danbooru-wiki-2024
收藏Hugging Face2024-07-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/isek-ai/danbooru-wiki-2024
下载链接
链接失效反馈官方服务:
资源简介:
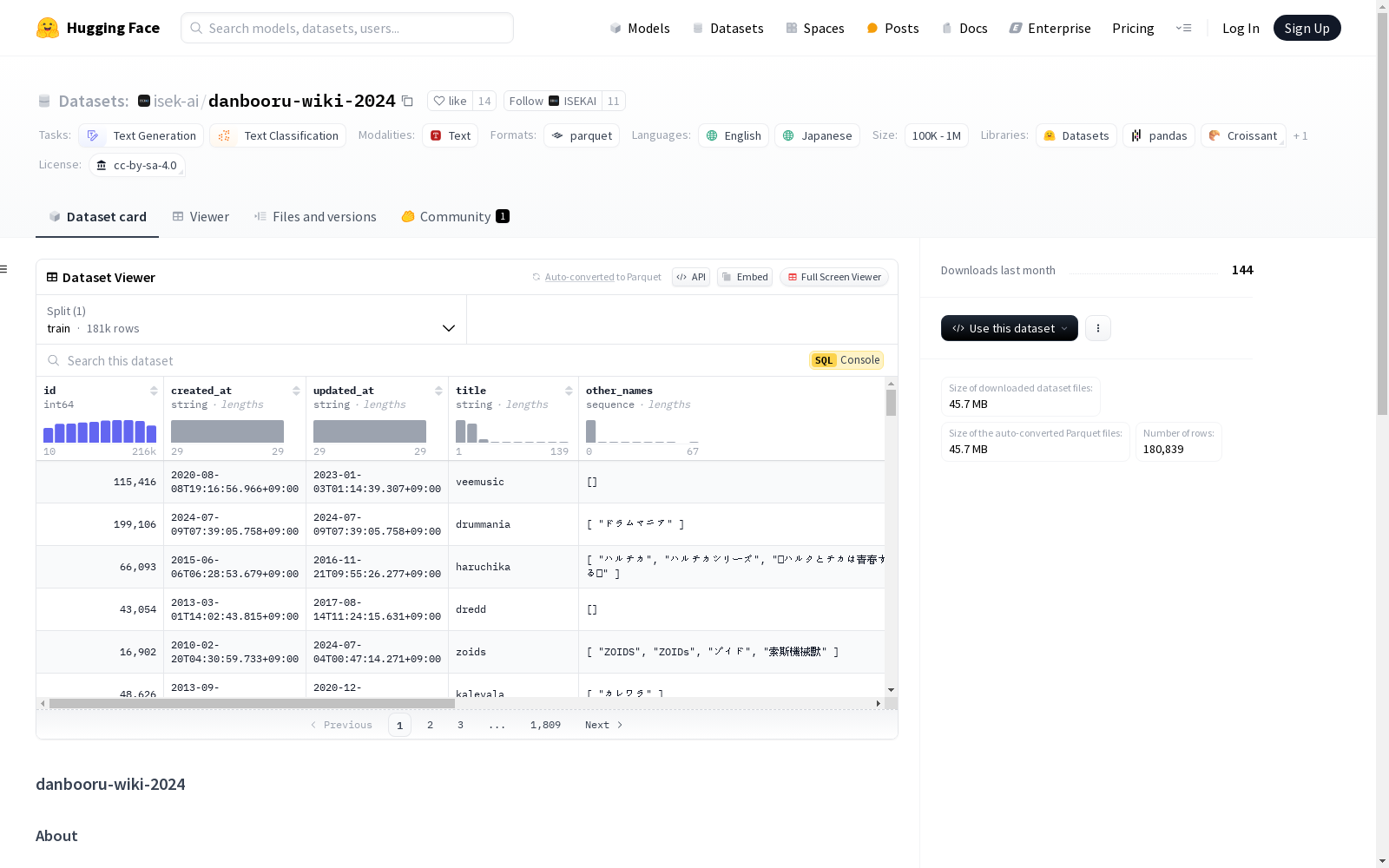
数据集包含关于danbooru标签的维基页面,这些标签来自danbooru.donmai.us网站。维基页面提供了每个标签的描述以及与pixiv标签的匹配信息。数据集首先从isek-ai/danbooru-tags-2024数据集中筛选出来,然后使用danbooru API收集维基数据。筛选规则是移除使用次数少于100次的标签。数据集的时间范围是2005年至2024年6月30日。数据集包含多种特征,如类型、ID、创建时间、更新时间、标题、正文、是否锁定、其他名称、是否删除等。数据集分为训练集,包含33658个样本。
This dataset contains Wikipedia-style pages for Danbooru tags sourced from the danbooru.donmai.us website. These pages provide descriptions for each tag and their matching information with Pixiv tags. The dataset was first filtered from the isek-ai/danbooru-tags-2024 dataset, then Wikipedia-style data was collected via the Danbooru API. The filtering rule is to remove tags with fewer than 100 usage counts. The time range of the dataset spans from 2005 to June 30, 2024. The dataset includes multiple features such as type, ID, creation time, update time, title, body content, lock status, alternative names, deletion status, and more. The dataset is split into a training set containing 33,658 samples.
创建时间:
2024-07-07
原始信息汇总
danbooru-wiki-2024 数据集概述
基本信息
- 语言: 英语 (en), 日语 (ja)
- 许可: CC BY-SA 4.0
- 数据规模: 10K < n < 100K
- 任务类别: 文本生成, 文本分类
数据集结构
特征
- type: 字符串
- id: 整数 (int64)
- created_at: 字符串
- updated_at: 字符串
- title: 字符串
- body: 字符串
- is_locked: 布尔值
- other_names: 字符串序列
- is_deleted: 布尔值
数据分割
- train:
- 字节数: 20762870
- 样本数: 33658
数据大小
- 下载大小: 11782355
- 数据集大小: 20762870
配置
- config_name: default
- 数据文件:
- split: train
- path: data/train-*
- 数据文件:
数据集来源
- 数据集最初从 isek-ai/danbooru-tags-2024 过滤得到,然后使用 danbooru API 收集维基数据。
数据过滤规则
- 移除使用次数少于 100 次的标签。
数据范围
- 基于 isek-ai/danbooru-tags-2024,数据范围为 2005 年至 2024/06/30。
最后更新
- 2024/07/07
搜集汇总
数据集介绍
构建方式
danbooru-wiki-2024数据集基于isek-ai/danbooru-tags-2024数据集进行筛选,并通过Danbooru API收集了与标签相关的维基页面数据。筛选规则包括移除使用次数少于100次的标签,确保数据的高频使用性。数据的时间范围从2005年延伸至2024年8月31日,涵盖了Danbooru平台上近二十年的标签使用历史。
特点
该数据集包含丰富的标签描述信息,涵盖了每个标签的创建时间、更新记录、标题、别名、正文内容、锁定状态、删除状态、分类及标签类别等特征。数据集以多语言(英语和日语)呈现,适用于文本生成和文本分类任务。其规模适中,包含超过18万条数据,适合用于训练和验证模型。
使用方法
用户可通过Hugging Face的`datasets`库加载danbooru-wiki-2024数据集,指定`split`参数为`train`以获取训练数据。为确保数据一致性,建议指定修订版本号(revision)。数据集会不定期更新,用户可通过指定修订版本来锁定特定版本的数据。加载后,数据可直接用于文本生成或分类任务的模型训练与评估。
背景与挑战
背景概述
danbooru-wiki-2024数据集由isek-ai团队于2024年创建,主要基于Danbooru社区的标签系统构建。Danbooru是一个以动漫图像为主的在线图库,其标签系统广泛应用于图像分类与标注领域。该数据集的核心研究问题在于通过整合Danbooru标签及其对应的维基页面描述,为文本生成与分类任务提供高质量的多语言语料。数据集涵盖了2005年至2024年8月31日期间的标签数据,并通过API从Danbooru维基页面中提取相关信息。其多语言特性(英语与日语)及丰富的标签描述,为动漫图像标注、跨语言文本生成等研究提供了重要支持。
当前挑战
danbooru-wiki-2024数据集在解决动漫图像标注与文本生成问题时面临多重挑战。首先,标签的多样性与复杂性使得文本分类任务需要处理大量细粒度类别,这对模型的泛化能力提出了较高要求。其次,数据集的多语言特性(英语与日语)增加了跨语言文本对齐与语义理解的难度。在构建过程中,数据过滤与清洗也面临挑战,例如如何有效去除低频标签以提升数据质量,同时确保重要信息不被遗漏。此外,由于Danbooru社区数据的动态更新,数据集需要定期维护以保持时效性,这对数据集的长期可用性提出了更高要求。
常用场景
经典使用场景
danbooru-wiki-2024数据集广泛应用于图像标签生成与分类任务中,尤其是在动漫和二次元文化领域。研究者通过该数据集中的标签描述和分类信息,能够训练出高效的文本生成模型,用于自动生成与图像内容相匹配的标签。此外,该数据集还常用于多语言文本处理研究,尤其是英语和日语之间的跨语言文本分析。
衍生相关工作
基于danbooru-wiki-2024数据集,研究者开发了多种图像标签生成与分类模型,如基于Transformer的文本生成模型和跨语言文本分类模型。这些模型在动漫图像标签生成和分类任务中表现出色,推动了相关领域的研究进展。此外,该数据集还催生了一系列跨语言文本处理工具,为多语言自然语言处理研究提供了新的思路。
数据集最近研究
最新研究方向
在动漫图像标注与分类领域,danbooru-wiki-2024数据集的最新研究方向聚焦于多模态学习与标签语义理解的深度融合。随着深度学习技术的进步,研究者们正致力于利用该数据集中的丰富标签信息,结合图像与文本的多模态特征,提升图像分类与生成的精度。特别是在生成式模型的应用中,该数据集为模型提供了高质量的语义标签,推动了基于文本描述的图像生成技术的发展。此外,该数据集还被广泛应用于跨语言标签匹配研究,尤其是在日语与英语之间的标签映射与语义对齐方面,为多语言图像标注系统的开发提供了重要支持。这些研究不仅推动了动漫图像处理技术的进步,也为相关领域的商业化应用奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


