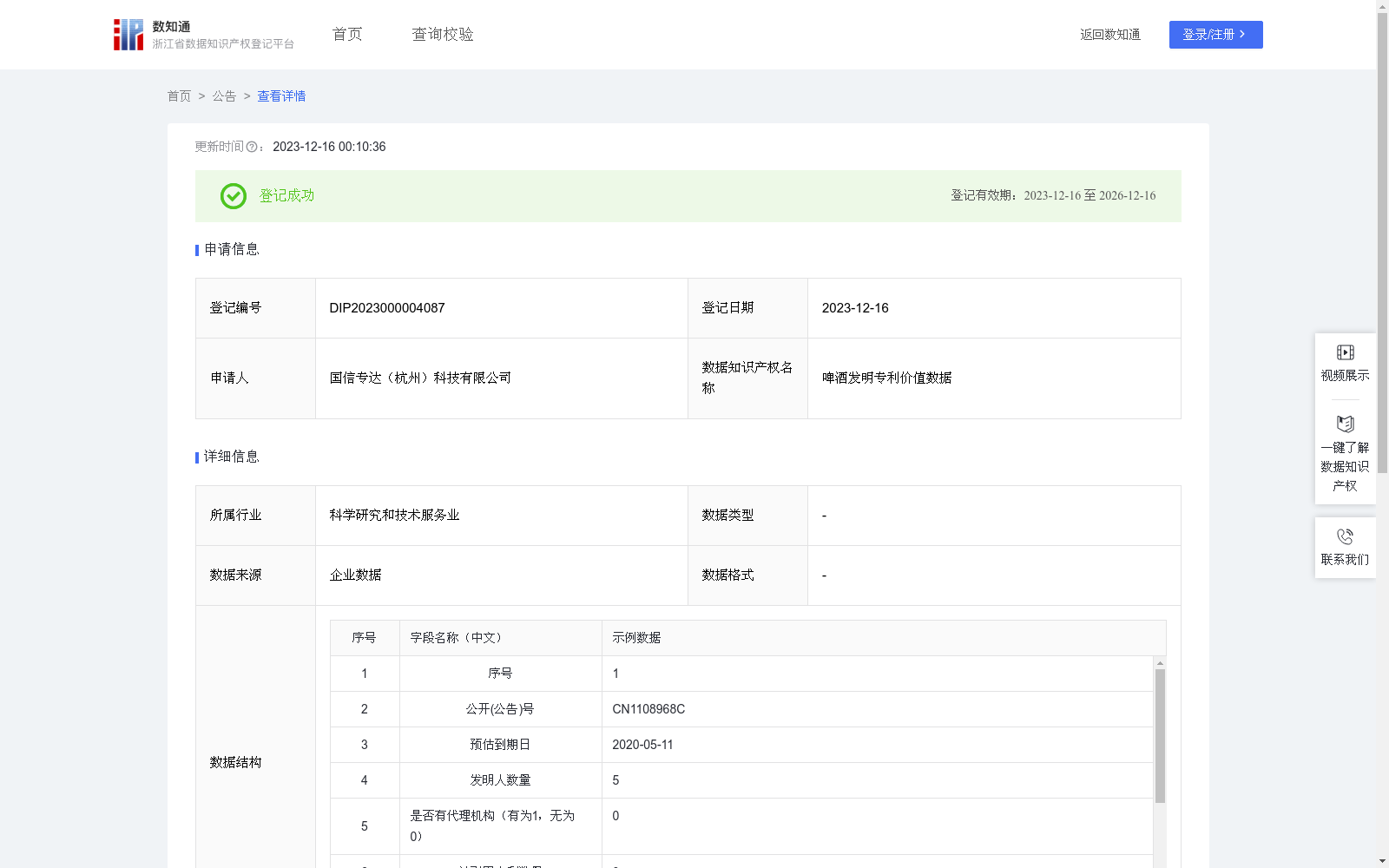
啤酒发明专利价值数据
收藏浙江省数据知识产权登记平台2023-12-16 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/20551
下载链接
链接失效反馈官方服务:
资源简介:
根据自定规则对啤酒专利数据进行检索分析,了解啤酒发明专利情况,有助于啤酒成果转化,也有利于了解啤酒技术发展趋势及核心技术,有助于企业避免重复研发及侵犯他人的知识产权。数据来源:中国专利数据库中有关啤酒发明的专利数据。算法规则:本数据基于 AHP 模型,从专利有效期、发明人数量、代理机构情况、被引用次数、引用次数、同族专利数、权利要求数以及诉讼案件数八大价值维度,赋予相应的系数,并将八类价值之和定义为专利综合价值,利用IFS函数对专利进行价值判定,用于评价现有专利价值,为本领域技术人员、市场主体、成果转化机构提供技术支撑。算法规则包括:1.专利有效期得分为今日(数据下载当天即2023年11月09日)至预估到期日(预估到期日在今日之前的,仍以原公式计算,虽然可能此项分数为负分,但是专利到期后仍具有价值)年份数,每年算1分; 2.发明人数量得分为发明人人数,每有1人算1分; 3.代理机构情况得分,有为5分,没有为0分; 4.被引用次数得分,每被引用1次+10分; 5.引用次数,每引用1次+2分; 6.同族专利数,每多一个其他同族专利+1分,以1个为基准; 7.权利要求数,以10条权利要求为基准,每少1条-1分,每多1条+1分; 8.诉讼案件数,每有一次诉讼案件+50分。 最后得出来的分数取整,即四舍五入。
Retrieve and analyze beer-related patent data following self-defined rules to gain insights into beer-related invention patents. This facilitates the commercialization of beer technological achievements, helps understand the development trends and core technologies of the beer industry, and enables enterprises to avoid redundant R&D and intellectual property infringement.
Data Source: Patent data related to beer inventions from the Chinese Patent Database.
Algorithm Rules: This dataset is based on the AHP (Analytic Hierarchy Process) model. Eight value dimensions, including patent validity period, number of inventors, agency status, number of citations received, number of citations made, number of patent family members, number of claims, and number of litigation cases, are assigned corresponding coefficients, and the sum of the eight types of value metrics is defined as the comprehensive patent value. The IFS function is used to conduct patent value judgment, which serves to evaluate the value of existing patents and provide technical support for persons skilled in the art, market entities, and achievement transformation institutions. The detailed algorithm rules are as follows:
1. Patent validity period score: The score is calculated as the number of years from today (November 09, 2023, the date when the data was downloaded) to the estimated expiration date. If the estimated expiration date is prior to today, the original formula is still applied for calculation; although this score may be negative, patents still hold value after expiration, with 1 point awarded per year.
2. Number of inventors score: The score equals the number of inventors, with 1 point granted per inventor.
3. Agency status score: 5 points if a patent agency is involved, 0 points otherwise.
4. Received citations score: +10 points for each citation received by the patent.
5. Made citations score: +2 points for each citation made by the patent.
6. Patent family count score: +1 point for each additional patent family member beyond the baseline of 1 family patent.
7. Number of claims score: Taking 10 claims as the baseline, -1 point for each claim fewer than 10, and +1 point for each claim more than 10.
8. Litigation cases score: +50 points for each litigation case related to the patent.
The final calculated score is rounded to the nearest integer.
提供机构:
国信专达(杭州)科技有限公司
创建时间:
2023-11-14
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


