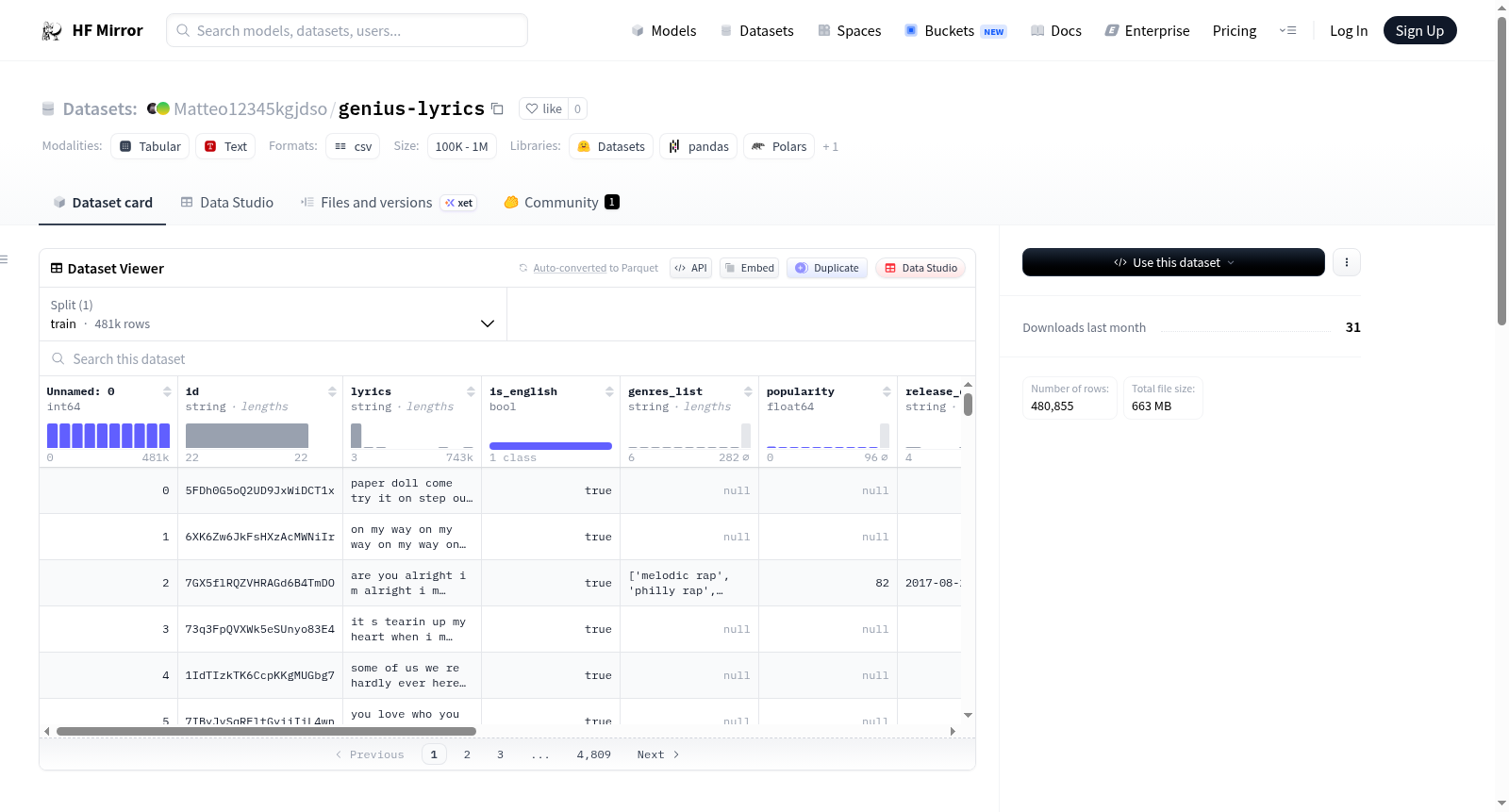
构建方式
在音乐信息检索领域,歌词数据集为自然语言处理任务提供了丰富的文本资源。genius-lyrics数据集通过整合多个数据源构建而成,其核心歌词数据源自Genius.com平台,利用lyricsgenius Python包以歌曲名称和艺术家姓名为查询字符串进行爬取。为确保数据质量,构建过程采用了模糊匹配技术,通过fuzzywuzzy包的partial_ratio()函数验证歌曲名称的一致性,匹配分数低于60的条目被排除。此外,通过关键词过滤和词数阈值(少于25词)识别并移除了器乐曲目。数据清洗环节应用了正则表达式处理,移除了括号内的文本、标点符号及特定无关标记,最终保留了以字母数字为主的歌词内容。
特点
该数据集涵盖了约48万条英文歌词,并附带了丰富的元数据信息。每条记录关联了Spotify ID,元数据来源于AICrowd的百万播放列表挑战项目,增强了数据的上下文价值。数据集特别注重语言一致性,使用nltk语言分类器确保歌词主要为英文,尽管可能存在少量非英语内容。值得注意的是,约5万行数据包含了从Spotify官方API获取的流派信息,这些流派基于艺术家层面分类,反映了音乐风格的广泛性。然而,数据集也存在局限性,例如Genius.com搜索的不完美可能导致个别歌词错误或长度异常,且流派信息未覆盖所有歌曲。
使用方法
genius-lyrics数据集适用于音乐分析、自然语言处理及推荐系统等多个研究领域。用户可通过HuggingFace平台直接访问数据集,利用其结构化格式进行数据加载和处理。在实际应用中,研究人员可结合歌词文本和元数据开展情感分析、主题建模或风格分类等任务。例如,通过Spotify ID可将歌词与音频特征关联,构建跨模态音乐推荐模型。使用前建议进行额外验证,以应对数据清洗中可能残留的噪声,并注意流派信息的局限性,确保分析结果的可靠性。数据集支持标准数据处理流程,便于集成到机器学习管道中。
背景与挑战
背景概述
在音乐信息检索与自然语言处理交叉领域,歌词数据集对于情感分析、风格识别及文化研究具有关键价值。Genius-lyrics数据集由研究人员通过整合Spotify元数据与Genius.com歌词资源构建,其核心旨在解决大规模、高质量英文歌词语料的缺失问题,为音乐语义理解与生成模型提供数据基础。该数据集通过自动化爬取与清洗流程,汇集了约48万条歌词记录,并附有艺术家流派等元信息,自发布以来显著推动了计算音乐学与歌词分析任务的研究进展。
当前挑战
该数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域层面,歌词文本的语义模糊性、文化隐喻及多语言混杂现象对情感分类、主题建模等任务构成理解障碍;同时,音乐风格与歌词内容的动态关联性增加了特征提取的复杂度。在构建过程中,数据来源的异构性导致歌词准确性难以保证,自动化搜索匹配易受歌曲别名、混音版本干扰;尽管采用了模糊匹配与规则清洗,非英语内容残留、乐器类曲目过滤不完全等数据噪声问题依然存在,限制了数据集的纯净度与应用广度。
常用场景
经典使用场景
在音乐信息检索与自然语言处理领域,genius-lyrics数据集为研究者提供了丰富的英文歌词文本资源。该数据集常被用于训练和评估歌词生成模型,支持从主题建模到情感分析等多种任务。通过结合歌曲元数据,研究人员能够深入探索歌词的语言风格、文化内涵及其与音乐特征的关联,为跨模态分析奠定基础。
实际应用
在实际应用中,genius-lyrics数据集为音乐推荐系统与内容创作工具提供了核心语料。基于歌词相似性的推荐算法能够增强流媒体平台的个性化体验,而自动作词辅助系统则可激发艺术家的创作灵感。此外,该数据在品牌营销与文化研究中亦能用于分析公众情绪与趋势。
衍生相关工作
围绕该数据集衍生的经典工作包括基于Transformer的歌词生成模型、结合音频特征的跨模态检索系统,以及针对流派分类的深度学习框架。这些研究不仅拓展了歌词在人工智能中的表示方法,还为音乐信息学引入了新的评估基准,持续影响着相关领域的算法创新。
以上内容由遇见数据集搜集并总结生成


