GlobalQA
收藏arXiv2025-11-04 更新2025-11-01 收录
下载链接:
https://huggingface.co/datasets/QiiLuoo/GlobalQA
下载链接
链接失效反馈官方服务:
资源简介:
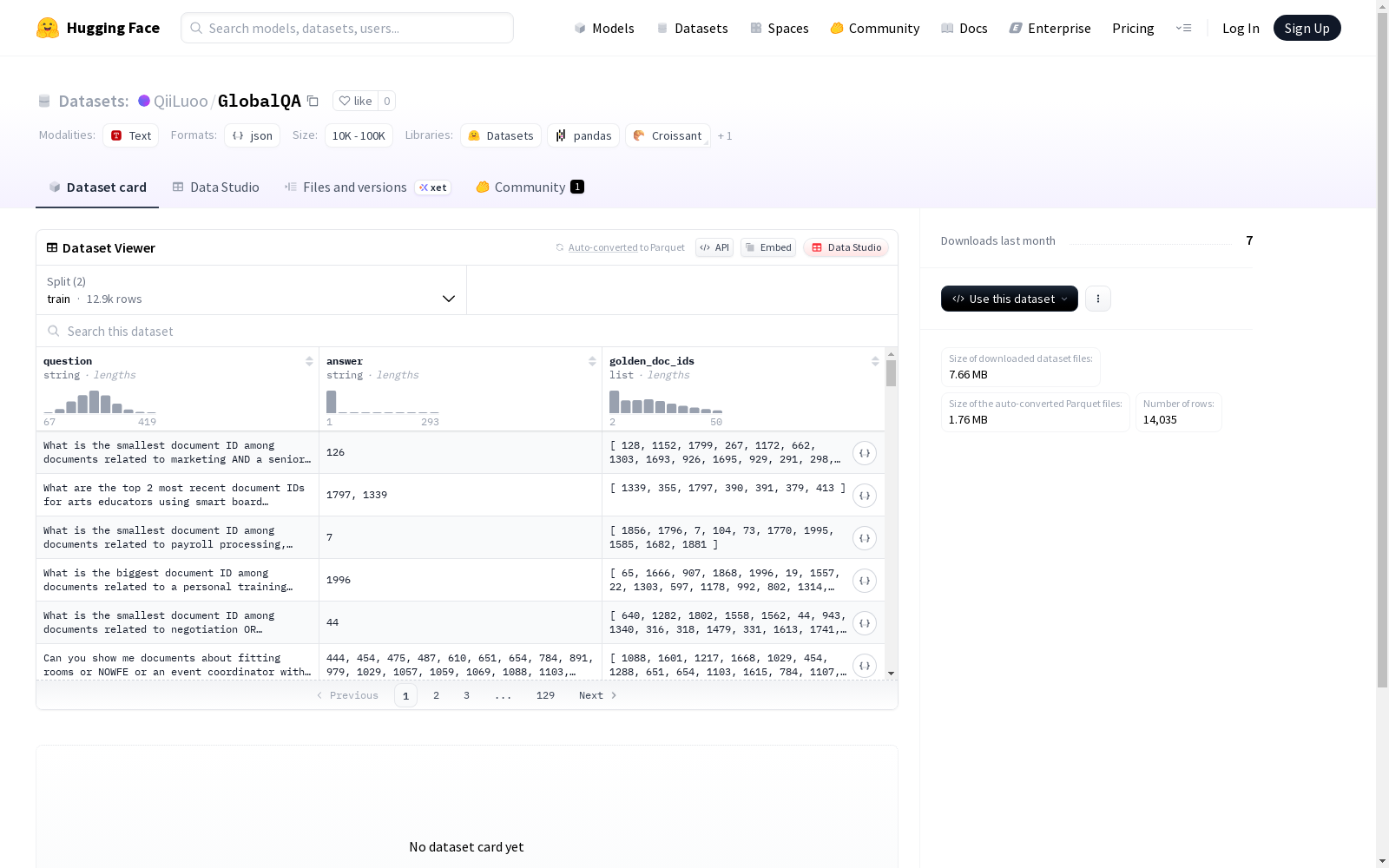
GlobalQA是一个用于评估检索增强生成(RAG)系统在全局范围内的聚合能力的基准数据集。该数据集包含超过13000个问答对,构建在超过2000个真实世界简历的语料库上,涵盖23个专业领域。GlobalQA定义了四种核心任务类型:计数、极值查询、排序和Top-k提取,这些任务全面评估了模型在统计、比较、排名和提取方面的能力。与现有基准不同,GlobalQA的查询需要遍历大量的文档集,确保模型能够进行真正的全局推理。数据集的构建采用反向策略,通过程序设计查询轨迹,然后由代理执行这些轨迹以获得确定性答案,最后基于完成的轨迹生成自然语言问题。
GlobalQA is a benchmark dataset for evaluating the global-scale aggregation capabilities of Retrieval-Augmented Generation (RAG) systems. This dataset contains over 13,000 question-answer pairs, built upon a corpus of more than 2,000 real-world resumes, covering 23 professional domains. GlobalQA defines four core task types: counting, extremum query, sorting, and Top-k extraction, which comprehensively evaluate the model's capabilities in statistical processing, comparison, ranking, and information extraction. Unlike existing benchmarks, the queries in GlobalQA require traversing a large document collection, ensuring that the model can perform true global reasoning. The dataset is constructed using a reverse strategy: query trajectories are designed via programs, then agents execute these trajectories to obtain deterministic answers, and finally natural language questions are generated based on the completed trajectories.
提供机构:
复旦大学
创建时间:
2025-10-30
搜集汇总
数据集介绍
构建方式
GlobalQA数据集采用逆向构建策略,通过程序化设计查询轨迹并分阶段执行。系统首先生成包含任务类型、领域范围和操作步骤的自动配置,随后利用DeepSeek模型遍历语料库进行文档检索与验证,确保轨迹执行的确定性。在自然语言生成阶段,系统将结构化轨迹转化为自然语言问题,并通过模板化机制保证问题与答案的逻辑一致性。最终通过文档数量筛选和异常轨迹过滤,形成包含1.3万对问答的高质量语料。
特点
该数据集聚焦于语料级推理任务,涵盖统计、极值查询、排序和Top-k提取四类核心任务。其显著特征在于查询需遍历2至50个文档,42.6%的查询要求处理超过20个文档,突破了传统多跳问答的文档数量限制。数据集基于2000余份真实简历构建,覆盖23个专业领域,关键词分布呈现长尾特性,既包含高频概念如“经验”“管理”,也涵盖领域特异性词汇,有效评估模型在全局信息聚合与噪声干扰下的稳健性。
使用方法
使用GlobalQA时需采用文档级检索策略,将完整文档作为检索单元以保持结构完整性。建议部署LLM驱动的过滤模块消除语义相关但事实无关的噪声文档,并通过计数、极值、排序和Top-k四类专用工具执行符号计算。评估时采用标准F1分数衡量答案质量,同时使用文档F1@k指标评估检索文档覆盖度,确保系统在语料级统计、比较和排序任务中实现神经推理与符号计算的协同优化。
背景与挑战
背景概述
随着大语言模型在知识密集型任务中的广泛应用,检索增强生成技术成为缓解模型幻觉问题的关键路径。GlobalQA由复旦大学计算机学院团队于2025年提出,作为首个专门评估全局检索增强生成能力的基准数据集。该数据集聚焦于解决跨文档集合的语料级推理问题,涵盖统计计算、极值查询、排序检索和Top-k提取四类核心任务,其构建基于2000余份真实行业简历形成的多领域文档集合。该研究填补了现有基准仅关注局部文档检索的空白,为评估模型在真实场景下进行全局信息聚合的能力提供了标准化测试环境。
当前挑战
在解决语料级推理问题时,现有方法面临三重核心挑战:固定粒度分块机制破坏文档结构完整性,导致元数据与实体属性分离引发统计误差;稠密检索器返回语义相关但事实无关的噪声文档,挤占有限上下文窗口并干扰推理过程;大语言模型在数值计算与统计推理方面存在固有局限,即使获取完整信息仍易产生计数偏差和排序不一致。构建过程中需克服大规模文档遍历与验证的技术难题,通过逆向构建策略确保轨迹执行的确定性,并设计多阶段流水线实现程序化问题生成与答案验证的闭环。
常用场景
经典使用场景
在检索增强生成技术领域,GlobalQA数据集主要应用于评估模型在语料库级别推理任务中的表现。该数据集通过设计四种核心任务类型——计数查询、极值查询、排序操作和Top-k提取,系统性地检验模型从大规模文档集合中聚合信息的能力。研究人员利用这一基准测试工具,能够深入分析现有RAG方法在处理需要跨文档全局分析任务时的性能瓶颈,为开发更先进的语料库级推理算法提供实证依据。
实际应用
在现实应用场景中,GlobalQA数据集支撑的全局RAG技术能够显著提升知识密集型系统的决策质量。例如在企业智能分析领域,系统可以基于数千份员工简历自动识别“经验最丰富的技术领域”或“发表论文最多的研究人员”;在学术研究场景中,能够快速统计“某领域高被引论文分布”或“跨机构合作模式”。这些应用不仅要求系统检索相关文档,更需要具备跨文档聚合分析和统计推理的能力,GlobalQA为此类复杂任务的算法优化提供了标准化测试环境。
衍生相关工作
基于GlobalQA数据集的评估结果,研究社区衍生出多项创新性工作。GlobalRAG框架通过文档级检索、智能过滤器和聚合工具的协同设计,在Qwen2.5-14B模型上实现了6.63的F1分数,较基线方法提升5.12个点。这一成果启发了后续研究对混合架构的探索,如结合神经符号计算的多工具协作范式。同时,数据集揭示的三大技术挑战——文档结构完整性、检索噪声消除和数值计算精度,也推动了GraphRAG、HyperGraphRAG等图结构检索方法的进一步发展,形成了全局RAG技术路线的多元化演进。
以上内容由遇见数据集搜集并总结生成


