openreview_dataset
收藏Hugging Face2025-04-02 更新2025-04-02 收录
下载链接:
https://huggingface.co/datasets/guochenmeinian/openreview_dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个关于学术论文评审的数据集,它包含了论文评审的相关信息,适用于自然语言处理领域的研究和模型微调。数据集来源于开源评审平台,可能包含评审者对论文的评价、意见和反馈。
This is a dataset dedicated to academic paper review-related research. It encompasses comprehensive information concerning paper reviews, and is suitable for both academic research and model fine-tuning within the natural language processing domain. The dataset is sourced from open-source review platforms, and may include reviewers' evaluations, opinions, and feedback on submitted academic papers.
创建时间:
2025-03-28
原始信息汇总
openreview_dataset 数据集概述
基本描述
- 语言: 英文 (en)
- 许可证: Apache-2.0
- 标签: paper-review, academic-review, nlp, openreview
用途
- 适用于微调 (finetuning) 任务
上传方式
- 使用命令:
huggingface-cli upload guochenmeinian/openreview_dataset . --repo-type=dataset
搜集汇总
数据集介绍
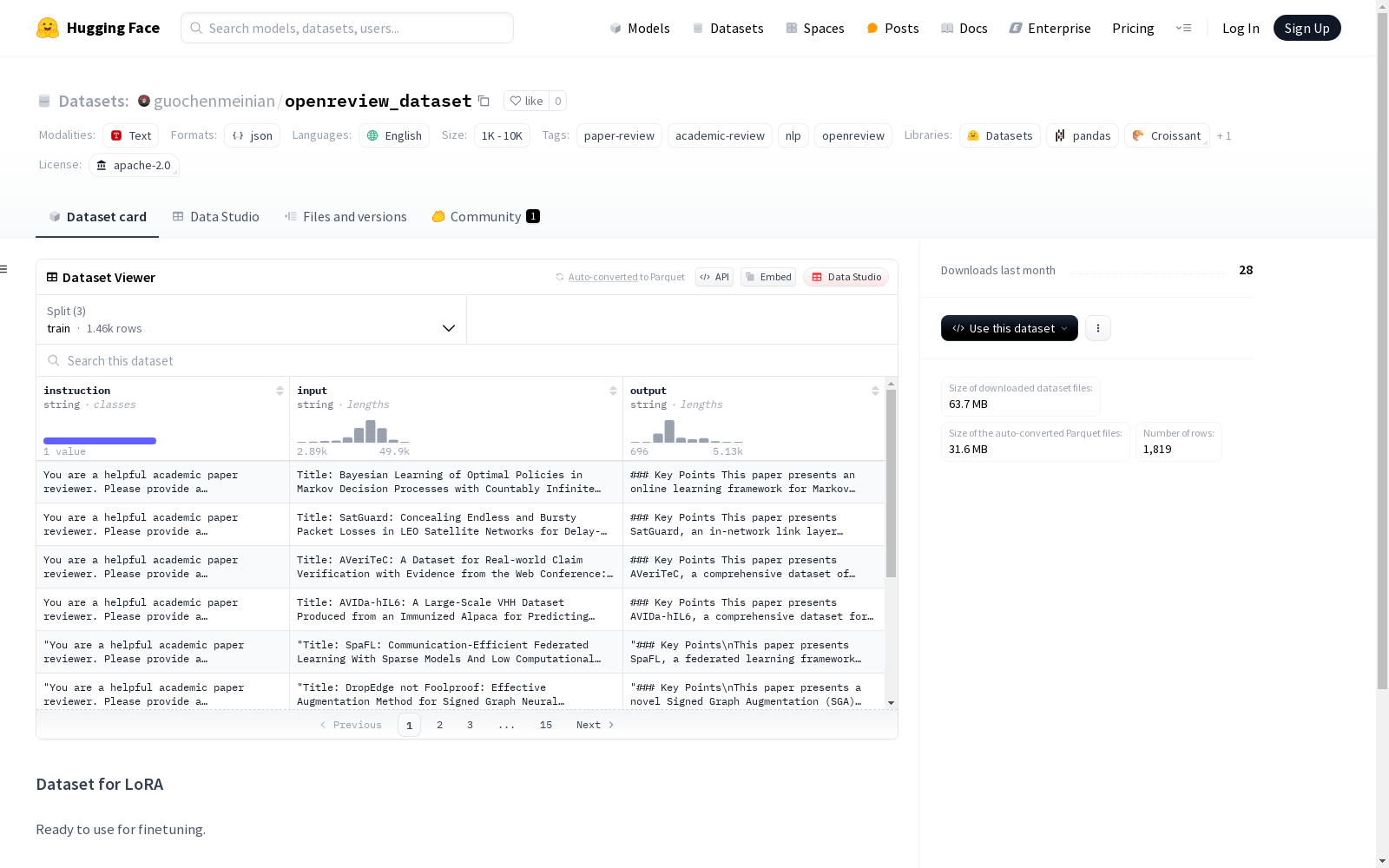
构建方式
在学术论文评审领域,openreview_dataset的构建体现了严谨的数据采集流程。该数据集源自OpenReview平台,通过系统化地收集学术论文及其同行评审内容构建而成,涵盖了多学科领域的评审互动数据。数据预处理过程中,采用自动化脚本提取结构化评审意见,同时保留原始文本的学术语境,确保数据既具有机器可读性又不失学术表达的精确性。
特点
作为专注于论文评审场景的语料库,该数据集展现出鲜明的领域特异性。其核心价值在于完整保留了论文-评审的对应关系,每条数据包含原始论文片段与多角度评审意见,为研究学术交流模式提供了丰富素材。数据经过匿名化处理但保持语言风格差异,既符合伦理规范又真实反映了学术评审的语言特征,特别适合自然语言处理任务中的细粒度分析。
使用方法
针对机器学习研究者的需求,该数据集提供了即用的微调支持。用户可通过HuggingFace生态直接加载数据,其标准化的JSON格式适配主流NLP框架。典型应用场景包括评审意见生成模型训练、学术文本风格迁移等任务,数据划分建议遵循原始平台的时间戳以确保评估的客观性。对于特定研究方向,可结合领域关键词进行数据过滤以提升任务相关性。
背景与挑战
背景概述
OpenReview数据集作为学术论文评审领域的重要资源,由OpenReview平台于近年推出,旨在促进同行评审过程的透明化和高效化。该数据集汇聚了全球范围内多个学科的论文评审数据,包括评审意见、作者回复以及最终的评审决策,为自然语言处理技术在学术领域的应用提供了丰富的语料。其核心研究问题聚焦于如何利用机器学习方法优化论文评审流程,提升评审质量与效率,对推动开放科学和学术交流的创新发展具有深远影响。
当前挑战
OpenReview数据集在解决学术论文自动评审这一复杂任务时面临多重挑战。评审意见的多样性和主观性使得模型难以准确捕捉评审者的意图和标准,而评审数据中的专业术语和领域知识也增加了自然语言处理的难度。在数据集构建过程中,确保评审数据的匿名性和隐私保护是一项关键挑战,同时,跨学科数据的整合与标准化处理也对数据集的构建质量提出了更高要求。
常用场景
经典使用场景
在学术论文评审领域,openreview_dataset为研究者提供了丰富的论文评审数据,这些数据通常用于训练和评估自然语言处理模型,特别是在理解学术评审意见的语义和情感分析方面。通过分析这些数据,研究者能够深入探讨评审意见的生成机制及其对论文质量的影响。
实际应用
在实际应用中,openreview_dataset被广泛用于构建自动化评审辅助工具。这些工具能够帮助编辑和评审人快速生成高质量的评审意见,同时为作者提供改进论文的建议。此外,该数据集还被用于开发教育工具,帮助学生和年轻研究者理解学术评审的标准和流程。
衍生相关工作
基于openreview_dataset,研究者已经开发了多种自然语言处理模型,如评审意见生成模型和评审质量评估模型。这些工作不仅推动了学术评审自动化的发展,还为相关领域的其他研究提供了重要的数据支持和基准。
以上内容由遇见数据集搜集并总结生成


