allenai-c4|自然语言处理数据集|数据预训练数据集
收藏huggingface2025-06-04 更新2025-06-05 收录
下载链接:
https://huggingface.co/datasets/amanpreet7/allenai-c4
下载链接
链接失效反馈资源简介:
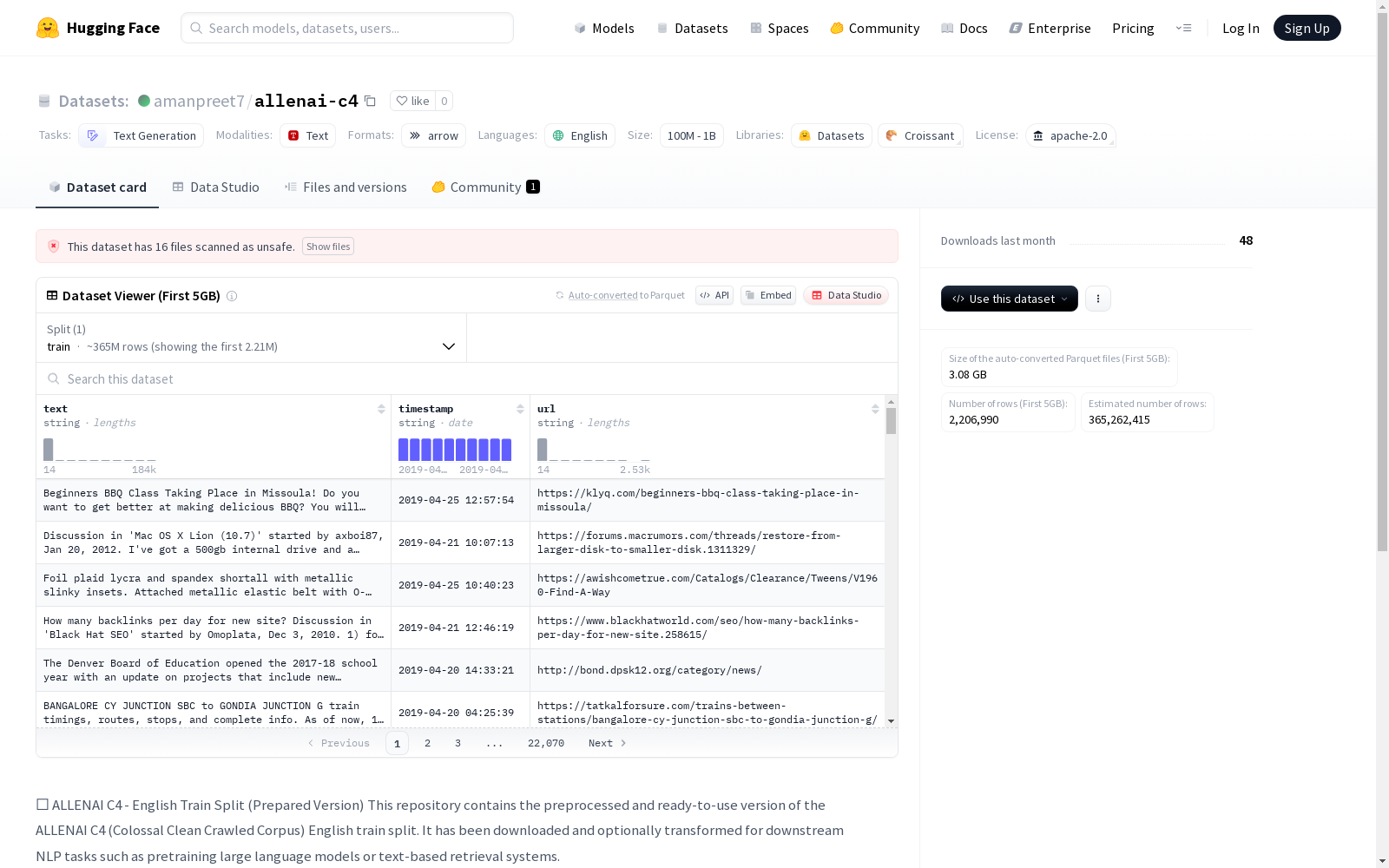
ALLENAI C4英文训练集预处理版本,包含约3.65亿个样本,适用于NLP任务的预训练,如大型语言模型或文本检索系统,存储格式为Arrow,总大小约为881GB。
创建时间:
2025-05-24
原始信息汇总
ALLENAI C4 - English Train Split (Prepared Version) 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 文本生成 (text-generation)
- 语言: 英语 (en)
- 规模分类: 100M<n<1B
数据集详情
- 原始来源: allenai/c4
- 语言: 英语 (en)
- 数据分割: 训练集 (train)
- 许可证: Google C4 License
- 预处理: 已预处理并存储为本地格式(如Apache Arrow或Parquet格式)
规模信息
- 样本数量: 约3.65亿
- 存储格式: Arrow
- 磁盘总大小: 约881GB
AI搜集汇总
数据集介绍
构建方式
ALLENAI C4数据集作为自然语言处理领域的重要语料库,其构建过程体现了大规模数据采集与清洗的前沿方法。该数据集源自网络公开文本的自动化爬取,通过多级过滤系统去除低质量内容,保留符合标准的英文文本。原始数据经过分布式计算框架处理,采用语义去重技术确保文本多样性,最终形成结构化的训练集分区。预处理阶段将原始文本转化为高效的列式存储格式,显著提升了后续访问效率。
特点
该数据集最显著的特征在于其规模与质量的平衡,包含约3.65亿条经过严格筛选的英文文本样本。存储采用Apache Arrow列式格式,在保持原始语言丰富性的同时实现了881GB海量数据的高效存取。作为专为预训练设计的语料库,其文本覆盖领域广泛且保留自然语言复杂性,特别适合需要深层语义理解的任务。数据经过标准化处理但未过度清洗,完整保留了真实网络文本的语言特征和分布模式。
使用方法
研究人员可直接加载预处理完成的Arrow格式文件,快速集成到现有机器学习管道中。该数据集主要服务于大规模语言模型预训练场景,建议配合分布式训练框架使用以应对数据规模挑战。使用前应充分了解其网络文本特性,针对特定任务可能需要进行额外的领域适配处理。数据分片存储的设计允许按需加载部分数据集,为资源受限的研究环境提供了灵活性。
背景与挑战
背景概述
ALLENAI C4(Colossal Clean Crawled Corpus)是由艾伦人工智能研究所(Allen Institute for AI)于2020年推出的一个大规模英文文本数据集,旨在为自然语言处理(NLP)领域的研究提供高质量的预训练数据。该数据集的构建基于Common Crawl的海量网页数据,经过严格的清洗和过滤,确保了文本内容的纯净性和可用性。C4数据集的核心研究问题在于如何从嘈杂的网络文本中提取高质量的语料,以支持大规模语言模型的预训练。其影响力不仅体现在推动了BERT、T5等模型的性能提升,还为后续研究提供了标准化的数据基准。
当前挑战
ALLENAI C4数据集在解决领域问题时面临的主要挑战包括网络文本的噪声过滤、内容多样性的平衡以及数据规模的合理裁剪。网络文本中充斥着大量无关信息、重复内容和低质量语言,如何高效清洗这些噪声成为关键。构建过程中的挑战则集中在数据清洗管道的设计,包括去除低质量文本、标准化格式以及处理多语言混杂问题。此外,数据集的存储和分发也因规模庞大而面临技术难题,如何在保证数据完整性的同时优化存储效率成为亟待解决的问题。
常用场景
经典使用场景
在自然语言处理领域,allenai-c4数据集作为大规模预训练语料库的标杆,其经典使用场景主要集中于语言模型的预训练阶段。该数据集通过提供经过严格清洗的365亿个英语文本样本,为GPT、BERT等Transformer架构模型提供了高质量的上下文学习素材,特别是在零样本和小样本学习场景中展现出卓越的文本表征能力。研究人员常将其作为基准数据集,用于评估模型在词汇覆盖、长程依赖建模等方面的性能。
实际应用
工业界将allenai-c4广泛应用于智能客服、机器翻译等实际场景。微软团队利用其训练出的Turing-NLG模型在文档摘要任务中达到人类水平,而Google的T5框架则基于该数据集实现了多任务统一建模。教育科技公司特别青睐其干净的语料特性,用于开发语法纠错系统,显著降低了人工标注成本。
衍生相关工作
该数据集催生了多个里程碑式研究,包括EleutherAI提出的数据去偏方法Pile,以及BigScience团队基于其构建的多语言版本mC4。斯坦福大学的CRFM研究中心利用该数据集开发了数据影响评估框架,而DeepMind的Chinchilla模型则通过对其采样策略的优化,重新定义了训练数据与模型规模的最佳配比关系。
以上内容由AI搜集并总结生成


