自定义生成的时序数据对
收藏arXiv2025-03-27 更新2025-04-01 收录
下载链接:
http://arxiv.org/abs/2503.21378v1
下载链接
链接失效反馈官方服务:
资源简介:
本研究构建了一个自定义的数据集,用于训练和评估基于自然语言查询的时间序列数据检索模型。数据集由100,000对参考和目标时间序列数据组成,这些数据对是根据六个预定义的差异特征(上升/下降趋势、峰值、缺失值、噪声、基线)合成的。每对数据都伴有相应的查询文本,这些文本描述了数据之间的差异。数据集用于训练一个对比学习模型,该模型能够根据自然语言查询检索具有特定差异的时间序列数据对。
This study constructs a custom dataset for training and evaluating natural language query-based time series data retrieval models. The dataset comprises 100,000 pairs of reference and target time series data, which are synthesized based on six predefined differential features: upward/downward trends, peaks, missing values, noise, and baselines. Each pair is accompanied by corresponding query texts that describe the differences between the two time series. This dataset is utilized to train a contrastive learning model capable of retrieving time series data pairs with specific differences via natural language queries.
提供机构:
日本 Hitachi, Ltd.
创建时间:
2025-03-27
搜集汇总
数据集介绍
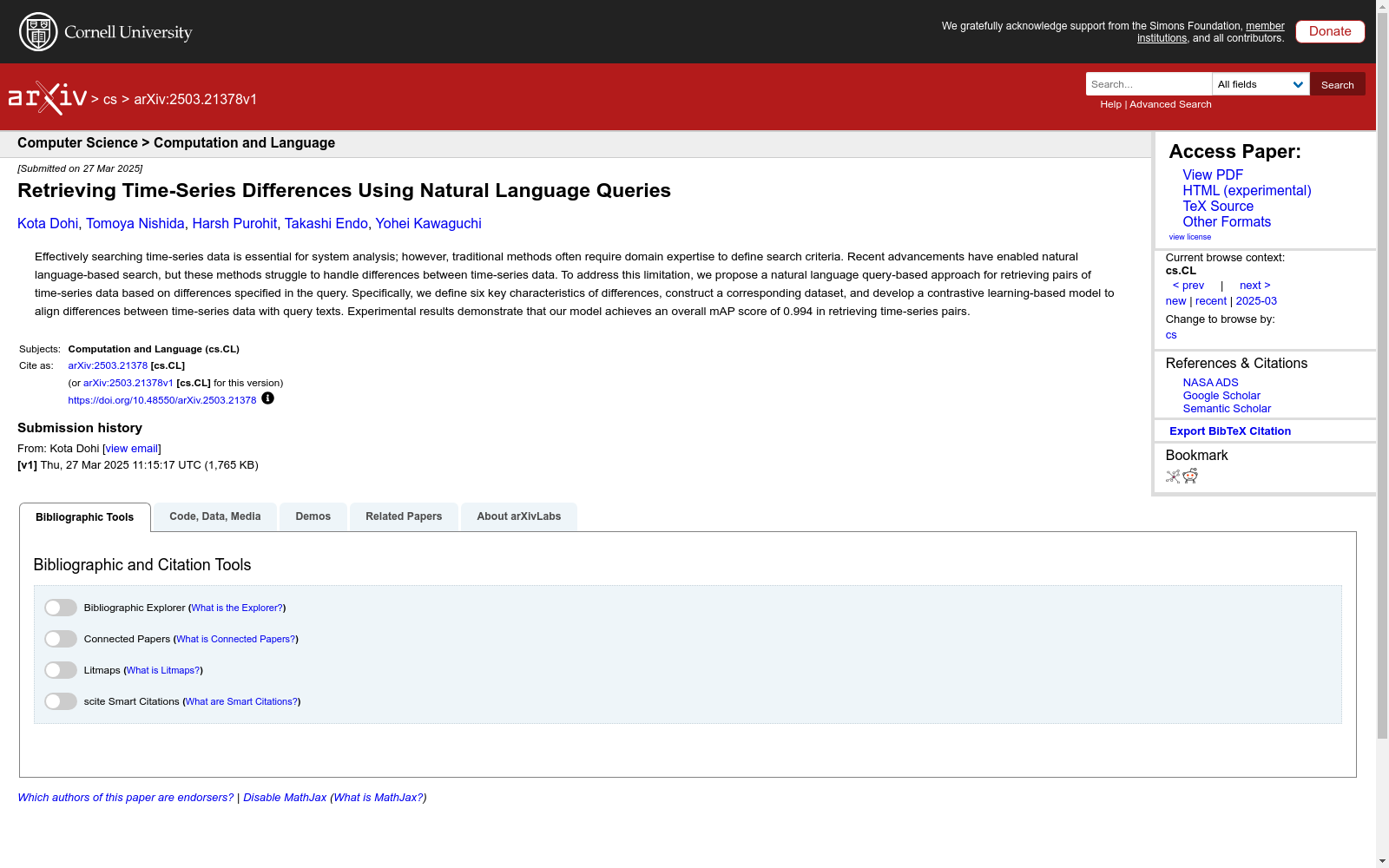
构建方式
在时序数据分析领域,有效捕捉数据间差异是系统监测的核心需求。本研究采用合成数据生成策略,基于真实传感器数据(TACO数据集)构建了包含10万组时序对的基准数据集。通过定义上升趋势、下降趋势、尖峰、跌落、噪声和基线偏移六种关键差异特征,对原始数据进行归一化处理后,采用参数化扰动方法生成具有层级差异的参考-目标数据对。针对每种差异特征,使用GPT-4o模型对模板化查询文本进行语义重构,最终形成具有12种标注关系的多模态数据集,其中训练集、验证集和测试集的比例为100:2:0.4。
特点
该数据集创新性地实现了时序差异特征与自然语言描述的精准对齐,其核心优势体现在三维度特性:多模态架构同步包含原始时序信号和语义查询文本;差异化标注体系通过两级扰动参数(α,β,γ,θ)量化表征数据差异强度;语义多样性保障方面,每个差异类别配备1000条经语言模型重构的自然语言描述。实验验证表明,数据集支持模型达到0.994的mAP评分,尤其在Informer编码器与差分融合策略组合下,对尖峰和基线偏移特征的检索准确率可达100%。
使用方法
该数据集适用于对比学习框架下的跨模态检索研究。使用时应将参考-目标时序对分别输入共享权重的信号编码器(推荐Informer架构),通过差分或拼接方式融合特征后,与BART-Large-XSum编码的查询文本在投影空间进行相似度计算。训练阶段采用监督对比损失函数,设置温度参数τ=1.0,对信号编码器和文本编码器分别采用1e-5和1e-4的学习率进行端到端微调。评估时需计算查询文本嵌入与所有时序对嵌入的余弦相似度,按差异类型分类计算mAP指标,特别注意上升/下降趋势等全局特征需结合交叉注意力机制提升建模效果。
背景与挑战
背景概述
自定义生成的时序数据对数据集由日立公司研发团队于2025年提出,旨在解决时序数据分析中基于自然语言查询差异检索的核心问题。传统时序分析方法依赖专家知识定义搜索标准,而现有自然语言查询方法难以捕捉多时序数据间的差异特征。该研究创新性地定义了上升趋势、下降趋势、尖峰、跌落、噪声和基线六种差异特征,通过合成数据生成和对比学习技术,构建了包含10万训练样本的大规模数据集。该成果发表于时间序列分析与多模态学习交叉领域,为工业设备监测、医疗信号处理等需要差异分析的场景提供了标准化基准。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决自然语言描述与复杂时序模式间的语义鸿沟,特别是对非周期性、多尺度差异特征的精确匹配;在构建过程中,合成数据的真实性验证、六类差异特征的边界定义,以及扰动参数(如趋势强度α∈[0,1]、噪声水平γ∈[0.05,0.1])的合理标定构成主要技术难点。实验表明,虽然整体mAP达到0.994,但尖峰检测在跨注意力机制下的性能波动(0.321-0.975)揭示了局部特征与全局依赖的平衡难题。
常用场景
经典使用场景
在时间序列数据分析领域,自定义生成的时序数据对数据集被广泛应用于自然语言查询驱动的差异检索任务。该数据集通过构建具有六种关键差异特征的时序数据对及其对应的自然语言描述,为研究者提供了标准化的评估基准。特别是在工业设备监测、金融趋势分析和医疗信号处理等场景中,该数据集能够有效支持基于语义的时序差异检索模型的训练与验证。
实际应用
在工业物联网场景中,该数据集支持通过自然语言查询快速定位设备异常状态,如'当前振动信号比基线数据噪声更大'等语义检索。金融领域可应用于跨市场行情对比分析,医疗领域则助力于心电图等生理信号的差异诊断。其生成的合成数据对能有效缓解实际场景中标注数据匮乏的问题,大幅降低企业部署智能监测系统的数据准备成本。
衍生相关工作
该数据集催生了时序-文本跨模态对齐的一系列创新研究,如基于Informer架构的差异特征编码器、融合交叉注意力的对比学习框架等。相关衍生工作进一步扩展至多语言查询支持(CLaSP模型)、领域自适应迁移(TACO数据集应用)等方向,形成了完整的时序语义检索技术体系,相关成果已在ICASSP等顶级会议形成持续性的研究脉络。
以上内容由遇见数据集搜集并总结生成


