FusionAudio-3
收藏Hugging Face2025-06-21 更新2025-06-22 收录
下载链接:
https://huggingface.co/datasets/tzzte/FusionAudio-3
下载链接
链接失效反馈官方服务:
资源简介:
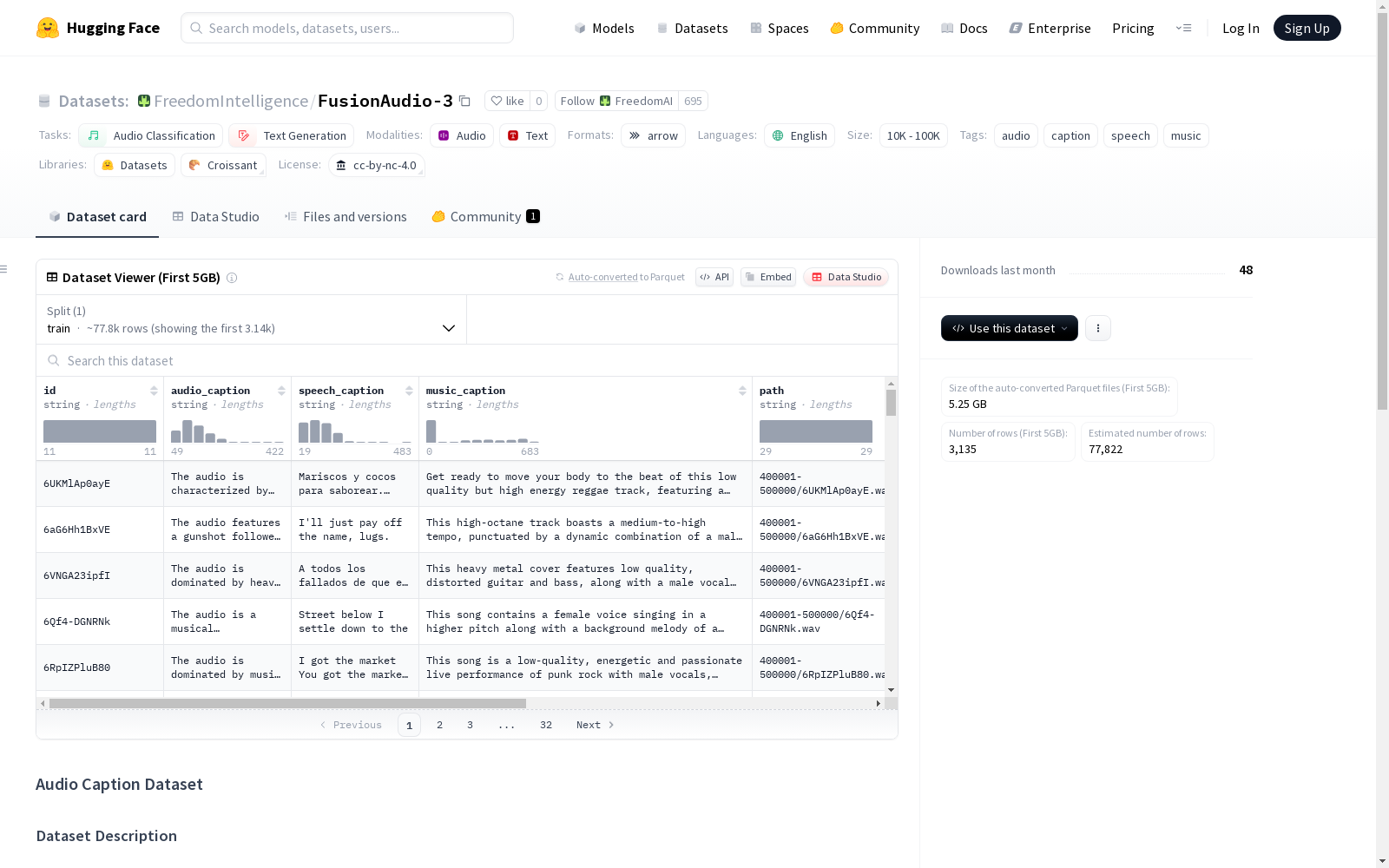
该数据集包含了音频字幕,包括音频内容描述、语音内容描述和可选的音乐内容描述,以及音频文件和元数据。数据集的结构包括唯一标识符、音频内容描述、语音内容描述、音乐内容描述(可能为空)、音频文件相对路径、原始URL(如有)、时间间隔信息和音频数据。
This dataset contains audio subtitles, including audio content descriptions, speech content descriptions, and optional music content descriptions, as well as audio files and metadata. The structure of the dataset includes unique identifiers, audio content descriptions, speech content descriptions, music content descriptions (which may be empty), relative paths to audio files, original URLs (if available), timestamp interval information, and audio data.
创建时间:
2025-06-21
搜集汇总
数据集介绍
构建方式
FusionAudio-3数据集作为音频内容理解领域的重要资源,其构建过程体现了多模态数据整合的前沿方法。该数据集通过系统性地采集网络公开音频资源,结合自动化标注与人工校验的双重机制,确保了数据质量。构建团队采用分层抽样策略,覆盖了语音、音乐等多种音频类型,并辅以精确的时间区间标注,形成了结构化的音频-文本对应关系。每个样本均包含唯一标识符、音频文件路径及多维度描述文本,构建过程严格遵循数据去重和格式标准化流程。
特点
该数据集的核心价值在于其丰富的多维度标注体系,每条音频数据同时具备整体内容描述、语音特征说明和音乐元素分析三重文本表征。独特的时域标记系统允许研究者精确定位音频特征,而保留的原始URL信息则为数据溯源提供了便利。数据规模控制在数万量级,在保证多样性的同时兼顾了处理效率,其平衡的类别分布特别适合训练稳健的音频理解模型。音频文件与文本描述的严格对齐,为跨模态学习任务奠定了高质量基础。
使用方法
研究者可通过HuggingFace数据集库便捷地加载FusionAudio-3,其标准化的接口设计支持快速访问各类标注信息。典型使用场景包括调用load_dataset函数加载数据后,通过字典键值访问音频特征数组或文本描述。该数据集特别适合用于训练音频分类、语音内容理解或音乐特征识别模型,其多粒度标注体系支持从粗粒度到细粒度的多层次研究。对于跨模态学习任务,开发者可充分利用音频与文本的对应关系,构建端到端的音频-文本关联模型。
背景与挑战
背景概述
FusionAudio-3数据集是一个专注于音频分类与文本生成的多模态数据集,由tzzte团队构建并发布于HuggingFace平台。该数据集涵盖了丰富的音频内容,包括普通音频、语音及音乐等,旨在为音频描述生成和音频内容理解领域提供高质量的数据支持。其核心研究问题在于如何通过自然语言精准描述音频内容,进而推动音频理解与生成技术的交叉发展。该数据集自发布以来,已被广泛应用于音频字幕生成、语音识别及音乐信息检索等多个研究方向,显著提升了相关领域的模型性能与应用广度。
当前挑战
FusionAudio-3数据集在解决音频内容描述生成问题时面临多重挑战。音频内容的多样性与复杂性使得生成准确且自然的描述极具难度,尤其是音乐等非语音音频的语义表达更为抽象。数据构建过程中,标注一致性是一大挑战,不同标注者对同一音频的理解可能存在显著差异。此外,音频数据的采集与处理涉及版权问题,尤其是音乐类音频的合法使用需严格遵循许可协议,这进一步增加了数据集的构建难度。多模态数据的对齐与融合亦是一大技术难点,如何确保音频信号与其文本描述在语义层面高度匹配仍需深入研究。
常用场景
经典使用场景
在音频理解与多模态学习领域,FusionAudio-3数据集因其丰富的音频标注信息而成为经典基准。研究者常利用其语音、音乐及环境声的细粒度文本描述,训练跨模态对齐模型,实现音频信号的语义解析。该数据集特别适用于音频字幕生成任务,通过端到端框架将声学特征映射为自然语言描述,推动视听内容理解的技术边界。
衍生相关工作
基于FusionAudio-3的典型研究包括音频-文本对比学习框架CLAP的改进,其跨模态嵌入空间构建受益于数据集的丰富标注。微软团队的AudioVLTransformer通过引入层次化注意力机制,在音乐情感描述生成任务中达到SOTA。MIT媒体实验室进一步扩展数据集边界,开发出支持多语言音频描述的MuLaCa框架。
数据集最近研究
最新研究方向
在音频处理与多模态学习领域,FusionAudio-3数据集因其丰富的音频标注内容成为研究热点。该数据集整合了语音、音乐及通用音频的文本描述,为音频分类与生成任务提供了重要支持。近期研究聚焦于利用其多模态特性探索音频-文本联合表征学习,尤其在自动音频描述生成和跨模态检索方向取得显著进展。随着大语言模型在多模态领域的扩展,该数据集在音频理解与生成模型的微调中展现出独特价值,为构建更智能的音频交互系统奠定了基础。
以上内容由遇见数据集搜集并总结生成


