BeyondDialogue
收藏Hugging Face2024-08-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/yuyouyu/BeyondDialogue
下载链接
链接失效反馈官方服务:
资源简介:
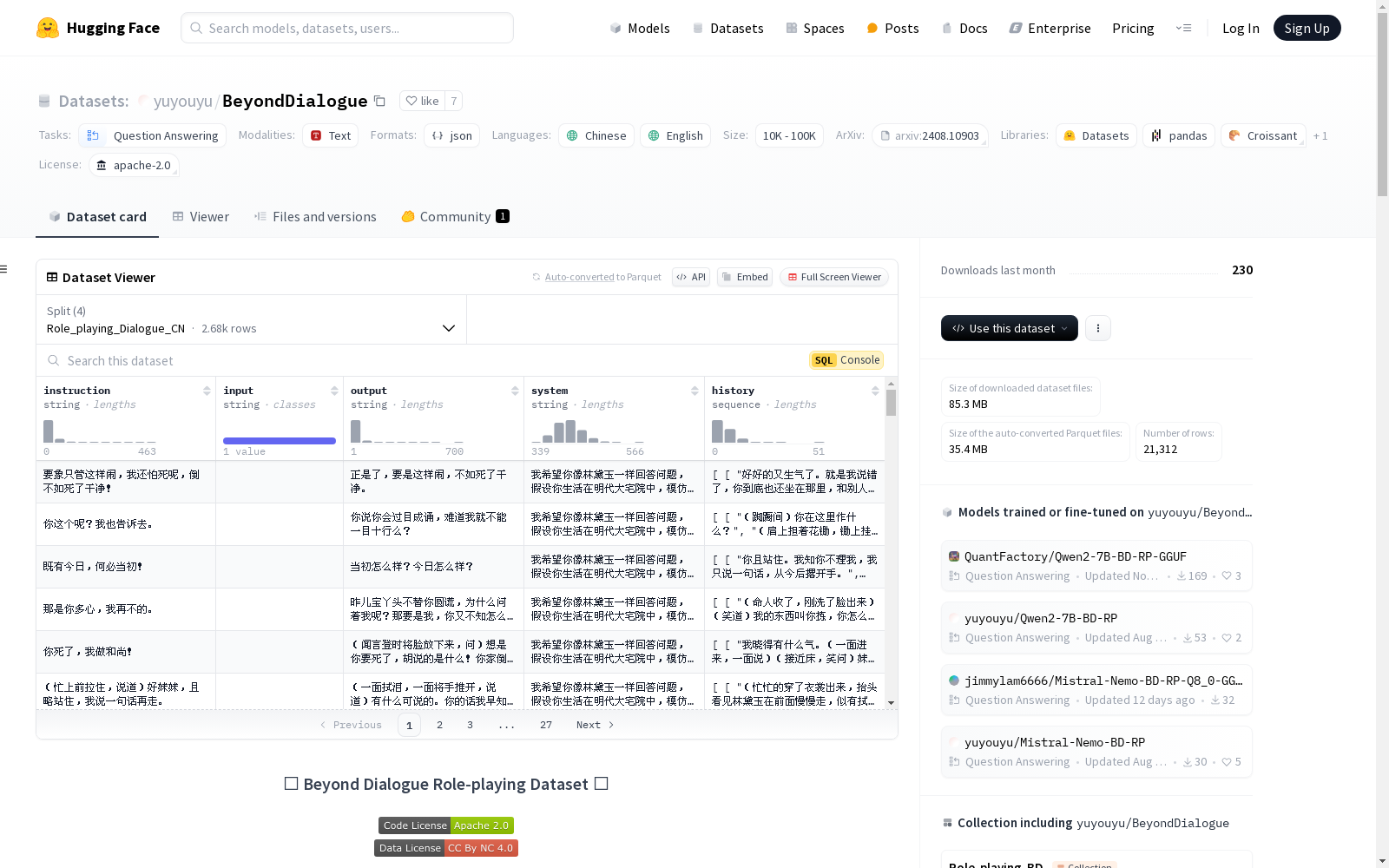
Beyond Dialogue Role-Playing Dataset是一个全面的数据集,旨在推动角色扮演模型研究。该数据集包含从小说中提取的真实角色对话数据,以及超越简单对话交换的复杂推理任务。数据集支持中文和英文,包含多个配置文件,每个配置文件对应不同的数据文件。数据集的统计信息显示,该数据集具有多语言、多轮对话的特点,并且角色和对话会话数量丰富。
The Beyond Dialogue Role-Playing Dataset is a comprehensive dataset designed to advance research on role-playing models. This dataset contains real character dialogue data extracted from novels, as well as complex reasoning tasks that go beyond simple conversational exchanges. It supports both Chinese and English, and includes multiple configuration files, each corresponding to a distinct data file. Statistical analyses of the dataset reveal that it features multilingual and multi-turn dialogues, with a rich number of characters and conversational sessions.
创建时间:
2024-08-29
原始信息汇总
Beyond Dialogue Role-playing Dataset
概述
Beyond Dialogue Role-Playing Dataset 是一个全面的角色扮演模型研究数据集,包含以下特点:
- 真实角色对话数据:从小说中提取的真实对话,包含角色之间丰富的上下文交互。
- 超越对话的对齐推理任务:除了对话,数据集还包括对齐推理任务,挑战模型进行复杂的推理,超越简单的对话交换。
数据文件结构
- 角色扮演数据
RPA_CN_SFT.json和RPA_EN_SFT.json:包含中英文的对齐角色扮演对话。RP_CN_SFT.json和RP_EN_SFT.json:包含中英文的非对齐角色扮演对话。
- 对齐任务
CSERP_CN_SFT.json和CSERP_EN_SFT.json:包含中英文的角色、风格、情感、关系和个性维度的对齐推理任务。
- 对话块
ChunkDialogues_CN和ChunkDialogues_EN:包含中英文的角色资料和对话,以及对话源块。
数据集统计
- 从123本中英文小说或剧本中提取了280个中文角色和31个英文角色。
- 总共获得了3,552个场景对话会话,包含23,247个对话轮次。
下载
可以通过以下代码从Hugging Face Datasets Hub下载数据集: bash git lfs install git clone https://huggingface.co/datasets/yuyouyu/BeyondDialogue
python from datasets import load_dataset
dataset = load_dataset("yuyouyu/BeyondDialogue")
引用
如果使用此数据集,请引用以下论文: bibtex @article{yu2024beyond, title = {BEYOND DIALOGUE: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model}, author = {Yu, Yeyong and Yu, Runsheng and Wei, Haojie and Zhang, Zhanqiu and Qian, Quan}, year = {2024}, journal = {arXiv preprint arXiv:2408.10903} }
搜集汇总
数据集介绍
构建方式
BeyondDialogue数据集的构建基于从小说中提取的真实角色对话数据,涵盖了中英文两种语言。通过从123部中英文小说或剧本中提取280个中文角色和31个英文角色,构建了3552个场景对话,共计23247个对话轮次。此外,数据集还包含了角色、风格、情感、关系和个性五个维度的对齐推理任务,进一步丰富了数据集的复杂性。
使用方法
BeyondDialogue数据集可通过Hugging Face Datasets Hub下载,用户可以使用`git clone`命令或`load_dataset`函数加载数据集。数据集文件结构清晰,包含角色扮演对话和对齐推理任务两部分,分别以JSON格式存储。用户可以根据需要选择中文或英文数据进行模型训练或评估,具体使用方法可参考数据集提供的论文和GitHub仓库。
背景与挑战
背景概述
BeyondDialogue数据集由Yeyong Yu等人于2024年提出,旨在推动角色扮演语言模型的研究。该数据集主要来源于小说中的真实对话,涵盖了280个中文角色和31个英文角色,总计3552个对话场景和23247个对话轮次。通过引入角色-对话对齐任务,BeyondDialogue不仅提供了丰富的多轮对话数据,还扩展了模型在角色特征、风格、情感、关系和个性等多维度的推理能力。该数据集的开源特性及其多语言支持使其在角色扮演模型的研究中具有广泛的应用前景,并为相关领域的研究者提供了宝贵的资源。
当前挑战
BeyondDialogue数据集在构建过程中面临多重挑战。首先,从小说中提取真实对话并确保其与角色特征的对齐是一项复杂的任务,需要精确的文本分析和标注。其次,数据集的多语言特性增加了数据处理的难度,尤其是在保持不同语言间一致性的同时,确保数据的质量和多样性。此外,对齐推理任务的引入要求模型不仅能够处理简单的对话,还需具备深层次的推理能力,这对模型的训练和评估提出了更高的要求。这些挑战共同构成了BeyondDialogue数据集在推动角色扮演语言模型研究中的核心难题。
常用场景
经典使用场景
BeyondDialogue数据集在角色扮演语言模型的研究中具有重要应用。该数据集通过从小说中提取的真实角色对话数据,为模型提供了丰富的上下文交互场景。研究者可以利用这些数据训练模型,使其在角色扮演任务中表现出更高的对话质量和情境理解能力。特别是在多轮对话和角色对齐任务中,该数据集为模型提供了复杂的推理挑战,推动了角色扮演模型的进一步发展。
解决学术问题
BeyondDialogue数据集解决了角色扮演语言模型在对话生成和角色对齐方面的关键问题。通过提供真实的角色对话数据和对齐推理任务,该数据集帮助研究者克服了模型在复杂情境下对话生成的困难。特别是在角色性格、情感、关系等多维度的对齐任务中,数据集为模型提供了丰富的训练素材,显著提升了模型在角色扮演任务中的表现。这一数据集的出现,填补了角色扮演模型研究中的数据空白,推动了该领域的学术进展。
实际应用
BeyondDialogue数据集在实际应用中具有广泛的前景。例如,在虚拟助手、游戏角色对话系统以及教育领域的角色扮演教学中,该数据集可以为模型提供真实的对话场景,提升用户体验。特别是在多语言环境下,数据集的中英文双语特性使其能够支持跨语言的对话生成任务。此外,数据集中的对齐推理任务也为模型在复杂情境下的推理能力提供了训练基础,进一步拓展了其在实际应用中的潜力。
数据集最近研究
最新研究方向
在角色扮演语言模型的研究领域,BeyondDialogue数据集通过引入真实小说中的对话数据和对齐推理任务,推动了模型在复杂情境下的推理能力。该数据集不仅包含了丰富的多轮对话,还特别设计了角色、风格、情感、关系和个性五个维度的对齐任务,旨在提升模型在角色扮演中的表现。这一研究方向与当前大语言模型在个性化对话生成和情感计算领域的热点问题密切相关,尤其是在多语言和多角色情境下的应用。通过提供真实且多样化的对话场景,BeyondDialogue为研究者提供了一个全新的视角,以探索角色扮演模型在更广泛场景中的潜力。
以上内容由遇见数据集搜集并总结生成


