LieUr/Qwen2-0.5B-Instruct_gsm8k_oai_contrastive
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/LieUr/Qwen2-0.5B-Instruct_gsm8k_oai_contrastive
下载链接
链接失效反馈官方服务:
资源简介:
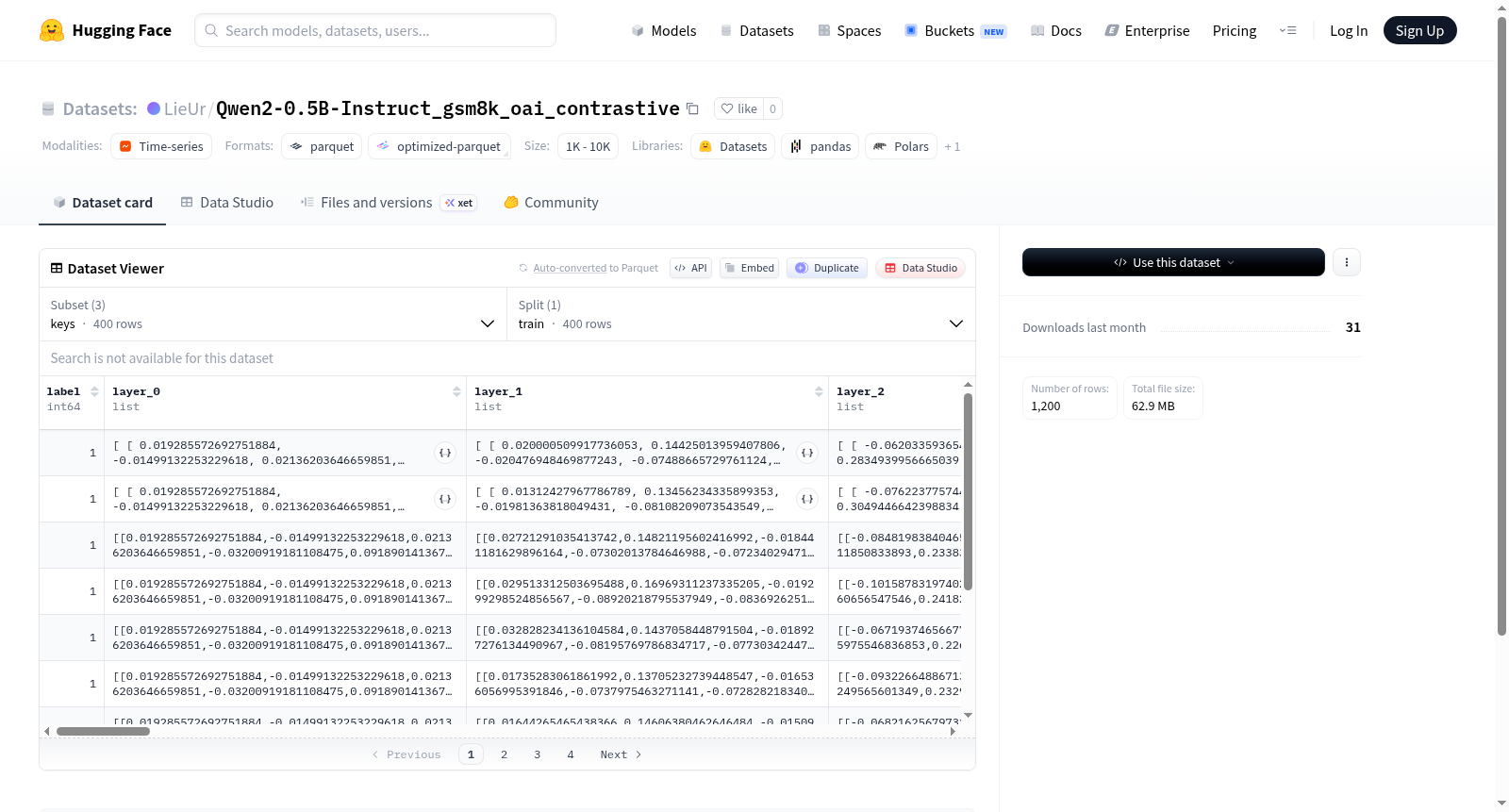
该数据集包含三个配置:keys、residuals和values,每个配置用于存储神经网络模型(可能为Transformer架构)的中间层表示。keys和values配置包含label字段(int64类型)和24个layer_*字段(每个字段为float32类型的嵌套列表,表示多层结构),而residuals配置包含label字段和24个layer_*字段(每个字段为float32类型的单层列表)。所有配置仅包含训练集(train),各有400个示例,总数据大小从约5MB到34MB不等。数据集可能用于分析或训练与模型层表示相关的任务,如特征提取或可视化。
This dataset includes three configurations: keys, residuals, and values, each designed to store intermediate layer representations of a neural network (likely a Transformer architecture). The keys and values configurations contain a label field (int64 type) and 24 layer_* fields (each as a nested list of float32, representing multi-layer structures), while the residuals configuration contains a label field and 24 layer_* fields (each as a single-layer list of float32). All configurations consist only of a training set (train) with 400 examples each, and total data sizes range from approximately 5MB to 34MB. The dataset may be used for analysis or training tasks related to model layer representations, such as feature extraction or visualization.
提供机构:
LieUr
搜集汇总
数据集介绍
构建方式
该数据集基于Qwen2-0.5B-Instruct模型在GSM8K数学推理任务上的推理过程构建而成,采用了对比学习的思想(oai_contrastive)。数据集包含三个子配置:keys、residuals和values,分别存储了模型各隐藏层(共24层)的键向量、残差流向量和值向量。每个样本对应一个数学问题,通过模型前向传播提取各层特征,并以浮点数列表形式保存,总共包含400个训练样本。这种构建方式旨在捕捉模型在推理过程中不同层次的内部表征,为后续的机制分析或表征学习提供高维特征数据。
使用方法
使用时,可通过HuggingFace Datasets库加载数据集,并指定所需子配置,例如`load_dataset('Qwen2-0.5B-Instruct_gsm8k_oai_contrastive', 'keys')`。每个样本的layer_0至layer_23字段可直接作为模型中间层表征,配合label进行监督学习或对比分析。建议对层向量进行降维(如PCA或t-SNE)后进行可视化,或将其作为特征输入下游分类器。由于数据规模较小,适合在GPU环境下快速迭代实验,也可用于微调小型代理模型或探测(probing)任务。
背景与挑战
背景概述
该数据集名为Qwen2-0.5B-Instruct_gsm8k_oai_contrastive,诞生于大语言模型可解释性研究蓬勃发展的时期,由致力于探索模型内部机制的研究团队构建。其核心研究问题在于揭示Qwen2-0.5B-Instruct模型在解决GSM8K数学推理问题时,其各层隐藏状态与最终输出之间的内在关联。数据集通过采集模型在400个样本上的层激活值、残差连接输出及注意力键值等中间表征,为分析链式推理过程中信息的逐层传递与转换提供了宝贵素材。这一资源极大推动了神经符号推理与模型透明度领域的发展,为后续基于对比学习的方法论验证奠定了坚实基础。
当前挑战
该数据集所应对的领域问题在于,大语言模型虽在数学推理任务上表现卓越,但其内部推理逻辑常被视为难以捉摸的黑箱,缺乏对中间过程的可视化与量化手段,限制了模型的可靠性与可信度。构建过程中面临的双重挑战尤为突出:其一,精准捕获并区分‘keys’、‘values’及‘residuals’三类关键特征,需确保数据维度与语义对齐,避免信息丢失或噪声干扰;其二,有限的400个训练样本虽聚焦于典型推理路径,却难以覆盖GSM8K中多样化的解题策略与错误范式,对模型泛化能力的评估构成潜在制约。
常用场景
经典使用场景
Qwen2-0.5B-Instruct_gsm8k_oai_contrastive数据集的核心价值在于对轻量级语言模型Qwen2-0.5B-Instruct进行数学推理任务中的内部表征分析。该数据集记录了模型在GSM8K数据集(小学数学应用题)上运行时,每一层Transformer模块的隐藏状态(keys、values)和残差流(residuals),共涵盖24个层次。研究人员可借此剖析小模型在复杂的数学推理链条中如何逐步编码、传递和整合信息,尤其关注模型在回答正确与错误样本时内部表示的差异。通过对比分析,能够揭示模型在推理过程中的关键决策节点和表示变化规律。
解决学术问题
该数据集致力于解决解释机器学习模型中数学推理机制的难题。GSM8K作为典型的数学推理测试基准,要求模型展现多步逻辑推理能力,而Qwen2-0.5B-Instruct这类参数较少的模型常因其“黑箱”特性而难以解释。此数据集通过提供每一层的高维中间表征(keys、values和residuals),使研究者能够追踪数学推理过程中的信息流向,探索模型在处理复杂问题时是否存在语义漂移或信息丢失。其意义在于降低模型可解释性的门槛,为设计更稳健、更可解释的小参数模型提供实证依据。
实际应用
在实际应用中,此数据集主要服务于AI可解释性工程和模型调试领域。开发者可利用其包含的中间层激活值来诊断Qwen2-0.5B-Instruct在数学推理任务中的错误模式,进而通过对比正确和错误推理轨迹,实现针对性的模型微调或参数优化。对于教育科技公司,该数据集有助于开发具备透明推理过程的数学辅导AI系统;在自动驾驶、金融风控等对可解释性要求严苛的场景中,类似的推理追踪技术也能被借鉴用于验证模型决策的合理性。
数据集最近研究
最新研究方向
该数据集聚焦于Qwen2-0.5B-Instruct模型在GSM8K数学推理任务中的内部表征解析,通过对比学习方法(contrastive learning)记录模型各层的键(keys)、残差(residuals)和值(values)状态,为揭示大语言模型在数学推理过程中的计算机制提供了微观层面的数据支撑。当前,随着可解释AI研究的深入,利用此类层级激活数据探索模型推理逻辑、定位关键决策层成为前沿热点,尤其在与AI安全、模型对齐等事件关联下,该数据集有助于从内部表征角度验证模型推理的稳健性与可解释性,对推动透明化、可信赖的大模型发展具有重要理论价值。
以上内容由遇见数据集搜集并总结生成


