CRPO
收藏Hugging Face2025-03-02 更新2025-03-03 收录
下载链接:
https://huggingface.co/datasets/declare-lab/CRPO
下载链接
链接失效反馈官方服务:
资源简介:
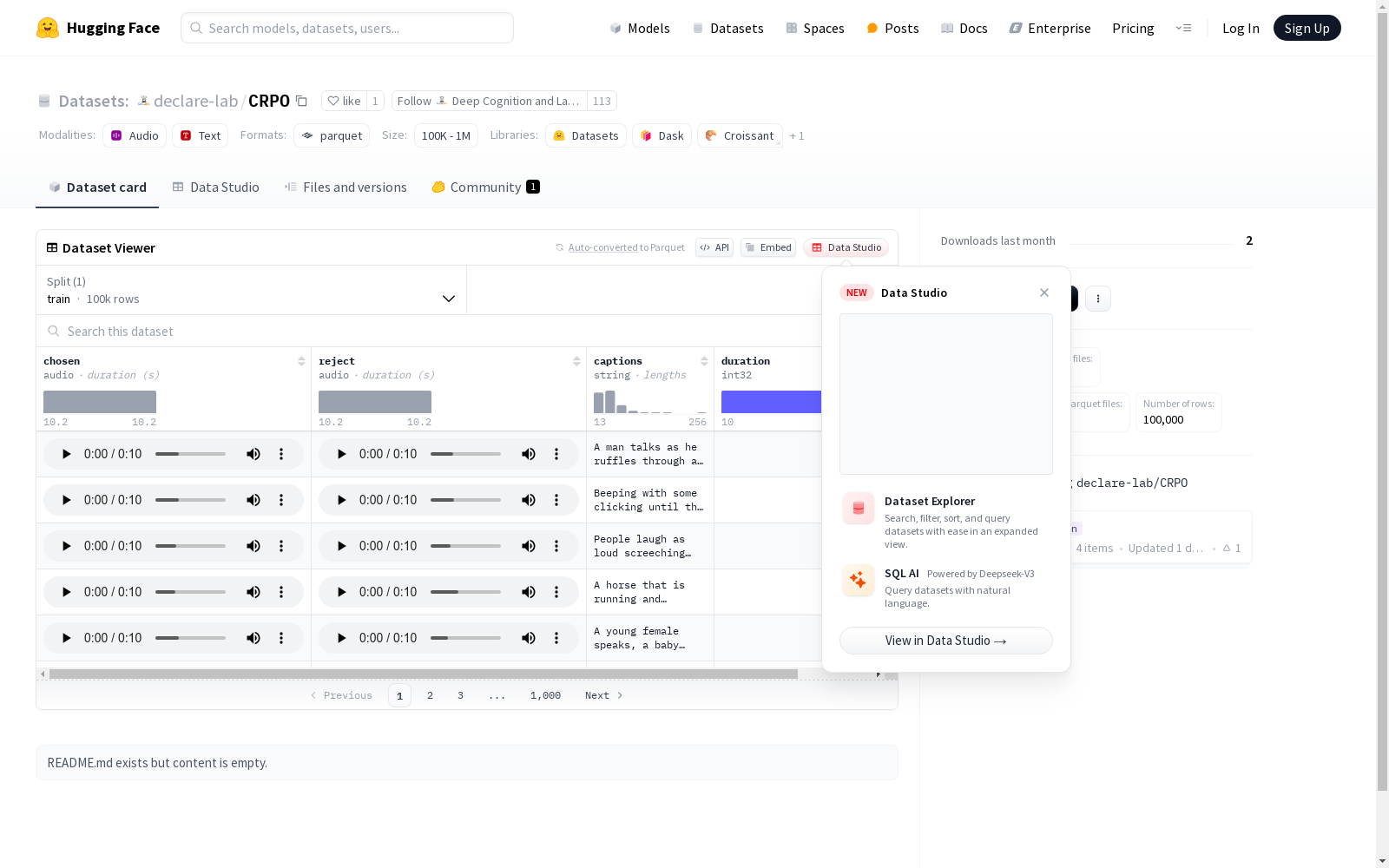
该数据集包含音频片段及其相关信息,每个音频片段都有两个版本:选中的(chosen)和拒绝的(reject),两者的采样率均为44100。此外,每个音频片段还配有序幕(captions)、持续时间(duration)和迭代次数(iteration)信息。训练集共有100000个示例,数据集总大小为约171TB。
This dataset contains audio clips and their associated metadata. Each audio clip has two versions: the chosen and the rejected, both with a sampling rate of 44100 Hz. Additionally, each audio clip is accompanied by captions, duration, and iteration information. The training set comprises 100,000 examples, and the total size of the dataset is approximately 171 TB.
提供机构:
Deep Cognition and Language Research (DeCLaRe) Lab
创建时间:
2025-02-27
搜集汇总
数据集介绍
构建方式
CRPO数据集的构建采取了对音频文件进行分类与标注的方式。该数据集由训练集组成,包含了音频文件、字幕文本、音频时长及迭代次数等信息。音频文件分为两类:被选中的音频(chosen)和被拒绝的音频(reject),均采用44100Hz的采样率,确保音频质量与一致性。
特点
CRPO数据集的特点体现在其丰富的音频数据及详细的标注信息上。它不仅提供了大量的音频样本,还附带了相应的字幕(captions),便于研究者在进行语音识别、音频分类等任务时,进行多模态的数据融合研究。此外,数据集的规模较大,提供了足够的训练样本以支持深度学习模型的训练。
使用方法
使用CRPO数据集时,用户首先需要下载整个数据集,其下载大小约为172GB。数据集以训练集的形式组织,用户可以根据自己的研究需求,利用数据集中的音频文件和字幕文本开展相应的语音识别、音频分类或多模态学习任务。数据集的每个音频文件都伴随着必要的元信息,如音频时长和迭代次数,方便用户进行数据预处理和模型训练。
背景与挑战
背景概述
CRPO数据集,作为音频处理领域的一项重要资源,其创建旨在推进音频识别与理解技术的发展。该数据集由专业研究团队于近年构建,涵盖了大量的音频片段,每一段音频均附带有选择标签、拒绝标签、文字描述以及时长和迭代次数等信息。CRPO数据集自推出以来,已经在音频分类、情感识别等研究中发挥了关键作用,为学术界和工业界提供了宝贵的资源。
当前挑战
尽管CRPO数据集为研究领域带来了巨大便利,但在实际应用中也面临着诸多挑战。首先,数据集的构建过程中确保音频质量与标注准确性是一项重大挑战。其次,由于数据集规模庞大,处理和存储这些数据对计算资源提出了较高要求。此外,如何在众多音频特征中提取有效信息,解决领域问题,如音频分类和情感识别,亦是当前研究的热点难题。
常用场景
经典使用场景
在音频处理与理解研究领域,CRPO数据集以其丰富的音频采样率和精确的字幕标注,成为研究者的首选资源。该数据集通常被用于音频分类任务,如区分用户选定的音频(chosen)与拒绝的音频(reject),进而训练模型以实现高精度的音频内容识别。
实际应用
在实际应用中,CRPO数据集被广泛应用于语音助手、智能推荐系统以及音频内容审核等领域。通过该数据集训练的模型能够准确识别用户意图,有效提升用户体验,并为内容提供商提供了智能审核工具。
衍生相关工作
基于CRPO数据集的研究成果,已经衍生出一系列相关工作,如音频指纹识别、音频内容自动标注系统等,这些工作不仅拓宽了音频处理技术的应用范围,也推动了音频分析领域的技术进步。
以上内容由遇见数据集搜集并总结生成


