strombergnlp/nlpcc-stance
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/strombergnlp/nlpcc-stance
下载链接
链接失效反馈官方服务:
资源简介:
这是一个中文立场预测数据集,专门用于检测中文微博中的立场。数据集源自NLPCC-ICCPOL 2016的一个共享任务,旨在通过给定的标记数据检测对五个兴趣目标的立场。数据集中的每个实例包括一个唯一ID、目标、文本和立场标签,其中立场标签分为反对、支持或无立场。数据集由中国的学生进行标注,确保了标注的一致性和可靠性。该数据集仅包含中文数据,并根据CC-BY-4.0许可发布。
This is a Chinese stance prediction dataset dedicated to detecting stances in Chinese microblogs. The dataset originates from a shared task at NLPCC-ICCPOL 2016, which aims to detect stances towards five topics of interest using given labeled data. Each instance in the dataset includes a unique ID, target topic, text, and stance label, where the stance labels are categorized into oppose, support, or no stance. The dataset was annotated by student annotators from China, ensuring the consistency and reliability of the annotations. This dataset only contains Chinese-language data and is released under the CC-BY-4.0 license.
提供机构:
strombergnlp
原始信息汇总
数据集概述
数据集基本信息
- 名称: NLPCC 2016: Stance Detection in Chinese Microblogs
- 语言: 中文 (
bcp47:zh) - 许可证: Creative Commons Attribution 4.0 (CC-BY-4.0)
- 多语言性: 单语种
- 数据集大小: 1K<n<10K
- 数据来源: 原创数据
- 任务类别: 文本分类
- 任务ID: 情感分析
- 标签: 立场检测
数据集描述
- 概述: 这是一个关于中文立场预测的数据集。数据来源于NLPCC-ICCPOL 2016的一个共享任务,即中文微博中的立场检测。该任务是强制性的监督任务,旨在检测对五个兴趣目标的立场。
- 支持的任务: 中文微博中的立场检测
数据集结构
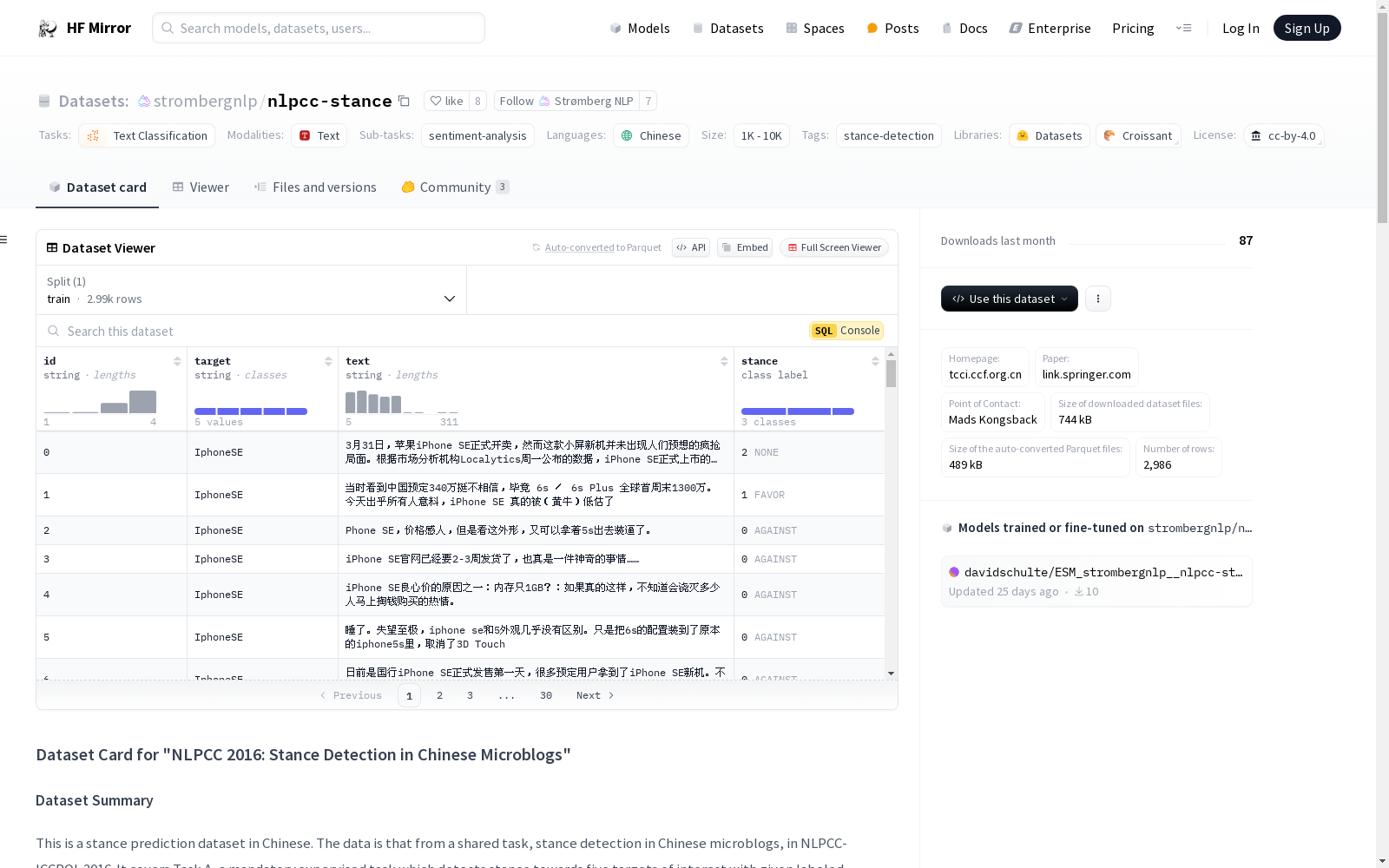
- 数据实例: 每个实例包含四个字段:id(唯一标识符)、target(立场目标)、text(包含立场的文本)、stance(立场类别,0表示反对,1表示支持,2表示无立场)。
- 数据字段:
- id: 字符串,实例的唯一标识
- target: 字符串,立场的目标
- text: 字符串,包含立场的文本
- stance: 整数,立场类别(0: AGAINST, 1: FAVOR, 2: NONE)
- 数据分割: 训练集包含2986个实例
数据集创建
- 采集理由: 目的是创建一个针对微博文本的立场标注数据集。选择了六个立场目标,并从新浪微博收集数据进行标注。
- 源数据:
- 语言生产者: 新浪微博用户
- 标注:
- 标注过程: 每个目标-微博对由两名学生独立标注。如果两人标注一致,则确定立场;否则由第三名学生进行标注,并通过投票确定最终标签。
- 标注者: 中国学生
使用数据时的考虑
- 社会影响: 数据保留了社交媒体言论的原貌,可能涉及隐私问题。
- 偏见讨论: 数据存在时间、地域和主题的偏见。
其他信息
-
数据集管理员: 论文作者
-
许可证信息: 数据集根据CC-BY 4.0许可证分发
-
引用信息:
@incollection{xu2016overview, title={Overview of nlpcc shared task 4: Stance detection in chinese microblogs}, author={Xu, Ruifeng and Zhou, Yu and Wu, Dongyin and Gui, Lin and Du, Jiachen and Xue, Yun}, booktitle={Natural language understanding and intelligent applications}, pages={907--916}, year={2016}, publisher={Springer} }
搜集汇总
数据集介绍
构建方式
该数据集构建于NLPCC-ICCPOL 2016共享任务的基础上,专注于中文微博中的立场检测。数据来源于新浪微博,针对六个特定目标进行立场标注。标注过程由两名学生独立完成,若标注结果不一致,则由第三名学生进行仲裁,最终通过投票确定标签。
特点
该数据集包含2986个训练实例,每个实例包括微博文本、目标主题及立场标签。立场标签分为三类:反对(AGAINST)、支持(FAVOR)和无立场(NONE)。数据集专注于中文微博语境,反映了社交媒体用户在特定话题上的立场表达。
使用方法
该数据集适用于中文立场检测任务,尤其适合用于训练和评估立场分类模型。用户可通过加载数据集,提取文本和目标主题,结合立场标签进行模型训练。数据集的使用需遵循CC-BY 4.0许可,确保在引用时注明原始来源。
背景与挑战
背景概述
NLPCC Stance数据集由NLPCC-ICCPOL 2016会议中的共享任务创建,专注于中文微博中的立场检测。该数据集由专家生成,主要研究人员包括Xu Ruifeng等人,旨在通过标注数据检测用户对五个特定目标的立场。数据集涵盖了从新浪微博收集的文本,经过双重标注以确保标签的准确性。该数据集在自然语言处理领域具有重要影响力,特别是在中文社交媒体文本分析方面,为立场检测任务提供了宝贵的资源。
当前挑战
NLPCC Stance数据集面临的挑战主要包括两个方面。首先,立场检测任务本身具有复杂性,尤其是在中文语境下,文本的语义表达多样且隐含,导致立场分类的难度增加。其次,数据集的构建过程中,标注的一致性是一个关键问题。尽管采用了双重标注和第三方仲裁的机制,但不同标注者之间的主观差异仍可能导致标签的不一致性。此外,数据集仅涵盖六个话题,可能存在话题覆盖不足的问题,限制了模型的泛化能力。
常用场景
经典使用场景
在社交媒体分析领域,strombergnlp/nlpcc-stance数据集被广泛应用于中文微博的立场检测研究。该数据集通过提供标注的微博文本,帮助研究者训练和测试立场检测模型,从而识别用户对特定话题的支持、反对或中立态度。这一过程不仅涉及自然语言处理技术,还深入探讨了社交媒体中的用户行为和心理。
衍生相关工作
基于strombergnlp/nlpcc-stance数据集,研究者们已经开发了多种立场检测算法和模型。这些工作不仅提升了立场检测的准确性和效率,还促进了跨语言立场检测技术的发展。此外,该数据集还激发了关于社交媒体数据伦理和隐私保护的研究,推动了相关领域的技术进步和政策制定。
数据集最近研究
最新研究方向
在社交媒体分析领域,立场检测(Stance Detection)已成为自然语言处理(NLP)研究的热点之一。NLPCC Stance数据集作为中文微博立场检测的基准数据集,近年来在立场检测模型的训练与评估中发挥了关键作用。随着深度学习技术的进步,研究者们开始探索基于预训练语言模型(如BERT、RoBERTa)的立场检测方法,以提高模型在复杂语境下的表现。此外,跨领域立场检测和零样本学习也成为研究的前沿方向,旨在提升模型在未见过的主题或语言环境中的泛化能力。该数据集的应用不仅推动了中文社交媒体分析技术的发展,还为理解公众舆论和情感倾向提供了重要工具。
以上内容由遇见数据集搜集并总结生成


