BabelTower
收藏Hugging Face2025-04-09 更新2025-04-10 收录
下载链接:
https://huggingface.co/datasets/kcxain/BabelTower
下载链接
链接失效反馈官方服务:
资源简介:
BabelTower是一个C到CUDA的配对语料库,包含233对功能对齐的C和CUDA程序以及测试用例。它用于评估语言模型将顺序程序转换为并行程序的能力。
BabelTower is a paired corpus for C-to-CUDA conversion, consisting of 233 functionally aligned pairs of C and CUDA programs along with their corresponding test cases. It is utilized to evaluate the capability of language models to convert sequential programs into parallel programs.
创建时间:
2025-04-08
搜集汇总
数据集介绍
构建方式
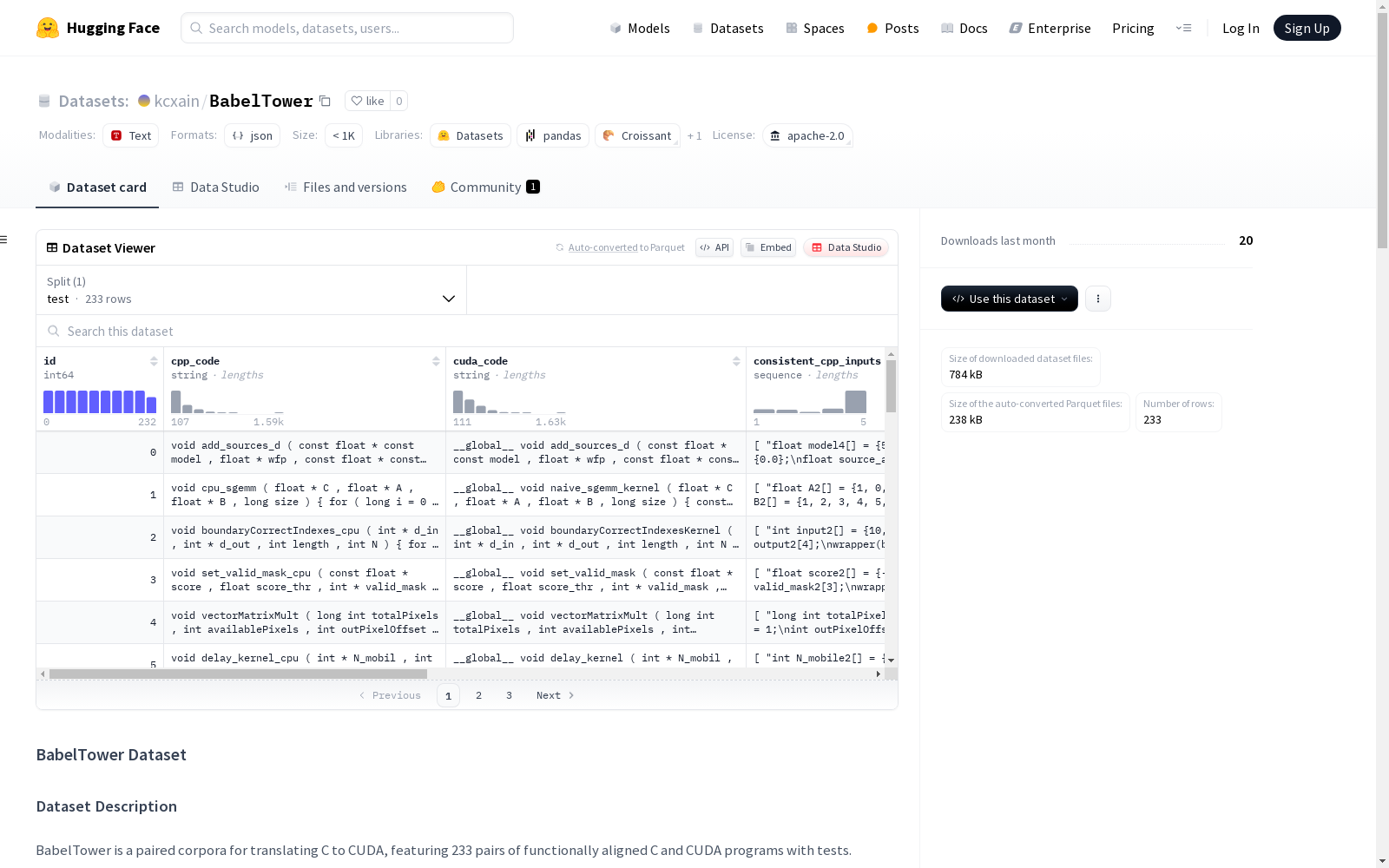
在并行计算领域,BabelTower数据集通过系统化方法构建了C与CUDA代码的精准映射关系。研究团队从GitHub平台爬取原始代码后,采用人工对齐方式筛选出233对功能等效的C/CUDA程序组合。为确保数据质量,利用GPT-4生成初始测试用例,经严格筛选保留有效案例后,通过双重执行验证机制采集两种代码版本的输出结果,最终形成包含输入输出完备对应关系的标准化语料库。
使用方法
研究者可通过HuggingFace数据集库快速加载该资源,标准接口返回包含7个关键字段的结构化数据。典型应用场景包含:使用cpp_code与cuda_code字段进行序列到并行代码的转换模型训练;通过consistent_cpp_inputs和consistent_cuda_inputs验证转换正确性;借助cuda_wrapper实现CUDA内核的标准化调用。评估阶段可参考官方提供的Pass@k度量脚本,对语言模型的并行化转换能力进行量化分析。
背景与挑战
背景概述
BabelTower数据集由Yuanbo Wen等研究人员于2022年提出,旨在解决程序自动并行化翻译的核心研究问题。该数据集包含233对功能对齐的C与CUDA程序,并附带测试用例,用于评估语言模型将顺序程序转换为并行版本的能力。作为程序翻译领域的重要资源,BabelTower通过提供精确对齐的代码对和丰富的测试用例,推动了自动并行化技术的研究。其构建过程结合了GitHub代码爬取、人工对齐和GPT-4生成的测试用例验证,体现了跨领域知识融合的创新方法。该成果发表于国际机器学习大会(ICML 2022),为高性能计算与程序语言处理领域提供了新的研究基准。
当前挑战
BabelTower数据集面临的主要挑战体现在两个方面:在领域问题层面,C到CUDA的自动翻译需要克服顺序程序到并行程序的语义等价转换难题,包括循环展开、内存访问模式优化等复杂问题;在构建过程中,确保代码对功能对齐的精确性是一大挑战,研究人员需通过人工验证和测试用例筛选来保证数据质量。此外,生成足够覆盖各种并行化场景的测试用例也颇具难度,需要结合大型语言模型和动态执行验证。数据规模相对较小(仅233对样本)可能限制模型训练的泛化能力,这对未来扩展数据集提出了要求。
常用场景
经典使用场景
在并行计算领域,BabelTower数据集为研究C到CUDA的自动程序转换提供了基准测试平台。其核心价值在于233对功能对齐的C与CUDA程序,每对均配备可执行测试用例,使得研究者能够系统评估语言模型将串行代码转化为并行实现的能力。数据集通过严格的输入输出一致性验证,为模型性能量化提供了可靠标准。
解决学术问题
该数据集有效解决了异构编程中自动并行化的关键科学问题。通过提供精确对齐的C/CUDA代码对,它填补了程序翻译领域缺乏可验证基准的空白,使得研究者能够定量分析线程调度、内存管理等并行化策略的优劣。其测试用例覆盖多维参数空间,为评估模型处理边界条件的能力建立了严谨框架。
实际应用
在实际工程场景中,BabelTower可加速科学计算与图形渲染领域的代码迁移。例如地震模拟软件开发者能借助该数据集训练模型,将传统CPU端的波动方程求解器自动转换为GPU优化版本。数据集提供的封装模板显著降低了CUDA编程门槛,使领域专家无需深入掌握并行编程细节即可获得性能提升。
数据集最近研究
最新研究方向
在异构计算领域,BabelTower数据集为研究C到CUDA的自动并行化程序翻译提供了重要基准。随着GPU加速计算在科学计算和深度学习中的广泛应用,如何高效地将传统串行代码转化为并行实现成为研究热点。该数据集通过233对功能对齐的C与CUDA程序及其测试用例,支持语言模型在并行化代码转换能力的评估。最新研究聚焦于利用大语言模型实现端到端的自动并行化翻译,结合强化学习优化翻译质量,并探索跨架构代码生成的通用性。相关成果已应用于高性能计算、AI编译器优化等领域,为提升异构编程效率提供了新思路。
以上内容由遇见数据集搜集并总结生成


