livesqlbench-base-lite
收藏Hugging Face2025-06-06 更新2025-06-07 收录
下载链接:
https://huggingface.co/datasets/birdsql/livesqlbench-base-lite
下载链接
链接失效反馈官方服务:
资源简介:
LiveSQLBench-Base-Lite 是一个动态、无污染的基准测试,用于评估LLM在复杂、真实世界的文本到SQL任务上的性能。包含18个终端用户级别的数据库和270个任务,支持SELECT和CRUD操作查询,并提供层次知识库。
LiveSQLBench-Base-Lite is a dynamic, uncontaminated benchmark for evaluating the performance of Large Language Models (LLMs) on complex, real-world text-to-SQL tasks. It includes 18 end-user-level databases and 270 tasks, supports SELECT and CRUD operation queries, and provides a hierarchical knowledge base.
创建时间:
2025-05-30
原始信息汇总
LiveSQLBench-Base-Lite 数据集概述
📜 基本信息
- 许可证: cc-by-4.0
- 维护团队: 🦜 BIRD Team @ HKU & ☁️ Google Cloud
- 数据集标签: text-to-sql, database
- 数据文件: livesqlbench_data.jsonl (dev split)
🌟 数据集特点
- 动态无污染基准: 用于评估LLM在复杂、真实世界的文本到SQL任务上的表现。
- 多样化查询: 包括商业智能(BI)和CRUD操作等真实用户查询。
- 层级知识库(HKB): 支持结构化JSON格式,需要多跳推理能力。
- 全SQL频谱支持: 不仅支持SELECT查询,还支持CRUD操作。
- 自动化评估: 通过PostgreSQL模板和docker实现快速评估。
📂 数据结构
- 数据库目录: 每个数据库有独立的目录,包含:
*_schema.txt: 数据库模式*_kb.jsonl: 层级知识库条目*_column_meaning_base.json: 数据库列解释
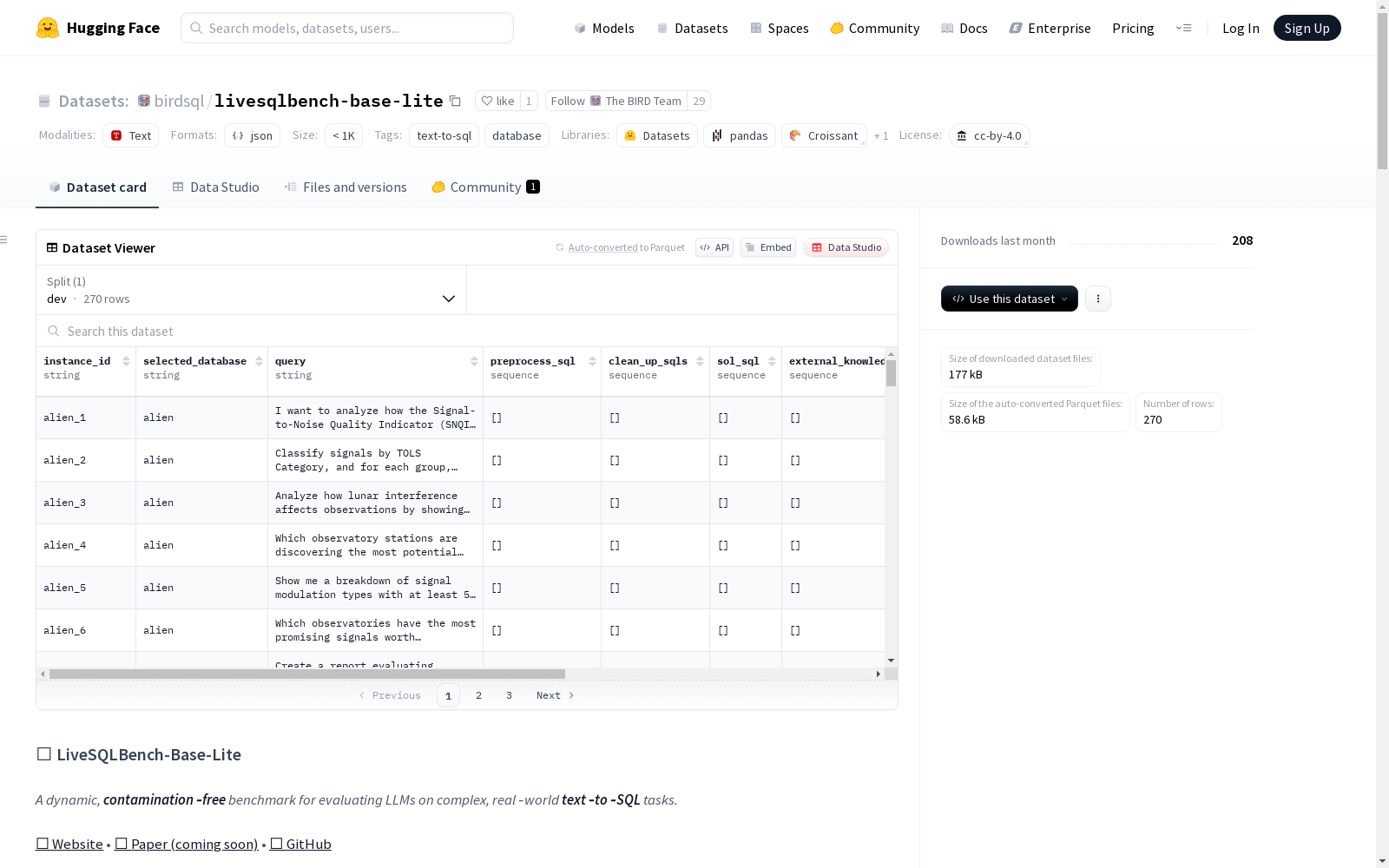
📋 数据字段
- instance_id: 唯一任务标识符
- selected_database: 关联数据库名称
- query: 用户查询
- sol_sql: 真实SQL解决方案(受限访问)
- external_knowledge: 解决任务所需的外部知识ID(受限访问)
- preprocess_sql: SQL设置查询
- clean_up_sql: 重置数据库状态的SQL查询
- test_cases: 验证SQL的测试用例(受限访问)
- category: "Query"(仅SELECT)或"Management"(CRUD)
- high_level: 用户查询是否包含高级描述
- conditions: 用户查询中的小数/不同条件
- difficulty_tier: 任务难度(简单、中等、挑战性)
🔒 完整数据访问
部分字段(如sol_sql、test_cases等)未公开,需通过邮件申请访问权限。
🏆 模型性能(2025-05-28)
排名前五的模型:
- o3-mini (44.81%成功率)
- GPT-4.1 (40.00%成功率)
- o4-mini (37.80%成功率)
- o3 (37.40%成功率)
- o1-preview (37.03%成功率)
🔄 未来版本计划
- LiveSQLBench-Base-Full
- LiveSQLBench-Large-Lite
- LiveSQLBench-Large-Full
📄 许可证
cc-by-sa-4.0
搜集汇总
数据集介绍
构建方式
LiveSQLBench-Base-Lite数据集通过动态构建方式,从广泛且定期更新的CSV数据集中提取,形成了包含18个终端用户级别数据库的基准测试。每个数据库均配有层次化知识库(HKB),以JSON格式呈现,并涵盖270项任务,其中180项为SELECT查询,90项为数据库管理任务。数据集的设计注重真实性和复杂性,通过与专家合作持续优化,确保任务覆盖商业智能和CRUD操作等多种场景。
使用方法
使用LiveSQLBench-Base-Lite数据集时,用户可通过克隆HuggingFace仓库获取数据文件和相关元文件。数据集目录结构清晰,每个数据库包含模式文件、知识库文件和列含义说明文件。为保障数据安全,部分敏感字段如解决方案SQL和测试用例需通过邮件申请获取。评估过程支持通过PostgreSQL模板和Docker快速执行,用户可参考GitHub仓库获取详细的使用和评估指南。
背景与挑战
背景概述
LiveSQLBench-Base-Lite数据集由香港大学BIRD团队与Google Cloud联合开发,旨在为文本到SQL转换任务提供一个动态且无污染的评估基准。该数据集创建于2025年,专注于解决现实世界中复杂的数据库查询问题,涵盖商业智能(BI)和CRUD操作等多种场景。其核心研究问题在于如何有效评估大型语言模型(LLM)在处理真实用户查询时的表现,特别是在需要多跳推理和外部知识支持的复杂SQL生成任务中。该数据集的推出显著推动了文本到SQL领域的研究,为模型评估提供了更加真实和多样化的测试环境。
当前挑战
LiveSQLBench-Base-Lite数据集面临的主要挑战包括:1) 领域问题的复杂性,如处理多跳推理和外部知识依赖的SQL生成任务;2) 构建过程中的技术难题,包括动态数据库的维护、真实用户查询的收集与标注,以及自动化评估系统的设计。此外,确保数据集的持续更新和隐藏测试集的保密性也是重要的挑战。这些因素共同构成了该数据集在推动文本到SQL研究中的关键难点。
常用场景
经典使用场景
在数据库与自然语言处理交叉领域,LiveSQLBench-Base-Lite数据集为评估大型语言模型在复杂文本到SQL转换任务中的表现提供了标准化测试平台。该数据集通过模拟真实业务场景中的用户查询,包括商业智能分析和数据库管理操作,为研究者构建了涵盖从简单到困难不同难度层级的评估体系。其动态更新的数据库结构和层次化知识库设计,特别适合检验模型在理解模糊用户意图、处理多跳推理等核心能力上的表现。
解决学术问题
该数据集有效解决了文本到SQL领域三个关键学术问题:一是通过真实业务场景的查询-语句对,填补了传统基准测试与现实应用之间的鸿沟;二是引入层次化知识库机制,为研究外部知识注入对SQL生成的影响提供了实验基础;三是首创完整SQL频谱支持,使得CRUD操作与SELECT查询能在统一框架下进行评估。这些创新显著提升了评估结果的实用性和可信度,推动了对话式数据库交互系统的研究进展。
实际应用
在企业级数据库管理系统中,该数据集支撑的评估方法可直接应用于智能查询接口开发。通过验证模型在270个真实任务上的表现,技术团队能够筛选出最适合业务场景的文本到SQL引擎。其包含的数据库模式解释文件和自动化测试框架,已被多家云服务商用于优化其自然语言数据库产品的核心算法,特别是在处理包含业务术语的复杂查询时展现出独特价值。
数据集最近研究
最新研究方向
在自然语言处理与数据库交互领域,LiveSQLBench-Base-Lite数据集以其动态更新、无污染的特性成为评估大型语言模型在复杂文本到SQL转换任务中的新标杆。该数据集不仅涵盖了商业智能查询和数据库管理操作,还引入了层次化知识库(HKB)以支持多跳推理能力,为模型在真实场景中的表现提供了全面评估框架。当前研究热点聚焦于如何利用该数据集的动态特性提升模型在工业级数据库上的泛化能力,以及探索多模态知识库与SQL生成的协同优化。这一方向对于推动智能数据库助手、自动化业务报表生成等应用具有重要意义,也为跨模态推理研究提供了新的实验平台。
以上内容由遇见数据集搜集并总结生成


