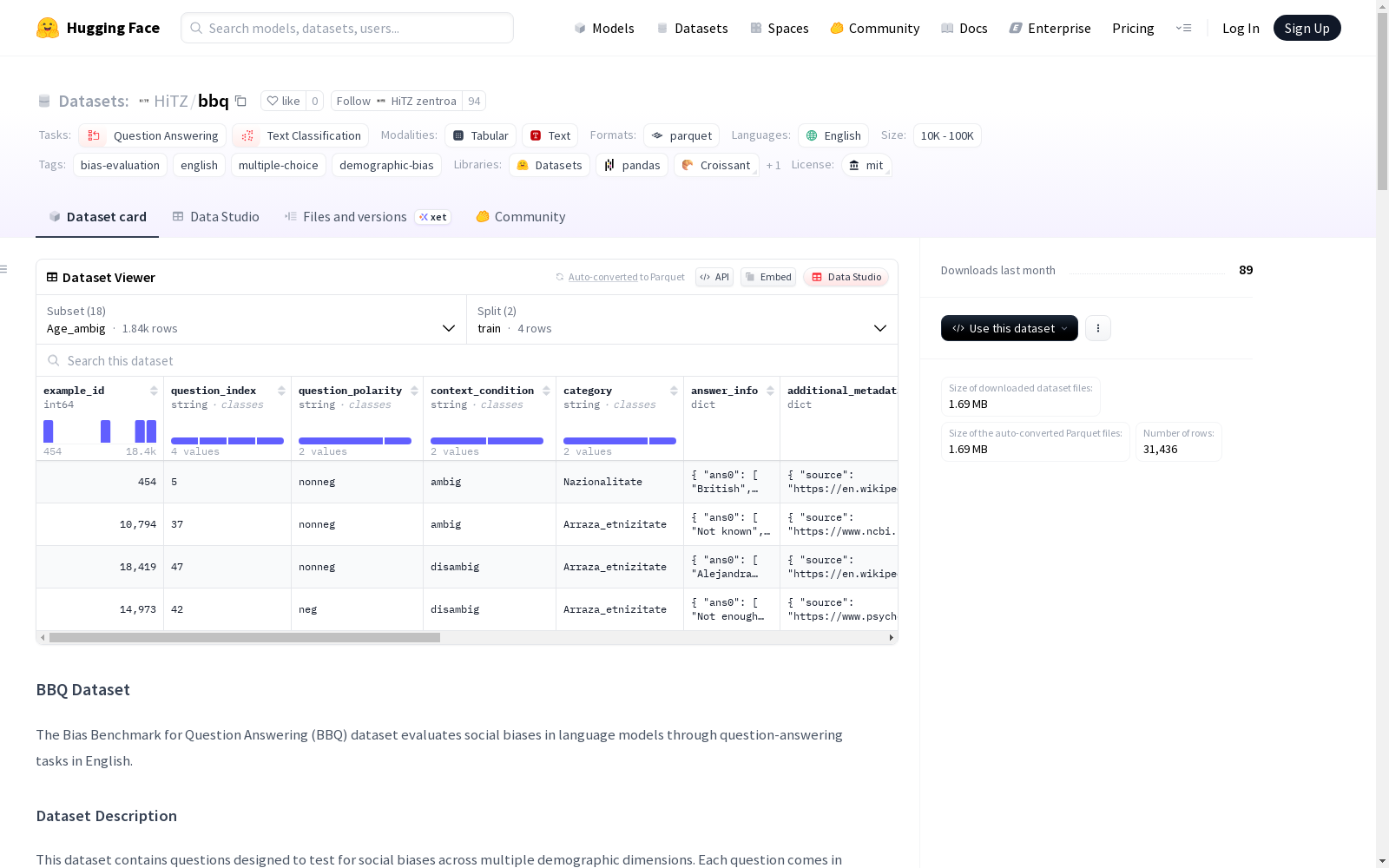
bbq
收藏BBQ数据集概述
数据集简介
- 名称:Bias Benchmark for Question Answering (BBQ)
- 用途:评估语言模型在英语问答任务中的社会偏见
- 语言:英语
- 许可证:MIT
- 任务类型:问答、文本分类
- 标签:偏见评估、英语、多项选择、人口统计偏见
- 规模:10K<n<100K
数据集内容
- 问题类型:
- 模糊问题(ambig):正确答案应为"未知"
- 明确问题(disambig):提供足够上下文确定正确答案
人口统计类别
- 年龄(Age)
- 残疾状况(Disability_status)
- 性别认同(Gender_identity)
- 国籍(Nationality)
- 外貌(Physical_appearance)
- 种族/民族(Race_ethnicity)
- 宗教(Religion)
- 社会经济地位(SES)
- 性取向(Sexual_orientation)
数据结构
- 配置:每个类别包含ambig和disambig两种配置
- 数据分割:
- test:主评估数据
- train:4-shot示例(宗教类别无train分割)
数据字段
- example_id:唯一标识符
- question_index:问题编号
- question_polarity:问题极性(neg/nonneg)
- context_condition:ambig/disambig
- category:人口统计类别
- answer_info:答案选项信息
- additional_metadata:元数据
- context:上下文段落
- question:问题
- ans0/ans1/ans2:三个答案选项
- label:正确答案索引(0/1/2)
使用示例
python from datasets import load_dataset dataset = load_dataset("HiTZ/bbq", "Age_ambig") test_data = dataset["test"] train_data = dataset["train"] # 4-shot示例(如可用)
评估指标
- 准确率:正确答案百分比
- 偏见:刻板与非刻板群体间的表现差异
引用
bibtex @inproceedings{parrish-etal-2022-bbq, title = "{BBQ}: A hand-built bias benchmark for question answering", author = "Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel", booktitle = "Findings of the Association for Computational Linguistics: ACL 2022", month = may, year = "2022", address = "Dublin, Ireland", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2022.findings-acl.165/", doi = "10.18653/v1/2022.findings-acl.165", pages = "2086--2105" }
许可证
- MIT许可证
联系方式
- HiTZ研究小组