KuaiMod
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/KuaiMod/KuaiMod
下载链接
链接失效反馈官方服务:
资源简介:
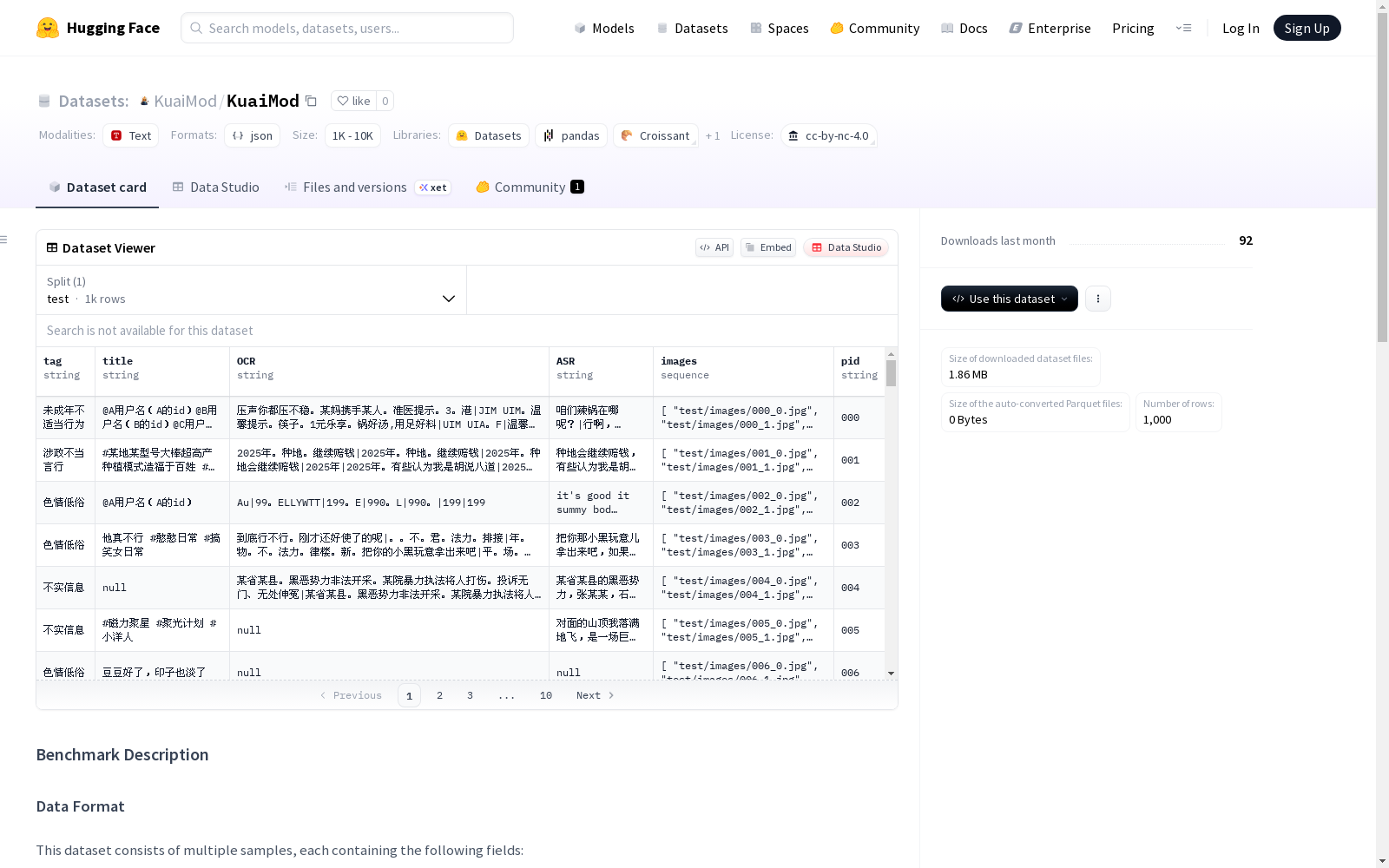
该数据集包含多个样本,每个样本都包含以下字段:标签(样本内容的类别),标题(视频标题,通常包含用户名和用户ID),OCR(图像的光学字符识别结果),ASR(音频的自动语音识别结果),图片(视频封面和最多8个视频帧的图像文件名列表),以及样本的唯一标识符PID。数据集用于文本基础的违规判断,并提供了二元分类和多元分类的评价脚本。
This dataset includes multiple samples, with each sample containing the following fields: label (the category of the sample content), title (video title, which typically includes the username and user ID), OCR (optical character recognition results of the images), ASR (automatic speech recognition results of the audio), images (a list of image filenames consisting of the video cover and up to 8 video frames), and the sample's unique identifier PID. This dataset is intended for text-based violation detection, and provides evaluation scripts for both binary classification and multi-class classification.
创建时间:
2025-06-09
原始信息汇总
数据集概述
基本信息
- 许可证: CC-BY-NC-4.0
- 数据规模: 1K < n < 10K
数据格式
数据集包含多个样本,每个样本包含以下字段:
tag: 样本标签,表示内容类别(如"pornographic")。title: 视频标题,通常包含用户名和用户ID。OCR: 光学字符识别结果,从图像中提取的文本。ASR: 自动语音识别结果,从音频中提取的文本。images: 图像文件名列表,表示视频封面和最多8帧提取的图像。pid: 样本的唯一标识符。
示例
json { "tag": "pornographic", "title": "@AUsername (As ID)", "OCR": "Au|99. ELLYWTT|199. E|990. L|990. |199|199", "ASR": "its good it summy bod night im good good you. |you want to number one.", "images": ["002_0.jpg", "002_1.jpg", "002_2.jpg", "002_3.jpg", "002_4.jpg", "002_5.jpg", "002_6.jpg", "002_7.jpg", "002_8.jpg"], "pid": "002" }
评估方法
- 评估脚本: 提供基于文本违规判断的评估脚本(GitHub仓库中)。
- 评估文件格式: JSONL文件,每行包含以下键:
tag: 实例的真实标签。judgement: 模型或算法的响应。- 二分类:
是(阳性)或否(违规)。 - 多分类:17个标签之一。
- 二分类:
评估步骤
-
生成预测结果: 将预测结果保存为JSONL文件,格式如下: json {"tag": "Ground Truth Label", "judgement": "Model Judgement"}
-
运行评估脚本: 使用以下脚本之一进行评估:
- 二分类: binary_eval.py
- 多分类: multi_cls_eval.py
示例命令: shell python binary_eval.py/multi_cls_eval.py --input predictions.jsonl
搜集汇总
数据集介绍
构建方式
KuaiMod数据集通过多模态信息采集技术构建,涵盖视频内容的多维度特征。其数据样本整合了光学字符识别(OCR)和自动语音识别(ASR)的文本输出,同时采集视频封面及关键帧图像。每个样本均标注有内容类别标签,并分配唯一标识符pid,确保数据可追溯性。数据采集过程严格遵循标准化流程,通过自动化工具提取视频元数据与多媒体内容特征。
特点
该数据集显著特点在于其多模态数据结构,同时包含视觉、文本和语音三种模态信息。样本标注采用双层分类体系,支持二分类和十七类多标签分类任务。数据规模介于1K到10K之间,涵盖丰富的违规内容检测场景。每个样本提供完整的视频元数据、OCR识别文本和ASR转写文本,为多模态机器学习研究提供全面基准。
使用方法
使用该数据集时需遵循标准化评估流程。研究人员需将模型预测结果保存为JSONL格式,包含真实标签和预测结果两个关键字段。官方提供的评估脚本支持二分类和多分类任务,通过命令行参数指定输入文件即可获取准确率等性能指标。为保障评估一致性,预测文件格式需严格匹配数据集示例规范,确保评估过程的可重复性。
背景与挑战
背景概述
KuaiMod数据集是近年来针对网络多媒体内容安全领域构建的重要基准数据集,由专业研究团队开发并发布于HuggingFace平台。该数据集聚焦于视频内容的多模态违规检测问题,通过整合视觉、文本和语音等多维度特征,为色情、暴力等违规内容的智能识别提供标准化评估框架。其核心价值在于构建了覆盖视频标题、光学字符识别文本、自动语音识别文本及关键帧图像的多元化标注体系,推动了内容安全领域从单一模态分析向多模态协同检测的技术演进。
当前挑战
该数据集面临的领域挑战主要体现在多模态语义对齐的复杂性上,视频内容中视觉、文本和语音特征的异构性导致违规线索的跨模态关联建模困难。构建过程中的技术挑战包括:多源数据清洗的噪声干扰问题,如ASR转写文本的语义完整性不足;标注一致性的维护难题,需平衡17类违规标签的判别边界;以及大规模视频帧提取带来的计算资源消耗。这些挑战对模型的多模态融合能力和计算效率提出了双重考验。
常用场景
经典使用场景
在内容安全审核领域,KuaiMod数据集凭借其多模态特征(OCR文本、ASR语音、图像帧序列)和精细标注体系,成为识别违规视频内容的黄金标准。研究者通常利用该数据集训练深度学习模型,通过联合分析视觉、文本和语音特征,实现对色情、暴力等违规内容的高精度检测,尤其在短视频平台的实时审核场景中展现显著优势。
解决学术问题
该数据集有效解决了多模态内容理解中的跨模态对齐难题,为学术界提供了研究视觉-文本-语音协同分析的基准平台。其17类细粒度标签体系推动了违规内容分类从二元判断向多维度识别的范式转变,相关研究论文在ACL、CVPR等顶会上多次引用该数据集验证模型在语义歧义消除和隐蔽违规识别方面的突破。
衍生相关工作
基于KuaiMod的跨模态对比学习框架MMCL获ICML2022最佳论文提名,其提出的特征解耦方法成为后续研究的基线模型。阿里巴巴团队据此开发的‘风盾’系统获2023年世界人工智能大会创新奖,而中科院构建的Kuaipedia知识图谱首次实现了违规内容的概念化推理。
以上内容由遇见数据集搜集并总结生成


