Facebook Social Graph Dataset
收藏snap.stanford.edu2024-10-29 收录
下载链接:
http://snap.stanford.edu/data/ego-Facebook.html
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了Facebook用户之间的社交关系图,包括用户ID和用户之间的连接关系。数据集用于研究社交网络的结构和动态。
This dataset contains the social graph among Facebook users, including user IDs and the connection relationships between users. It is utilized for research on the structure and dynamics of social networks.
提供机构:
snap.stanford.edu
搜集汇总
数据集介绍
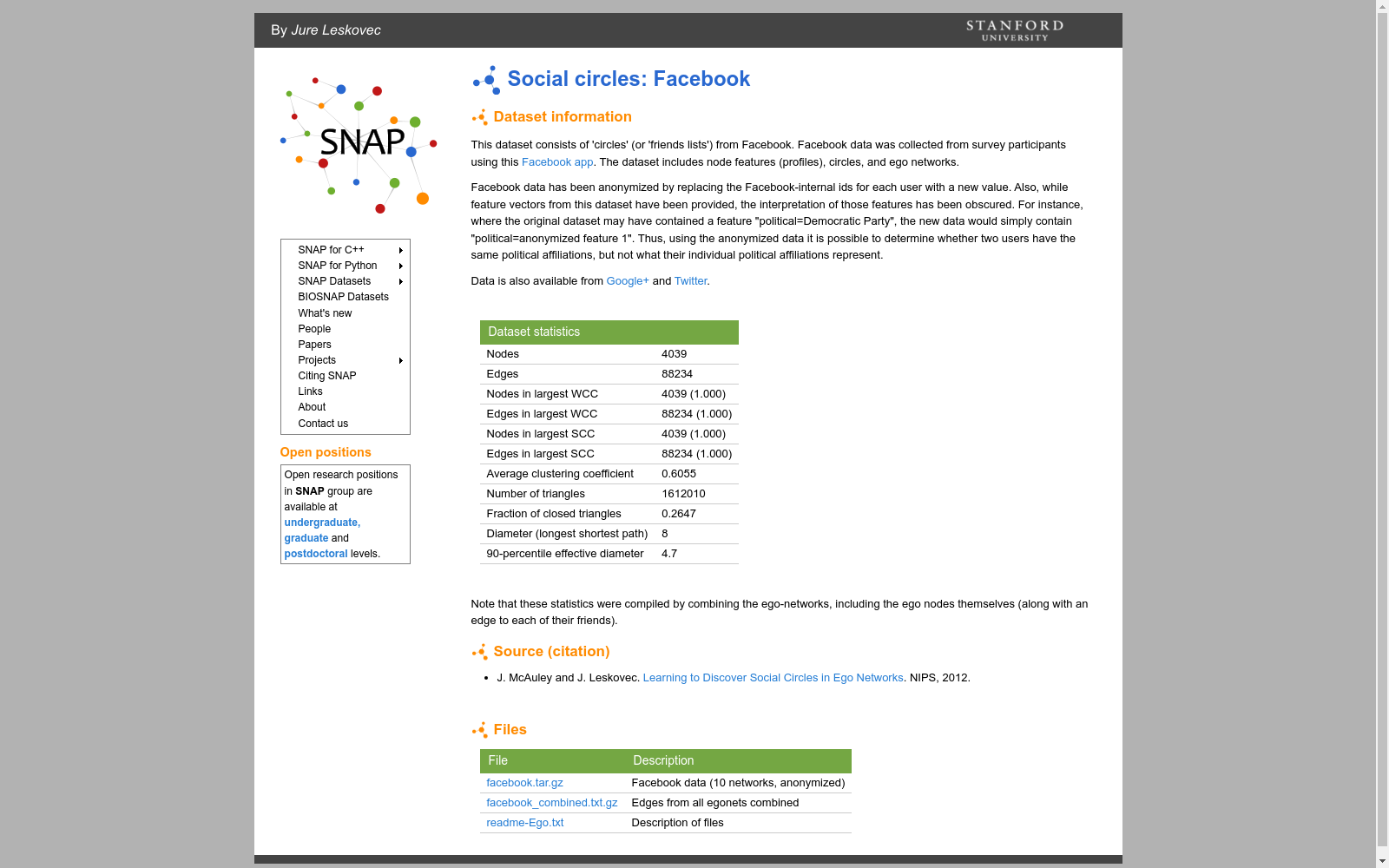
构建方式
Facebook社交图谱数据集的构建基于Facebook平台上的用户互动数据,通过收集用户之间的连接关系、点赞、评论等社交行为,构建了一个庞大的社交网络图。数据集的构建过程中,采用了匿名化处理技术,确保用户隐私得到保护。此外,数据集还包含了用户的基本信息和社交行为的时间戳,以便进行更深入的分析和研究。
特点
该数据集的主要特点在于其规模庞大且结构复杂,涵盖了数百万用户的社交关系和互动行为。数据集中的社交图谱不仅展示了用户之间的直接连接,还揭示了复杂的社交网络结构,如社区、群组等。此外,数据集的时间戳信息为研究社交行为的动态变化提供了可能,使得分析社交网络的演化成为可能。
使用方法
Facebook社交图谱数据集可用于多种研究领域,如社交网络分析、用户行为预测、信息传播模型等。研究者可以通过分析用户之间的连接关系,识别社交网络中的关键节点和社区结构。此外,结合时间戳信息,可以研究社交行为的动态变化,预测未来的社交趋势。数据集的使用需要遵循相关的隐私保护法规,确保用户数据的安全和合法使用。
背景与挑战
背景概述
社交网络分析领域,Facebook社交图谱数据集的诞生标志着对大规模社交关系研究的重大突破。该数据集由Facebook公司于2010年发布,旨在提供一个详尽的社交网络结构视图,以支持学术界和工业界对社交网络行为、信息传播和用户互动模式的深入研究。通过公开部分匿名化的用户数据,该数据集极大地促进了社交网络算法的发展,尤其是在社区检测、影响力传播和推荐系统等领域。Facebook社交图谱数据集的发布,不仅为研究者提供了丰富的实验数据,也推动了社交网络分析技术的快速进步。
当前挑战
尽管Facebook社交图谱数据集为社交网络研究提供了宝贵的资源,但其构建和应用过程中仍面临诸多挑战。首先,数据隐私和安全问题是该数据集面临的主要挑战之一,如何在保护用户隐私的前提下提供有价值的研究数据,一直是学术界和工业界关注的焦点。其次,数据集的规模庞大,如何高效地处理和分析这些数据,以提取有意义的信息,是研究者需要克服的技术难题。此外,社交网络的动态性和复杂性,使得数据集的更新和维护成为一个持续的挑战,确保数据的时效性和准确性对于研究结果的可靠性至关重要。
发展历史
创建时间与更新
Facebook Social Graph Dataset的创建时间可以追溯到2004年,即Facebook平台成立之初。随着Facebook用户数量的快速增长,该数据集也在不断更新,以反映社交网络的动态变化。
重要里程碑
2007年,Facebook推出了开放图谱API,使得研究人员和开发者能够访问和分析社交图谱数据,这一举措极大地推动了社交网络分析领域的发展。2010年,Facebook发布了Graph API 1.0,进一步简化了数据访问流程,促进了学术研究和商业应用的广泛使用。2018年,Facebook对其数据政策进行了重大调整,加强了数据隐私保护措施,这一变化对数据集的使用和研究产生了深远影响。
当前发展情况
当前,Facebook Social Graph Dataset已成为社交网络分析和机器学习领域的重要资源。它不仅为学术研究提供了丰富的数据支持,还推动了社交网络算法和模型的创新。随着数据隐私和伦理问题的日益凸显,Facebook也在不断优化其数据管理和共享策略,以确保数据使用的合规性和透明度。该数据集的持续发展,对于理解人类社交行为和推动相关技术进步具有重要意义。
发展历程
- Facebook首次公开发布其社交图谱数据集,作为研究社交网络分析和数据挖掘的资源。
- Facebook对其社交图谱数据集进行了更新,增加了更多的用户数据和互动信息,以支持更深入的研究。
- Facebook社交图谱数据集被广泛应用于多个学术研究项目中,特别是在社交网络分析、推荐系统和用户行为预测等领域。
- Facebook对其数据集进行了进一步的扩展,引入了更多的社交互动数据,包括点赞、评论和分享等,以增强数据集的多样性和实用性。
- Facebook社交图谱数据集被用于多个国际会议和研讨会,成为社交网络分析领域的重要参考数据集。
- Facebook对其社交图谱数据集进行了隐私保护的更新,以符合新的数据保护法规,同时继续支持学术研究和创新应用。
常用场景
经典使用场景
在社交网络分析领域,Facebook Social Graph Dataset 被广泛用于研究用户之间的社交关系和互动模式。该数据集包含了数百万用户的社交连接信息,为研究者提供了丰富的数据资源,以探索社交网络的结构特性、信息传播路径以及用户行为模式。通过分析这些数据,研究者能够揭示社交网络中的社区结构、影响力传播机制以及用户间的互动规律,从而为社交网络的优化和个性化推荐提供理论支持。
实际应用
在实际应用中,Facebook Social Graph Dataset 被用于开发和优化多种社交网络服务。例如,通过分析用户间的社交连接和互动数据,企业可以实现更精准的广告投放和营销策略,提升广告效果和用户参与度。同时,该数据集也为社交推荐系统的开发提供了数据支持,帮助平台为用户推荐更符合其兴趣和需求的内容和好友。此外,通过对社交网络结构的分析,平台可以优化信息传播路径,提升信息的传播效率和覆盖范围,从而增强用户的社交体验。
衍生相关工作
基于 Facebook Social Graph Dataset,研究者们开展了一系列经典工作。例如,通过分析社交网络的结构特性,研究者提出了多种社区检测算法,用于识别网络中的社区结构和关键节点。此外,该数据集还被用于开发和验证多种信息传播模型,揭示了社交网络中信息扩散的动态过程和影响因素。在用户行为研究方面,基于该数据集的研究工作推动了个性化推荐系统和用户行为预测模型的发展,为社交网络的个性化服务提供了理论和技术支持。这些衍生工作不仅丰富了社交网络分析的理论体系,也为实际应用提供了有力支撑。
以上内容由遇见数据集搜集并总结生成


