LHPR-VLN
收藏arXiv2024-12-12 更新2024-12-25 收录
下载链接:
https://hcplab-sysu.github.io/LH-VLN/
下载链接
链接失效反馈官方服务:
资源简介:
LHPR-VLN数据集是由中山大学开发的一个用于长时程视觉语言导航任务的基准数据集。该数据集包含3260个任务,平均每个任务有150个步骤,旨在模拟复杂的多阶段导航任务。数据集通过自动化的数据生成平台NavGen创建,采用双向多粒度生成方法,确保任务的多样性和复杂性。创建过程中,利用GPT-4生成任务指令,并通过Habitat3模拟器生成轨迹数据。LHPR-VLN数据集主要应用于评估和提升机器人在复杂环境中的导航能力,特别是在需要长时间规划和多阶段任务执行的场景中。
The LHPR-VLN dataset is a benchmark dataset developed by Sun Yat-sen University for long-term visual-language navigation tasks. This dataset contains 3,260 tasks, with an average of 150 steps per task, and aims to simulate complex multi-stage navigation tasks. It was created via the automated data generation platform NavGen, adopting a bidirectional multi-granularity generation method to ensure the diversity and complexity of the tasks. During its development, task instructions were generated using GPT-4, and trajectory data was produced via the Habitat3 simulator. The LHPR-VLN dataset is primarily used to evaluate and enhance the navigation capabilities of robots in complex environments, particularly in scenarios requiring long-term planning and multi-stage task execution.
提供机构:
中山大学
创建时间:
2024-12-12
搜集汇总
数据集介绍
构建方式
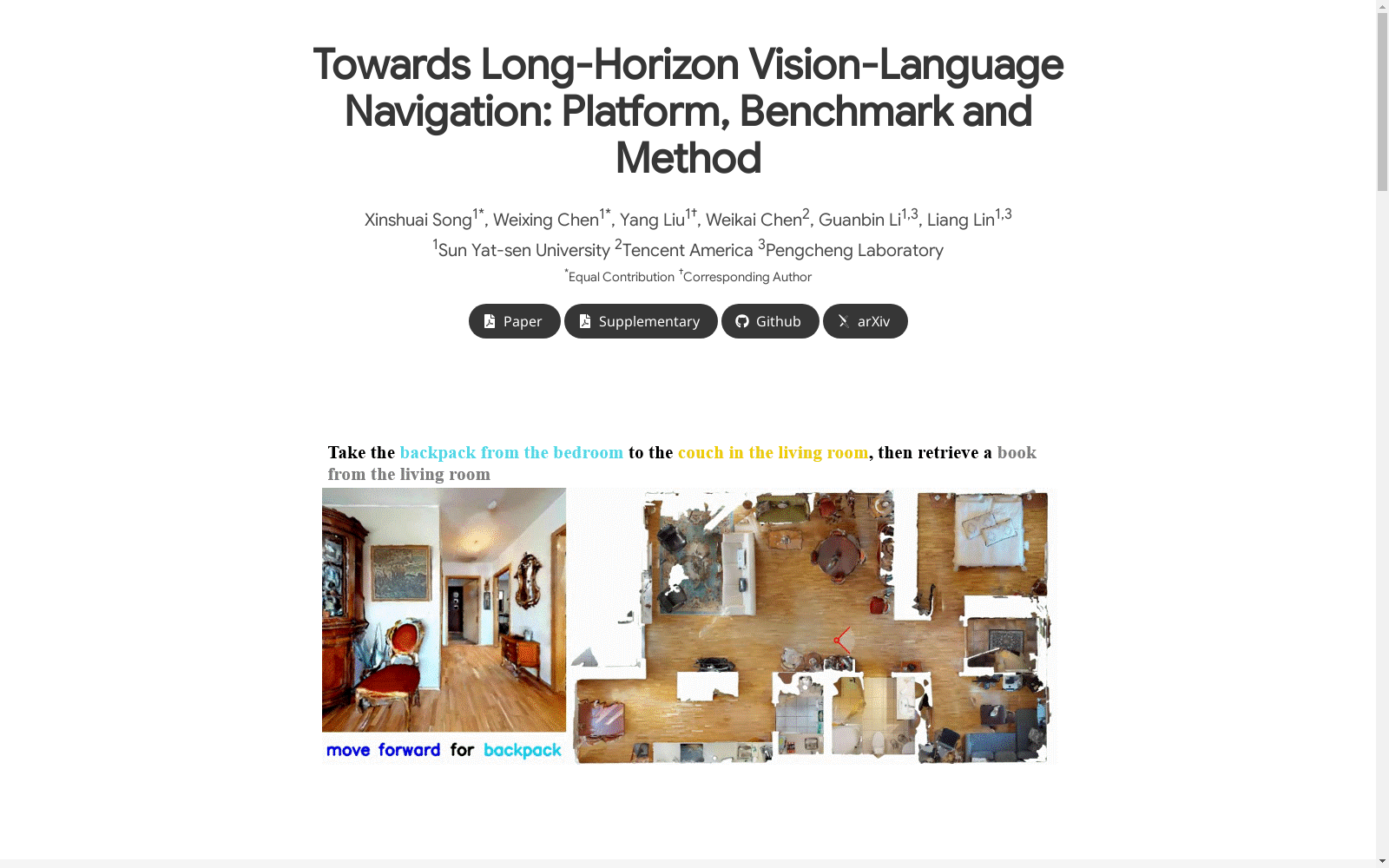
LHPR-VLN数据集的构建依托于自动化数据生成平台NavGen,该平台通过双向、多粒度的生成方法,生成了包含复杂任务结构的数据集。具体而言,NavGen利用GPT-4生成任务指令,结合场景资产和机器人配置,生成多阶段的导航任务。随后,这些任务在Habitat3模拟器中进行轨迹生成,并通过轨迹分割算法将复杂任务分解为多个单阶段导航任务,最终形成包含3260个任务的数据集,每个任务平均包含150个步骤。
特点
LHPR-VLN数据集的特点在于其专注于长时程视觉语言导航(LH-VLN),强调多阶段任务的连续规划与决策一致性。数据集中的任务通常包含多个子任务,要求智能体在动态环境中完成复杂的导航指令。此外,LHPR-VLN引入了独立成功率(ISR)、条件成功率(CSR)和基于真实路径的条件成功率(CGT)等细粒度评估指标,能够更全面地评估模型在多阶段任务中的表现。
使用方法
LHPR-VLN数据集的使用方法主要包括模型训练与评估。在训练阶段,模型通过模仿学习和轨迹监督学习交替进行,利用数据集中的任务指令和轨迹数据进行优化。在评估阶段,模型需要在Habitat3模拟器中执行多阶段导航任务,并根据ISR、CSR和CGT等指标进行性能评估。此外,数据集还支持对模型在动态环境中的适应性和记忆管理能力进行测试,为长时程视觉语言导航任务的研究提供了全面的实验平台。
背景与挑战
背景概述
LHPR-VLN数据集由中山大学、腾讯美国实验室和鹏城实验室的研究团队于2024年提出,旨在解决长时程视觉-语言导航(LH-VLN)任务中的复杂多阶段导航问题。该数据集包含3,260个任务,每个任务平均包含150个步骤,涵盖了从物体定位到需求驱动导航的多种场景。LHPR-VLN的提出填补了现有视觉-语言导航(VLN)数据集在长时程任务上的空白,推动了智能体在复杂动态环境中的持续决策与规划能力的研究。通过引入自动化数据生成平台NavGen,LHPR-VLN不仅提升了数据多样性,还为模型训练与评估提供了高质量的多阶段任务基准。该数据集在智能助手、服务机器人等实际应用中具有广泛的影响力。
当前挑战
LHPR-VLN数据集面临的挑战主要体现在两个方面。首先,在领域问题方面,现有的视觉-语言导航方法主要针对单阶段或短时程任务,难以应对复杂多阶段任务中的持续决策与动态规划需求。LHPR-VLN通过引入长时程任务,要求智能体在多个子任务中保持一致的决策能力,这对模型的推理与记忆能力提出了更高要求。其次,在数据构建过程中,生成高质量的多阶段导航任务数据面临诸多挑战。NavGen平台通过双向多粒度生成机制,解决了传统数据生成方法在任务多样性与数据效用上的局限性,但仍需克服复杂任务结构的自动化生成与标注难题。此外,如何设计合理的评估指标以准确反映模型在多阶段任务中的表现,也是LHPR-VLN数据集构建中的关键挑战。
常用场景
经典使用场景
LHPR-VLN数据集在视觉-语言导航(VLN)领域中被广泛应用于多阶段、长时程导航任务的研究。该数据集通过将复杂的导航任务分解为多个子任务,要求智能体在动态环境中连续执行这些任务,从而模拟真实世界中的复杂导航场景。经典的使用场景包括智能体在室内环境中执行多步骤的导航任务,如从浴室取毛巾并将其放置在厨房的特定位置,随后再执行其他相关任务。
实际应用
LHPR-VLN数据集的实际应用场景主要集中在服务机器人和自主导航系统中。例如,在家庭环境中,智能体可以根据用户的指令执行一系列复杂的任务,如从不同房间取物并放置到指定位置。这种能力在智能家居、医疗护理和仓储物流等领域具有广泛的应用前景,能够显著提升机器人在复杂环境中的自主性和实用性。
衍生相关工作
LHPR-VLN数据集的推出催生了一系列相关研究工作,特别是在多阶段导航任务和长时程规划领域。基于该数据集,研究人员提出了多种改进模型,如多粒度动态记忆(MGDM)模块,该模块通过结合短期和长期记忆机制,显著提升了智能体在动态环境中的导航能力。此外,该数据集还推动了自动化数据生成平台NavGen的发展,进一步丰富了VLN领域的数据资源和研究方法。
以上内容由遇见数据集搜集并总结生成


