qwark-corpus
收藏Hugging Face2025-01-05 更新2025-01-06 收录
下载链接:
https://huggingface.co/datasets/qingy2024/qwark-corpus
下载链接
链接失效反馈官方服务:
资源简介:
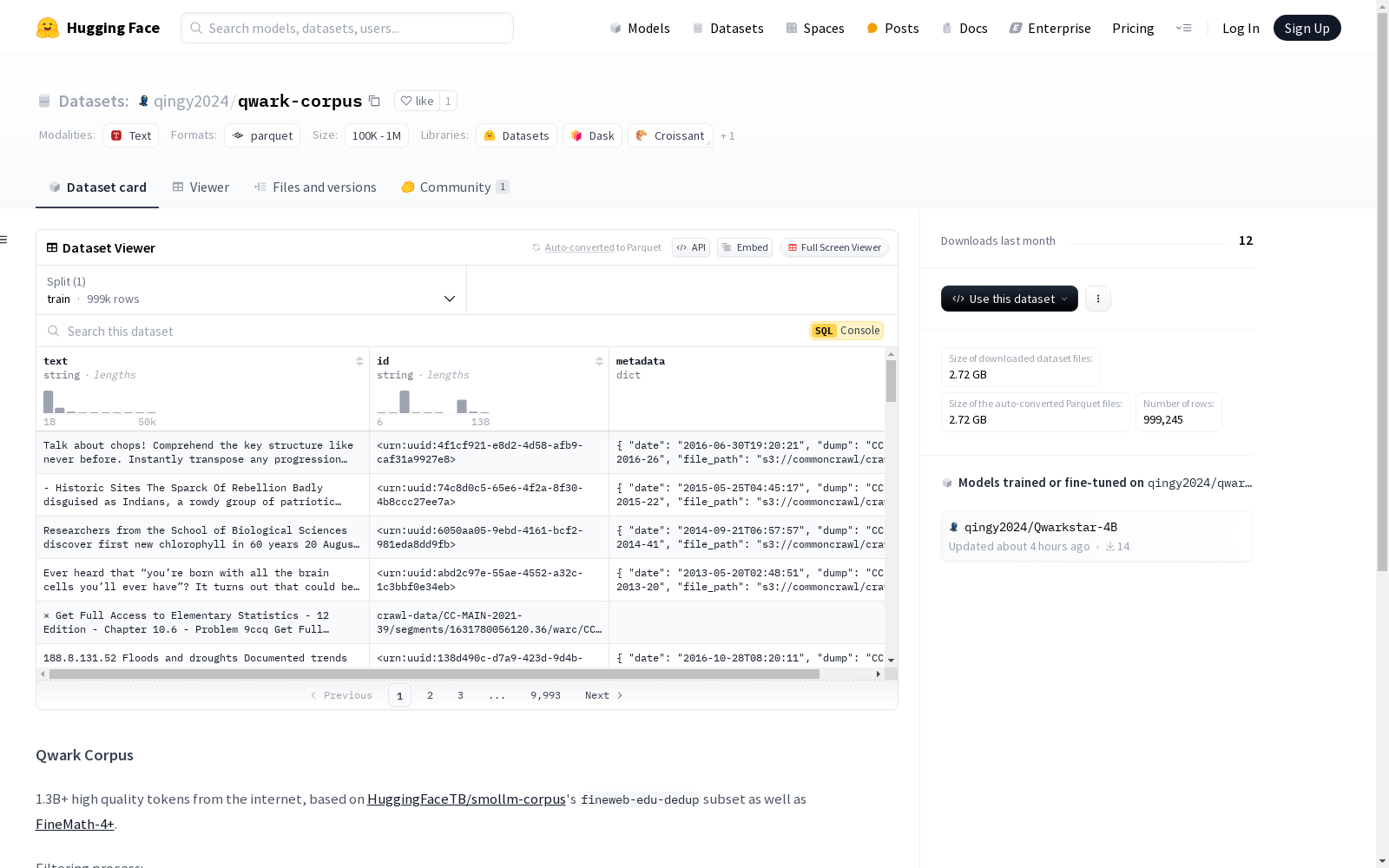
Qwark Corpus是一个包含超过13亿高质量互联网文本的数据集,基于HuggingFaceTB/smollm-corpus的fineweb-edu-dedup子集和FineMath-4+数据集构建。数据集经过多步过滤,包括选择高质量样本、移除过长的文本、添加TED演讲文本等步骤,最终包含999,245个样本,总大小为5.29GB。数据集的特征包括文本、ID和元数据,元数据中包括日期、文件路径、语言、分数等多个字段。
The Qwark Corpus is a dataset comprising over 1.3 billion high-quality Internet texts, built upon the fineweb-edu-dedup subset of the HuggingFaceTB/smollm-corpus and the FineMath-4+ dataset. The dataset undergoes multi-stage filtering procedures, including selecting high-quality samples, removing excessively long texts, and incorporating TED talk transcripts, alongside other processing steps. The finalized dataset contains 999,245 samples with a total size of 5.29 GB. The dataset features three core fields: text, ID, and metadata, where the metadata includes multiple attributes such as date, file path, language, and score.
创建时间:
2025-01-05
搜集汇总
数据集介绍
构建方式
qwark-corpus数据集的构建过程经过精心设计,以确保数据的高质量和多样性。首先,从HuggingFaceTB/smollm-corpus的fineweb-edu-dedup子集中筛选出评分不低于3.5的600,000个样本。接着,剔除长度超过50,000字符的条目,确保数据的可管理性。随后,数据集进一步丰富了4,000个TED演讲的转录文本,增强了教育内容的覆盖。最后,从FineMath-4+数据集中选取评分不低于4.0的400,000个样本,并再次过滤掉过长的条目,最终形成了包含999,245个样本的高质量数据集。
特点
qwark-corpus数据集的特点在于其广泛的内容覆盖和严格的质量控制。数据集不仅包含了来自互联网的高质量文本,还特别引入了TED演讲的转录文本,增强了教育内容的深度和广度。每个样本都附有详细的元数据,包括发布日期、来源文件路径、语言评分、分数和词数等信息,为研究者提供了丰富的上下文信息。此外,数据集通过多轮筛选和过滤,确保了文本的长度和质量,使其适用于多种自然语言处理任务。
使用方法
qwark-corpus数据集的使用方法灵活多样,适用于多种自然语言处理任务。研究者可以通过Hugging Face平台轻松下载数据集,并利用其提供的train分割进行模型训练。数据集中的每个样本都包含文本内容和丰富的元数据,用户可以根据需要选择特定的元数据字段进行筛选和分析。例如,可以根据语言评分或词数过滤数据,以适配不同的研究需求。此外,数据集的结构化设计使得其易于集成到现有的机器学习框架中,支持从文本分类到语言模型训练等多种应用场景。
背景与挑战
背景概述
Qwark Corpus数据集是一个包含超过13亿高质量互联网文本标记的语料库,旨在为自然语言处理(NLP)领域提供丰富的训练数据。该数据集基于HuggingFaceTB的smollm-corpus中的fineweb-edu-dedup子集以及FineMath-4+数据集构建而成。Qwark Corpus的创建时间不详,但其核心研究问题在于如何通过严格的过滤和筛选机制,确保数据的高质量和多样性,从而为语言模型的训练提供可靠的基础。该数据集在NLP领域的影响力主要体现在其广泛的应用场景,如机器翻译、文本生成和情感分析等。
当前挑战
Qwark Corpus在构建过程中面临多重挑战。首先,数据筛选的标准极为严格,要求文本的评分必须达到一定阈值(如SmolLM Corpus中的3.5分和FineMath-4+中的4.0分),这增加了数据获取的难度。其次,文本长度的限制(不超过50,000字符)进一步缩小了可用数据的范围。此外,数据来源的多样性也是一个挑战,尽管数据集整合了TED演讲等教育类文本,但仍需确保不同来源数据的兼容性和一致性。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练效果提出了更高的要求。
常用场景
经典使用场景
Qwark Corpus数据集广泛应用于自然语言处理领域,特别是在语言模型的预训练和微调过程中。该数据集通过整合高质量的网络文本和教育资源,如TED演讲文稿,为研究人员提供了丰富的语言素材。其经典使用场景包括但不限于文本生成、机器翻译以及情感分析等任务。通过其多样化的文本来源和严格的质量筛选,Qwark Corpus为语言模型的训练提供了坚实的基础。
衍生相关工作
Qwark Corpus的发布催生了一系列相关研究和技术创新。基于该数据集,研究人员开发了多个先进的语言模型,如多语言翻译系统和文本生成工具。此外,该数据集还被用于探索跨领域文本分析的新方法,如结合数学文本和普通语言文本的混合模型。这些衍生工作不仅拓展了自然语言处理的研究边界,还为未来的技术发展提供了新的思路和工具。
数据集最近研究
最新研究方向
在自然语言处理领域,qwark-corpus数据集以其高质量的语言数据和丰富的元信息特征,为大规模语言模型的训练和评估提供了重要支持。该数据集结合了来自互联网的多样化文本资源,包括教育类TED演讲文稿和数学相关的高质量内容,进一步增强了其在教育技术领域的应用潜力。近年来,研究者们利用该数据集探索了多语言模型的跨语言迁移能力、文本生成质量评估以及语言模型在特定领域(如数学教育)的适应性。这些研究不仅推动了语言模型在复杂任务中的表现提升,也为教育技术的智能化发展提供了新的数据基础。
以上内容由遇见数据集搜集并总结生成


