CC-OCR
收藏魔搭社区2026-05-17 更新2024-12-07 收录
下载链接:
https://modelscope.cn/datasets/Qwen/CC-OCR
下载链接
链接失效反馈官方服务:
资源简介:
# CC-OCR
This is the Repository for CC-OCR Benchmark.
Dataset and evaluation code for the Paper "CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy".
<p align="center">
🚀 <a href="https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/Benchmarks/CC-OCR">GitHub</a>   |   🤗 <a href="https://huggingface.co/datasets/wulipc/CC-OCR">Hugging Face</a>   |   🤖 <a href="https://www.modelscope.cn/datasets/Qwen/CC-OCR">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2412.02210">Paper</a>    |   📗 <a href="https://zhibogogo.github.io/ccocr.github.io">Blog</a>
</p>
> Here is hosting the `tsv` version of CC-OCR data, which is used for evaluation in [VLMEvalKit](https://github.com/open-compass/VLMEvalKit). Please refer to our GitHub for more information.
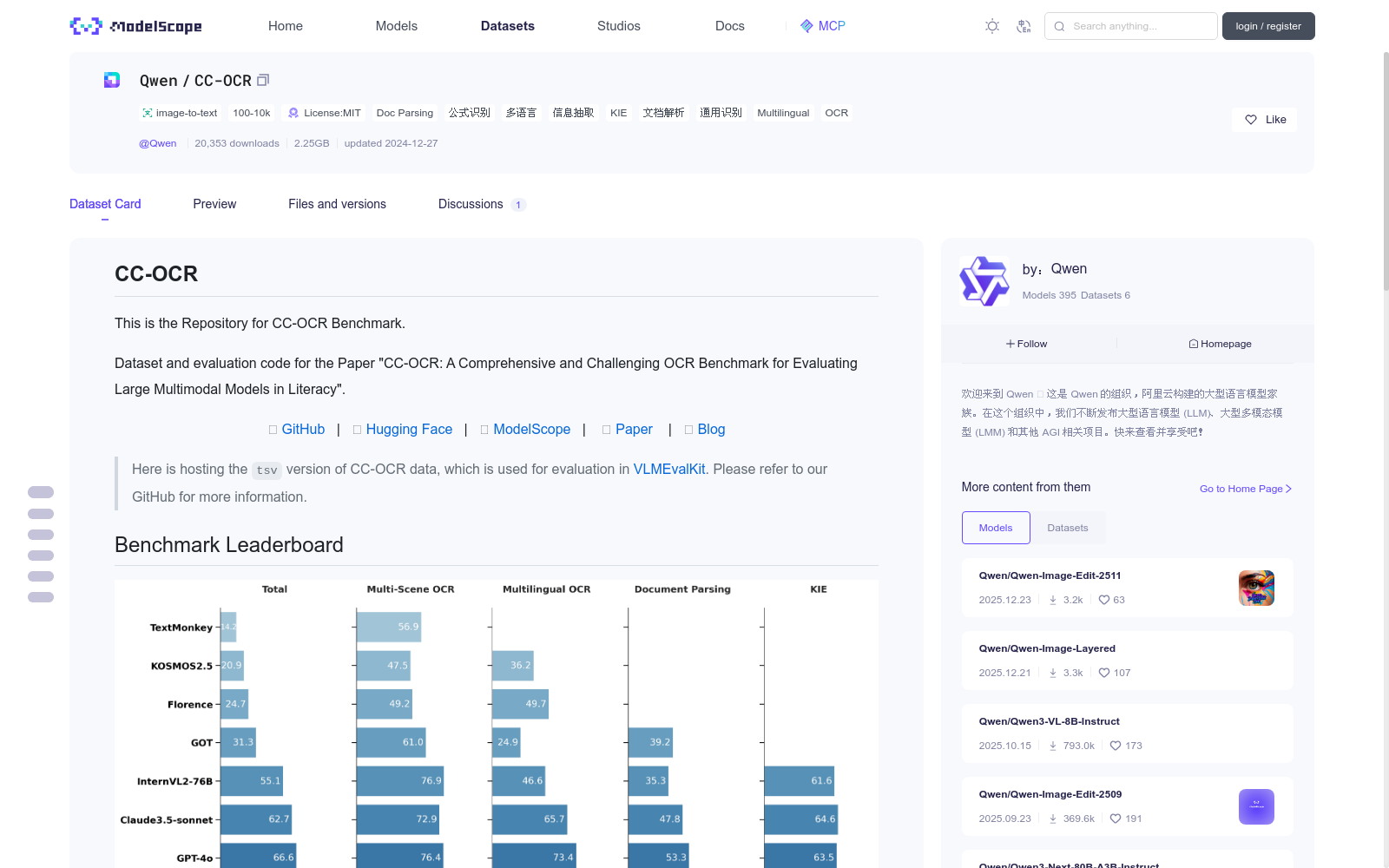
## Benchmark Leaderboard

| Model | Multi-Scene Text Reading | Multilingual Text Reading | Document Parsing | Visual Information Extraction | Total |
|------------------| --------------- | ------------- | ----------- | ----- |-------|
| Gemini-1.5-pro | 83.25 | 78.97 | 62.37 | 67.28 | 72.97 |
| Qwen-VL-72B | 77.95 | 71.14 | 53.78 | 71.76 | 68.66 |
| GPT-4o | 76.40 | 73.44 | 53.30 | 63.45 | 66.65 |
| Claude3.5-sonnet | 72.87 | 65.68 | 47.79 | 64.58 | 62.73 |
| InternVL2-76B | 76.92 | 46.57 | 35.33 | 61.60 | 55.11 |
| GOT | 61.00 | 24.95 | 39.18 | 0.00 | 31.28 |
| Florence | 49.24 | 49.70 | 0.00 | 0.00 | 24.74 |
| KOSMOS2.5 | 47.55 | 36.23 | 0.00 | 0.00 | 20.95 |
| TextMonkey | 56.88 | 0.00 | 0.00 | 0.00 | 14.22 |
* The versions of APIs are GPT-4o-2024-08-06, Gemini-1.5-Pro-002, Claude-3.5-Sonnet-20241022, and Qwen-VL-Max-2024-08-09;
* We conducted the all test around November 20th, 2024, please refer to our paper for more information.
## Benchmark Introduction

The CC-OCR benchmark is specifically designed for evaluating the OCR-centric capabilities of Large Multimodal Models. CC-OCR possesses a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time.
The main features of our CC-OCR include:
* We focus on four OCR-centric tasks, namely `Multi-Scene Text Reading`, `Multilingual Text Reading`, `Document Parsing`, `Visual Information Extraction`;
* The CC-OCR covers fine-grained visual challenges (i.e., orientation-sensitivity, natural noise, and artistic text), decoding of various expressions, and structured inputs and outputs;
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{yang2024ccocr,
title={CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy},
author={Zhibo Yang and Jun Tang and Zhaohai Li and Pengfei Wang and Jianqiang Wan and Humen Zhong and Xuejing Liu and Mingkun Yang and Peng Wang and Shuai Bai and LianWen Jin and Junyang Lin},
year={2024},
eprint={2412.02210},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.02210},
}
```
## License Agreement
The source code is licensed under the [MIT License](./LICENSE) that can be found at the root directory.
## Contact Us
If you have any questions, feel free to send an email to: wpf272043@alibaba-inc.com or xixing.tj@alibaba-inc.com.
# CC-OCR基准数据集
本仓库为CC-OCR基准数据集(CC-OCR Benchmark)的官方代码库,配套论文为《CC-OCR:面向通用人工智能素养评估的综合性高难度光学字符识别基准数据集》(CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy)。
<p align="center">
🚀 <a href="https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/Benchmarks/CC-OCR">GitHub</a>   |   🤗 <a href="https://huggingface.co/datasets/wulipc/CC-OCR">Hugging Face</a>   |   🤖 <a href="https://www.modelscope.cn/datasets/Qwen/CC-OCR">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2412.02210">论文</a>    |   📗 <a href="https://zhibogogo.github.io/ccocr.github.io">官方博客</a>
</p>
> 本仓库托管CC-OCR数据集的制表符分隔值(Tab-Separated Values,TSV)版本,该版本可用于[VLMEvalKit](https://github.com/open-compass/VLMEvalKit)中的评估任务,更多信息请参阅我们的GitHub仓库。
## 基准数据集排行榜

| 模型 | 多场景文本读取 | 多语言文本读取 | 文档解析 | 视觉信息抽取 | 总分 |
|------------------| --------------- | ------------- | ----------- | ----- |-------|
| Gemini-1.5-pro | 83.25 | 78.97 | 62.37 | 67.28 | 72.97 |
| Qwen-VL-72B | 77.95 | 71.14 | 53.78 | 71.76 | 68.66 |
| GPT-4o | 76.40 | 73.44 | 53.30 | 63.45 | 66.65 |
| Claude3.5-sonnet | 72.87 | 65.68 | 47.79 | 64.58 | 62.73 |
| InternVL2-76B | 76.92 | 46.57 | 35.33 | 61.60 | 55.11 |
| GOT | 61.00 | 24.95 | 39.18 | 0.00 | 31.28 |
| Florence | 49.24 | 49.70 | 0.00 | 0.00 | 24.74 |
| KOSMOS2.5 | 47.55 | 36.23 | 0.00 | 0.00 | 20.95 |
| TextMonkey | 56.88 | 0.00 | 0.00 | 0.00 | 14.22 |
* 本次测试所使用的API版本分别为:GPT-4o-2024-08-06、Gemini-1.5-Pro-002、Claude-3.5-Sonnet-20241022以及Qwen-VL-Max-2024-08-09;
* 所有测试均于2024年11月20日前后完成,更多细节请参阅我们的论文。
## 基准数据集介绍

CC-OCR基准数据集专为评估多模态大模型(Large Multimodal Models)的以光学字符识别(Optical Character Recognition,OCR)为核心的能力而打造,涵盖了丰富多样的应用场景、任务类型与挑战难点。CC-OCR包含四大以OCR为核心的任务赛道:多场景文本读取、多语言文本读取、文档解析以及关键信息抽取,共计39个子集,包含7058张全标注图像,其中41%的数据来自真实应用场景,且为首次公开发布。
CC-OCR的核心特性如下:
* 聚焦四大以OCR为核心的任务:多场景文本读取、多语言文本读取、文档解析以及视觉信息抽取;
* CC-OCR涵盖了细粒度视觉挑战(如方向敏感性、自然噪声与艺术字体)、多样化文本表达方式解码以及结构化输入输出能力的评估。
## 引用声明
若您的研究工作得益于本数据集,请引用我们的论文:
@misc{yang2024ccocr,
title={CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy},
author={Zhibo Yang and Jun Tang and Zhaohai Li and Pengfei Wang and Jianqiang Wan and Humen Zhong and Xuejing Liu and Mingkun Yang and Peng Wang and Shuai Bai and LianWen Jin and Junyang Lin},
year={2024},
eprint={2412.02210},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.02210},
}
## 许可协议
本仓库的源代码遵循根目录下的[MIT许可协议](./LICENSE)进行分发。
## 联系我们
若您有任何疑问,可通过以下邮箱联系我们:wpf272043@alibaba-inc.com 或 xixing.tj@alibaba-inc.com。
提供机构:
maas
创建时间:
2024-11-29
搜集汇总
数据集介绍
背景与挑战
背景概述
CC-OCR是一个专门用于评估大型多模态模型OCR能力的综合性基准测试数据集,涵盖多场景文本阅读、多语言文本阅读、文档解析和视觉信息抽取四个核心任务。该数据集包含39个子集和7,058张全标注图像,其中41%的图像来自真实应用场景,首次公开释放,旨在提供多样化的挑战以测试模型在文字识别方面的性能。
以上内容由遇见数据集搜集并总结生成


